分布式存储与计算:CAP理论与Nosql解析
51 浏览量
更新于2024-08-28
收藏 240KB PDF 举报
"本文主要探讨了海量数据下分布式存储与计算的相关概念,特别是涉及CAP理论、ACID原则以及BASE原则,以及NoSQL数据库中的数据模型和实现方式。"
在面对海量数据时,分布式存储和计算成为了必要的解决方案。分布式存储允许我们将大量数据分散在多个节点上,以提高存储能力和处理效率。而计算的分布式则通过并行处理来加速任务的完成,尤其适合大数据分析和实时计算场景。
CAP理论是分布式系统设计中的基础理论,它涵盖了数据一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。在传统的数据库系统中,如关系型数据库,往往追求强一致性和高可用性,但这样的设计在分布式环境中可能会导致性能瓶颈。NoSQL和云存储通常选择牺牲强一致性,以换取更高的可用性和分区容错性,这就是BASE原则(Basically Available, Soft State, Eventually Consistent)的体现。BASE强调在分布式系统中,基本可用、软状态和最终一致性是更为实际的选择。
ACID是事务处理的重要原则,包括原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。原子性确保事务要么全部完成,要么全部不完成;一致性保证事务前后数据状态的合法性;隔离性使并发事务之间互不干扰;持久性则是事务一旦提交,其结果将永久保存。这些原则在关系型数据库中得到了广泛应用。
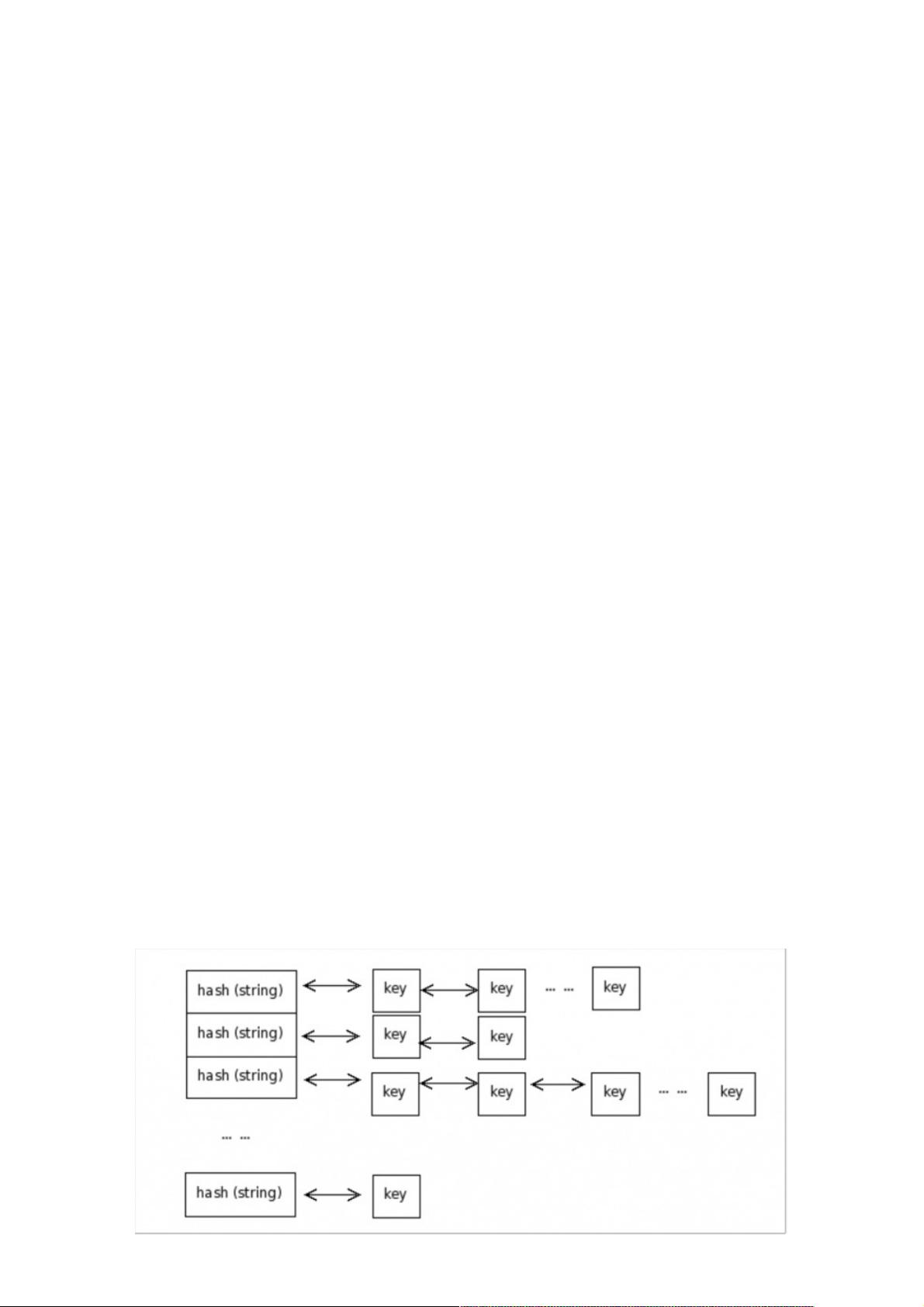
NoSQL数据库,如MongoDB和HBase,提供了不同的数据模型来适应分布式环境。MongoDB采用键值对(key-value)模型,而HBase则采用自由列表模式,类似于关系型数据库的结构。在实现这些模型时,常见的方法有哈希加链表或B+树。哈希加链表通过哈希函数确定存储位置,相同哈希值的数据形成链表,而B+树则提供了一种高效的数据索引方式。
海量数据下的分布式存储与计算涉及到众多复杂的技术和理念,如CAP、ACID和BASE原则,以及NoSQL的数据模型和存储策略。理解这些概念对于设计和优化大规模分布式系统至关重要。
海量数据下的分布式存储与计算海量数据下的分布式存储与计算
存储
从理论角度
提到大数据存储nosql是不得不提的一个部分,CAP,BASE,ACID这些原理在过去的一些年对其有着一定的指导作用(近年来
随着各种实时计算模型的发展,CAP也被渐渐打破)
CAP:(Consistency-Availability-Partition Tolerance
数据一致性(C): 等同于所有节点访问同一份最新的数据副本;
对数据更新具备高可用性(A): 在可写的时候可读, 可读的时候可写,最少的停工时间
能容忍网络分区(P)
eg:
传统数据库一般采用CA即强一致性和高可用性
nosql,云存储等一般采用降低一致性的代价来获得另外2个因素
ACID:按照CAP分法ACID是许多CA型关系数据库多采用的原则:
A:Atomicity原子性,事务作为最小单位,要么不执行要么完全执行
C:Consistency一致性,一个事务把一个对象从一个合法状态转到另一个合法状态,如果交易失败,把对象恢复到前一个合
法状态。即在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
I:Isolation独立性(隔离性),事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
D:Durability:事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
BASE:一般是通过牺牲强一致性,来换取可用性和分布式
BA:Basically Aavilable基本可用:允许偶尔的失败,只要保证绝大多数情况下系统可用
S:Soft State软状态:无连接?无状态?
E:Eventual Consistency最终一致性:要求数据在一定的时间内达到一致性
以云存储为例:目前的云存储多以整体上采用BASE局部采用ACID,由于使用分布式使用多备份所以多采用最终一致性
Nosql常见的数据模型有key/value和Schema Free(自由列表模式)两种,
key/value,每条记录由2个域组成,一个作为主键,一个存储记录的数据(mongodb)
Schema Free, 每条记录有一个主键,若干条列组成,有点类似关系型数据库(hbase)
在实现这些模型的时候基本使用2种实现方式:哈希加链表,或者B+树的方式
哈希加链表:通过将key进行哈希来确定存储位置,相同哈希值的数据存储成链表
下载后可阅读完整内容,剩余5页未读,立即下载
2021-08-09 上传
2022-03-18 上传
2021-08-11 上传
2021-08-11 上传
2021-08-10 上传
2024-05-24 上传
2022-10-21 上传
2021-12-08 上传
2024-05-27 上传

weixin_38645379
- 粉丝: 7
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
