"GPU显存支持MiB分配在Kubernetes中的问题及解决方案"
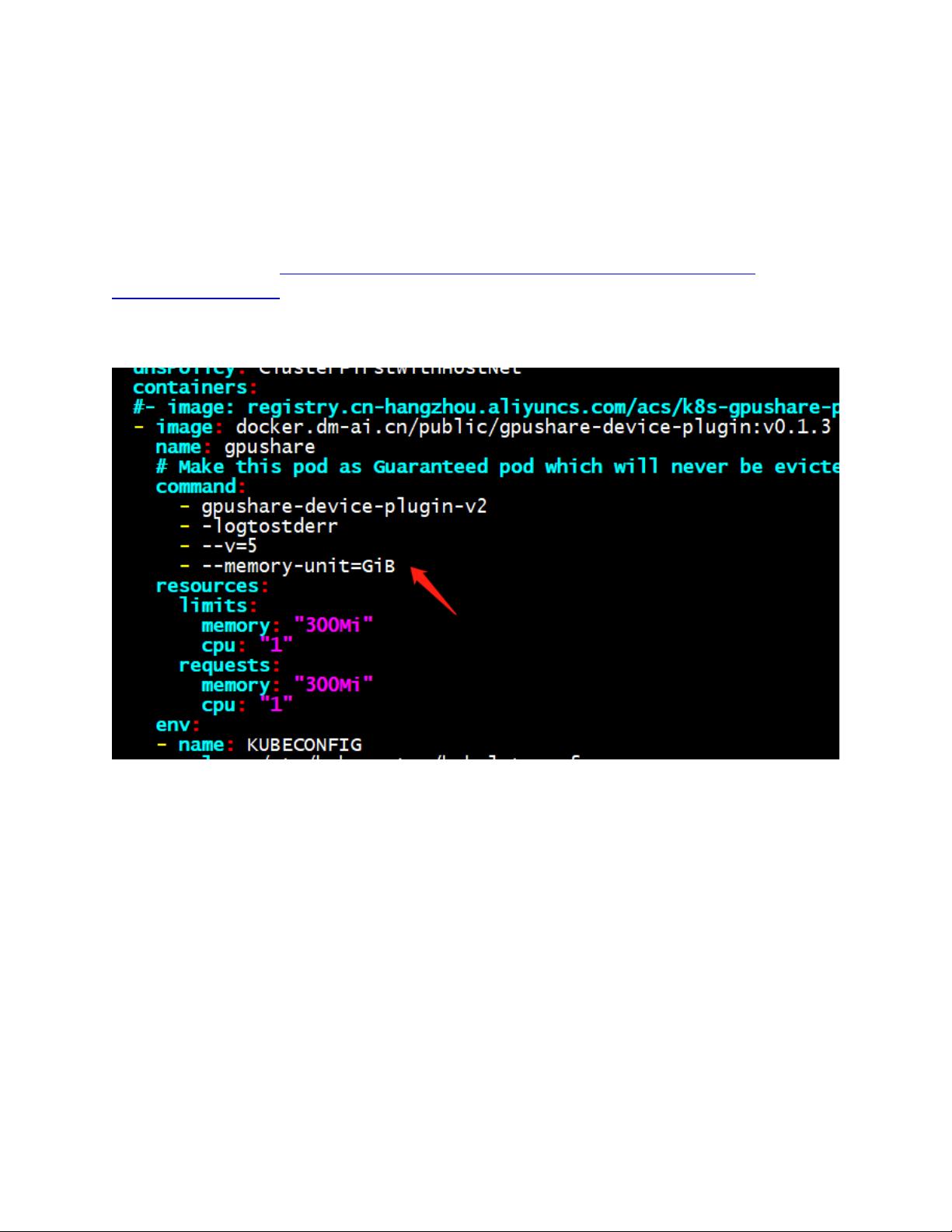
在Kubernetes环境中,GPU资源的管理对于运行高性能计算任务至关重要。在阿里云的插件——Gpushare-Scheduler-Extender(https://github.com/AliyunContainerService/gpushare-scheduler-extender)中,原本显存的分配是以GiB为单位进行的。然而,在尝试将显存单位从GiB改为MiB后,遇到了兼容性问题,导致系统无法识别GPU,进而触发kubelet的错误。
错误信息表明,由于GRPC协议的限制,接收到的消息大小超过了最大值4MiB。GRPC是一种高效的开源通用RPC框架,它在传输数据时有固定的报文大小限制,超过这个限制会导致通信失败。在这个场景中,当显存请求从GiB转换为MiB时,由于MiB的数量级比GiB多,使得请求的显存资源信息超过了GRPC的最大报文大小。
为了解决这个问题,需要对Kubernetes的kubelet组件进行源码级别的调整。具体而言,需要在`pkg/kubelet/cm/device_manager/endpoint.go`文件的`dial`方法中,增加一个参数以增大GRPC的最大接收消息大小。这可以通过设置`grpc.WithDefaultCallOptions(grpc.MaxCallRecvMsgSize(1024*1024*16))`来实现,将最大接收消息大小提升到16MiB,从而能容纳更大的显存分配信息。
完成代码修改后,需要重新编译kubelet。在Kubernetes源码目录下执行`make WHAT=cmd/kubelet`命令,这会生成新的kubelet二进制文件,通常位于`_output/bin/kubelet`路径下。接着,用新编译的kubelet二进制文件替换现有的kubelet服务,并重启kubelet以应用更改。
完成上述步骤后,系统应该能够正确处理以MiB为单位的GPU显存请求。通过检查GPU的状态,可以验证问题是否已得到解决。这表明,当涉及到资源管理的微调时,可能需要对Kubernetes的核心组件进行定制化,以适应特定的需求和限制。
这个案例展示了在Kubernetes中处理非标准资源单位时可能遇到的问题以及如何通过修改源码和自定义组件来克服这些挑战。在实际操作中,确保对系统组件进行适当调整并理解其潜在影响是非常重要的。同时,关注社区的更新和最佳实践,可以有效地避免或解决类似的问题。


 我的内容管理
展开
我的内容管理
展开









