CUDA编程指南2.0:多核处理器的并行编程
"CUDA编程指南2.0"
CUDA编程指南是NVIDIA公司发布的一份详细文档,旨在介绍CUDA(Compute Unified Device Architecture)编程模型,该模型允许程序员利用GPU(图形处理单元)进行并行计算,从而大幅提升计算性能。CUDA 2.0版本是在2008年6月7日发布的。
**章节1:介绍**
1.1 CUDA:可扩展的并行编程模型
CUDA提供了一个灵活的编程框架,使得开发者能够利用GPU的并行计算能力来解决计算密集型问题。它不仅限于图形处理,还可以应用于科学计算、数据分析等领域。
1.2 GPU:高度并行、多线程的多核处理器
GPU被设计为执行大规模并行计算任务,具有大量的流处理器核心,能够同时处理大量数据,非常适合于执行重复性的计算任务。
1.3 文档结构
该文档分为多个章节,详细介绍了CUDA编程的基础概念、编程模型、GPU实现和应用程序接口等。
**章节2:编程模型**
2.1 线程层次
CUDA的并行计算是通过线程层次结构实现的,包括线程块、线程网格以及更细粒度的线程。
2.2 内存层次
CUDA内存层次包括全局内存、共享内存、常量内存和纹理内存,它们有不同的访问速度和用途,开发者需要根据需求选择合适的内存类型。
2.3 主机与设备
CUDA程序运行在主机(CPU)和设备(GPU)上。主机负责管理和调度,设备则执行计算任务。数据需要在两者之间进行迁移。
2.4 软件栈
CUDA软件栈包括编译器、库、驱动程序和开发工具,支持开发者进行高效的GPU编程。
2.5 计算能力
每个CUDA兼容的GPU都有特定的计算能力,这决定了它可以支持的CUDA特性级别和最高运算性能。
**章节3:GPU实现**
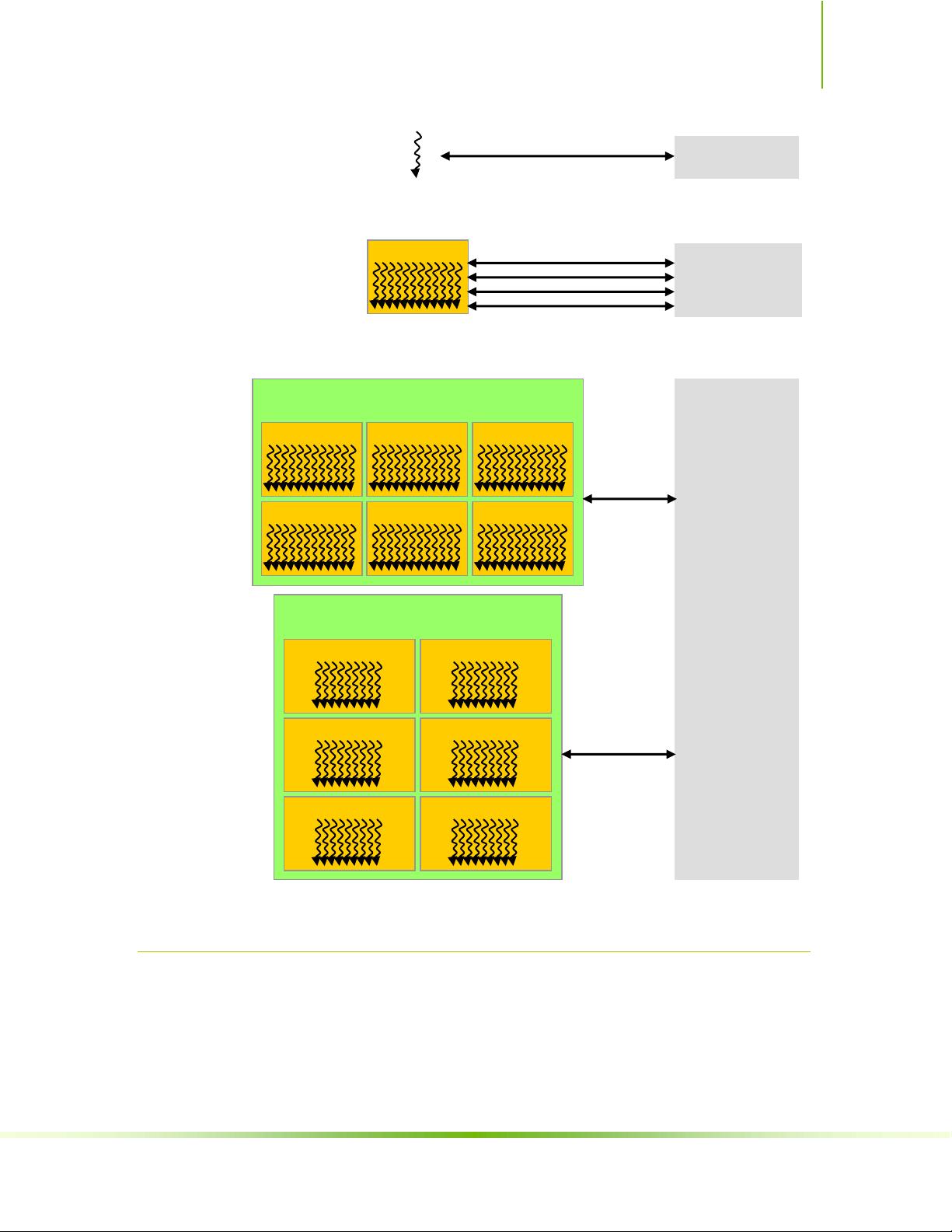
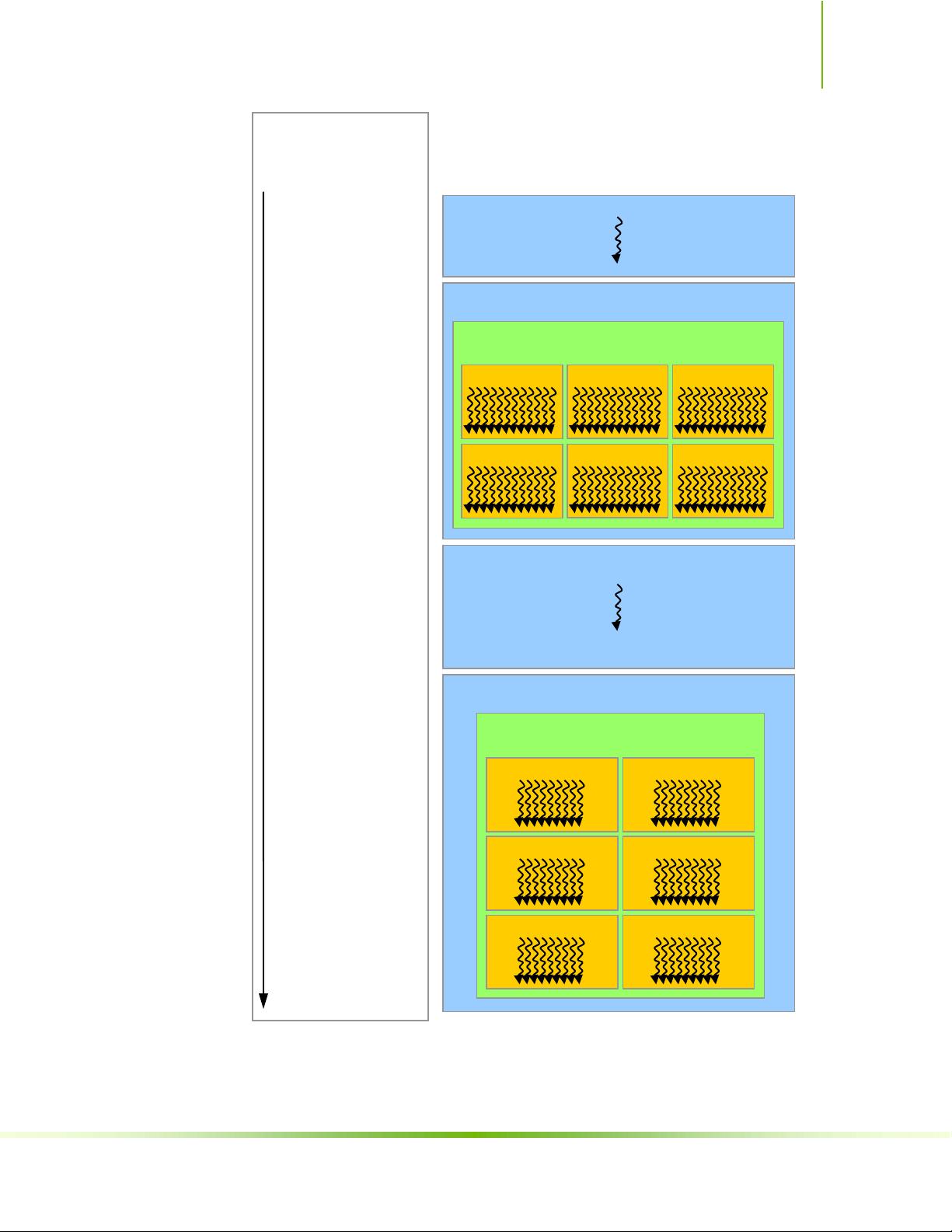
3.1 集成了片上共享内存的SIMT多处理器
GPU由多个单指令多线程(SIMT)多处理器组成,每个多处理器有自身的共享内存,用于加速线程间的通信。
3.2 多个设备
系统可能包含多个CUDA兼容的GPU,可以同时或独立工作,提供了扩展并行计算能力的可能性。
3.3 模式切换
GPU可以在不同的模式下运行,如GPU计算模式和图形渲染模式,根据应用的需求动态切换。
**章节4:应用程序编程接口**
4.1 C编程语言的扩展
CUDA API基于C语言,为C程序员提供了直接控制GPU的手段。
4.2 语言扩展
包括函数类型限定符和变量类型限定符,如`__device__`、`__global__`、`__host__`、`__constant__`和`__shared__`,它们定义了函数和变量的行为和存储位置。
4.2.1 函数类型限定符
`__device__`、`__global__`和`__host__`分别表示函数在设备、全局和主机上执行。
- `__device__`函数在GPU上执行。
- `__global__`函数在GPU上执行,可以被主机调用。
- `__host__`函数仅在主机上执行。
4.2.2 变量类型限定符
- `__device__`变量存储在设备内存中。
- `__constant__`变量存储在常量内存中,对所有线程是可见的。
- `__shared__`变量存储在共享内存中,仅对同一线程块内的线程可见。
4.2.3 执行配置
CUDA程序可以通过这些限定符指定线程的执行方式,如线程块的尺寸和数量。
综上,CUDA编程指南2.0为开发者提供了全面的指导,涵盖了从基本概念到高级API的各个方面,是学习和使用CUDA进行并行计算的重要参考资料。
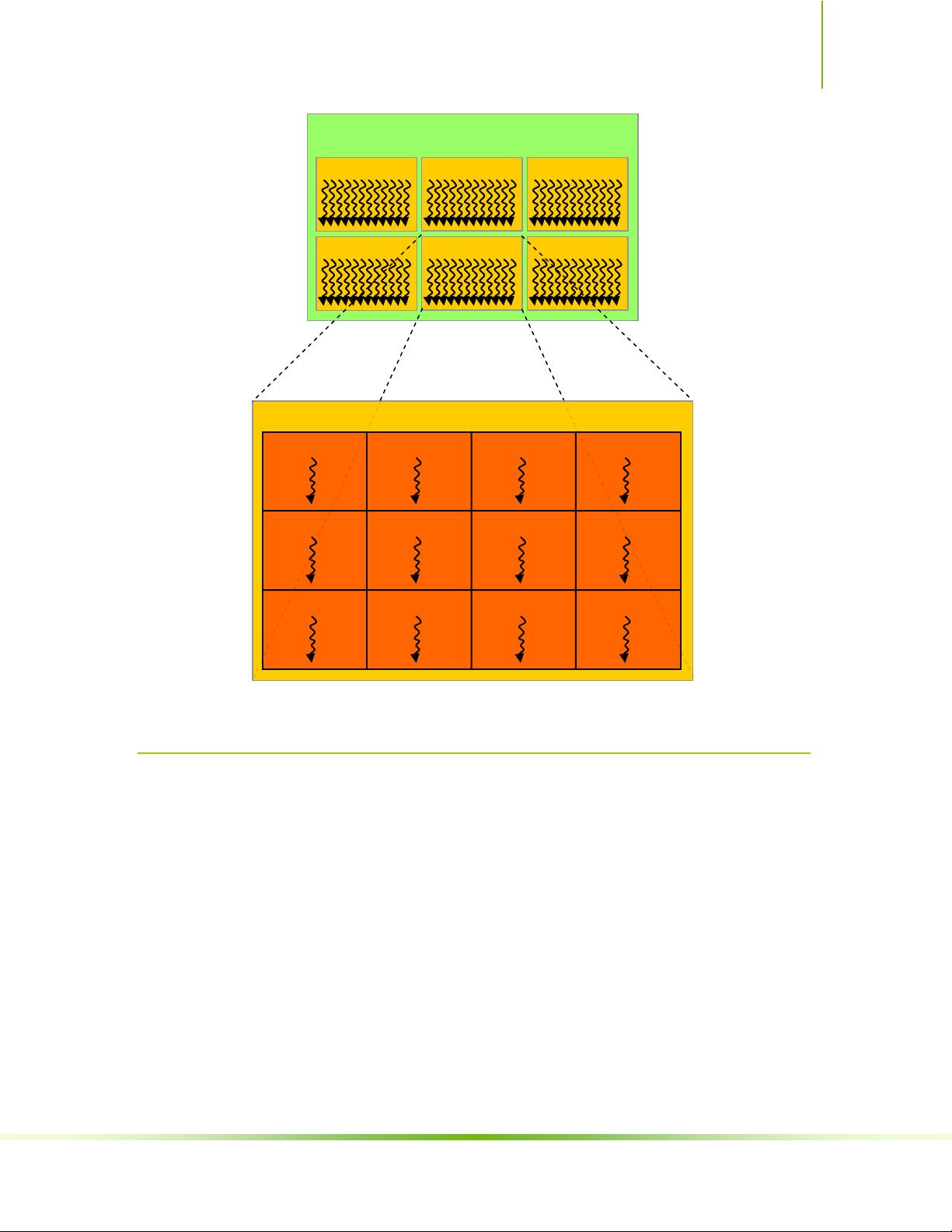
Chapter 3. Hardware Implementation
8 CUDA Programming Guide Version 2.0
Figure 2-1. Grid of Thread Blocks
2.2 Memory Hierarchy
CUDA threads may access data from multiple memory spaces during their
execution as illustrated by Figure 2-2. Each thread has a private local
memory. Each
thread block has a shared memory visible to all threads of the block and with the
same lifetime as the block. Finally, all threads have access to the same global
memory.
There are also two additional read-only memory spaces accessible by all threads: the
constant and texture memory spaces. The global, constant, and texture memory
spaces are optimized for different memory usages (see Sections 5.1.2.1, 5.1.2.3, and
5.1.2.4). Texture memory also offers different addressing modes, as well as data
filteri
ng, for some specific data formats (see Section 4.3.4).
Th
e global, constant, and texture memory spaces are persistent across kernel
launches by the same application.
Grid
Block (1, 1)
Thread (0, 0) Thread (1, 0) Thread (2, 0) Thread (3, 0)
Thread (0, 1) Thread (1, 1) Thread (2, 1) Thread (3, 1)
Thread (0, 2) Thread (1, 2) Thread (2, 2) Thread (3, 2)
Bloc
k
(2, 1)Bloc
k
(1
,
1)Bloc
k
(0
,
1)
Bloc
k
(2, 0)Bloc
k
(1
,
0)Bloc
k
(0
,
0)


剩余106页未读,继续阅读
2009-09-17 上传
2023-05-22 上传
2024-01-27 上传
2023-10-01 上传
2023-11-10 上传
2023-03-16 上传
2023-09-15 上传

miloliu
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
