Apache Flink入门:大数据实时处理框架解析
需积分: 10 185 浏览量
更新于2024-06-30
收藏 3.24MB PDF 举报
"这篇文档是关于大数据处理框架Apache Flink的详细介绍,涵盖了Flink的起源、设计理念、核心特点,以及流处理与批处理的区别。"
Apache Flink是源自Stratosphere项目的一个开源流处理框架,它在2014年成为Apache软件基金会的顶级项目。Flink的设计理念强调分布式、高性能、高可用性和准确性,特别适合处理无界和有界数据流,并能在各种集群环境中以内存计算速度运行。
Flink的重要特点包括事件驱动型(Event-driven)架构,这种架构允许应用根据事件触发计算和状态更新。与Spark Streaming的微批次处理不同,Flink支持真正的事件驱动,能及时响应事件的发生。
另一个关键特性是Flink对流与批处理的统一世界观。Flink将批处理视为有界流,而流处理则是无界流。这意味着Flink可以无缝地处理实时和历史数据,无需区分处理模式。无界数据流代表了持续不断的数据流,而有界数据流则表示有限且最终会停止的数据集合,通常用于离线分析。
在Flink的处理模型中,它可以对流中的每个数据项进行即时操作,实现低延迟的实时计算。相比之下,Spark Streaming通过将实时数据划分为一系列小批次来进行处理,牺牲了部分实时性以换取简化计算的复杂性。
此外,Flink提供了状态管理能力,允许应用存储和更新中间计算结果,这对于处理有状态的事件驱动应用至关重要。这使得Flink在处理复杂的实时分析任务时,能够保持一致性和精确性。
在实际应用中,Flink常用于实时数据处理场景,如在线分析、实时监控、复杂事件处理等,以及需要高吞吐量、低延迟和精确一次(Exactly-once)语义的场景。Flink的API简洁易用,支持Java和Scala,也有Python API供数据科学家和非Java开发者使用。
总结来说,Flink是一个强大的流处理框架,它的设计理念和特性使其在大数据实时处理领域具有显著优势,能够满足各种实时计算需求,无论是在大规模数据处理还是实时分析中都表现出色。对于希望深入了解和使用Flink的开发者而言,这份文档是宝贵的参考资料,涵盖了从基础到高级的众多知识点。
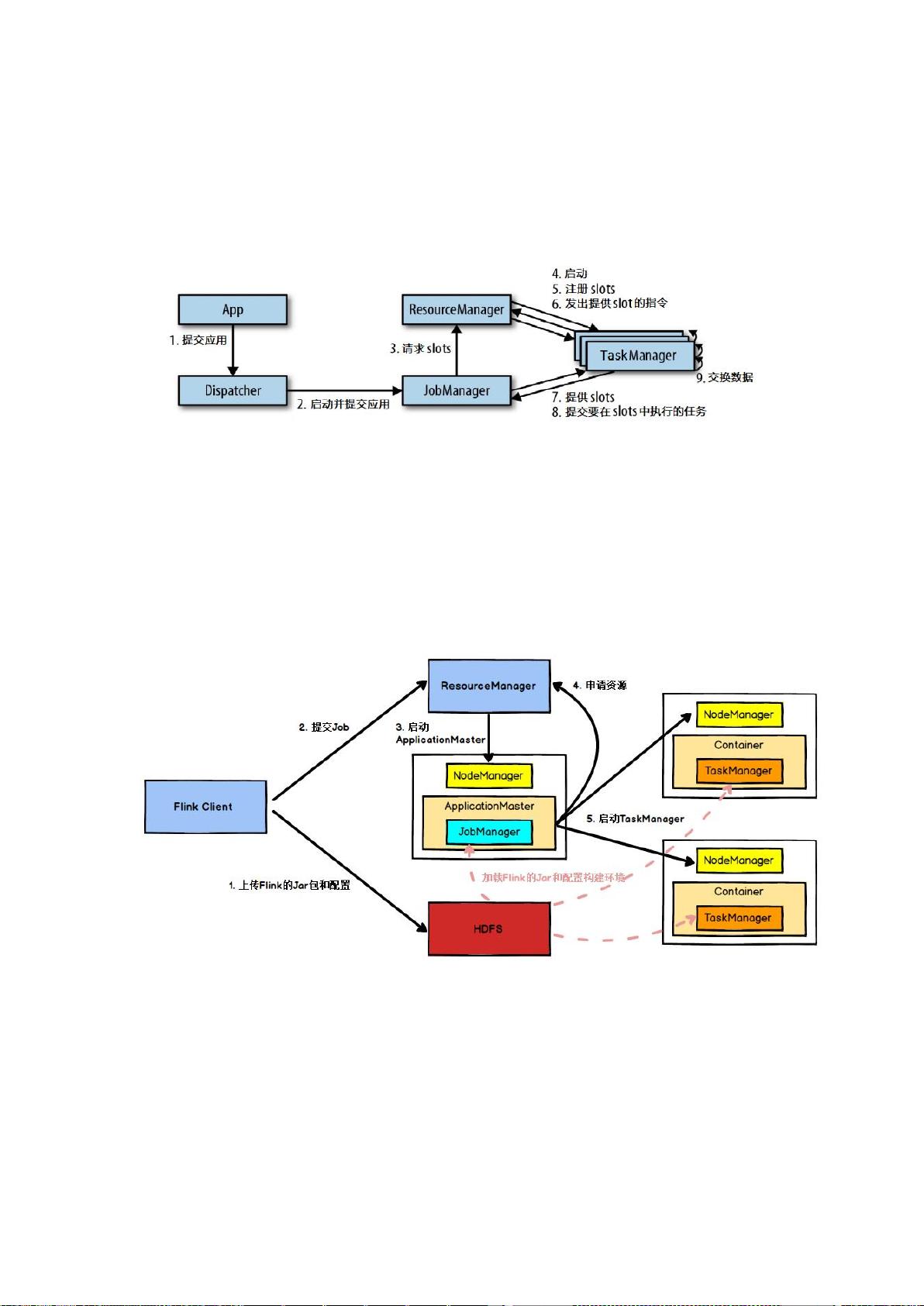
4.2 任务提交流程
我们来看看当一个应用提交执行时,Flink 的各个组件是如何交互协作的:
图 任务提交和组件交互流程
上图是从一个较为高层级的视角,来看应用中各组件的交互协作。如果部署的集群环境
不同(例如 YARN,Mesos,Kubernetes,standalone 等),其中一些步骤可以被省略,或是
有些组件会运行在同一个 JVM 进程中。
具体地,如果我们将
Flink
集群部署到
YARN
上,那么就会有如下的提交流程:
图 Yarn 模式任务提交流程
Flink 任 务 提 交 后 , Client 向 HDFS 上 传 Flink 的 Jar 包 和 配 置 , 之 后 向 Yarn
ResourceManager 提 交 任 务 , ResourceManager 分 配 Container 资 源 并 通 知 对 应 的
NodeManager 启动 ApplicationMaster,ApplicationMaster 启 动 后加载 Flink 的 Jar 包
和配置构建环境,然后启动 JobManager,之后 ApplicationMaster 向 ResourceManager
申 请 资 源 启 动 TaskManager , ResourceManager 分 配 Container 资 源 后 , 由
ApplicationMaster 通 知 资 源 所 在 节 点 的 NodeManager 启 动 TaskManager ,
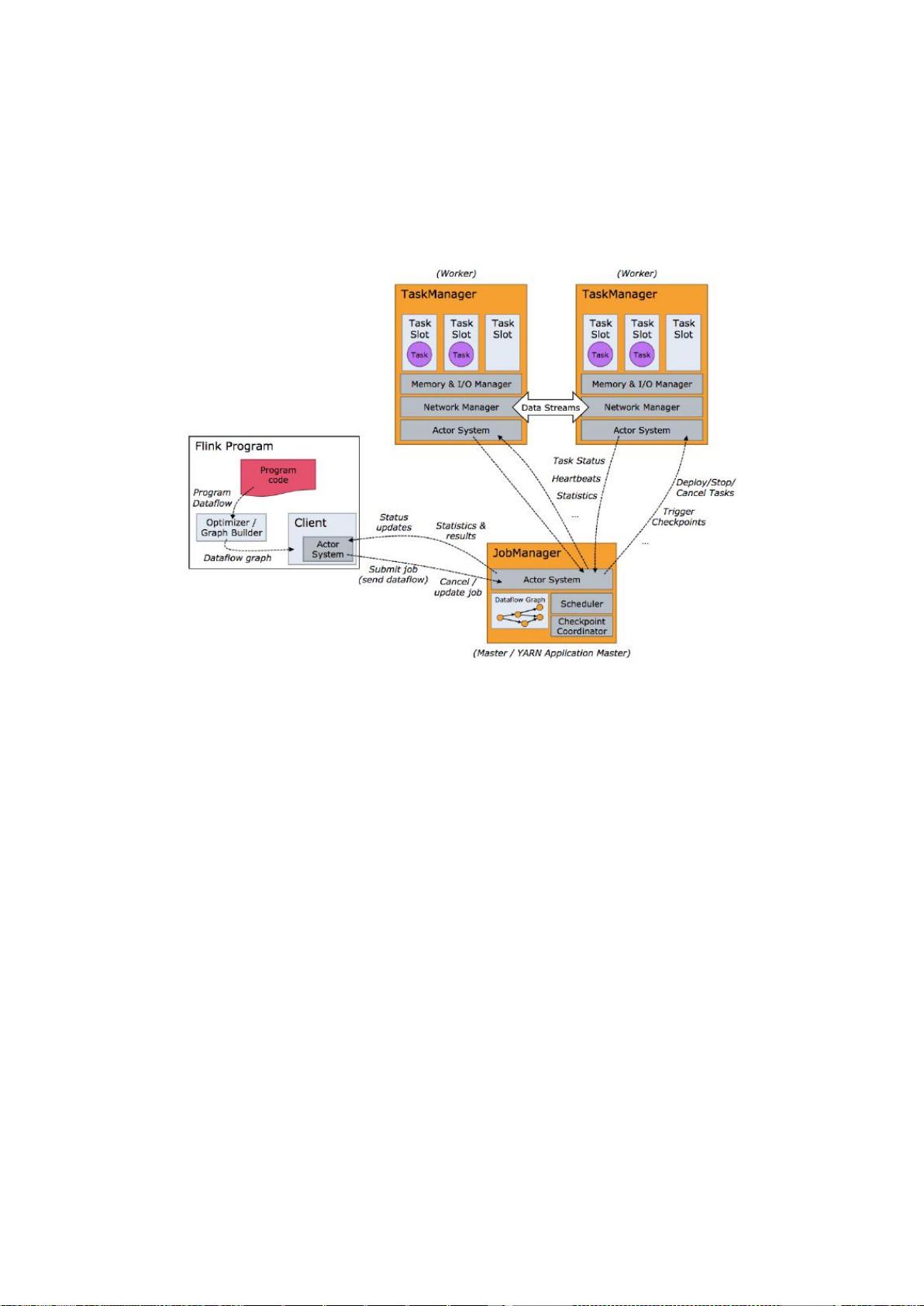
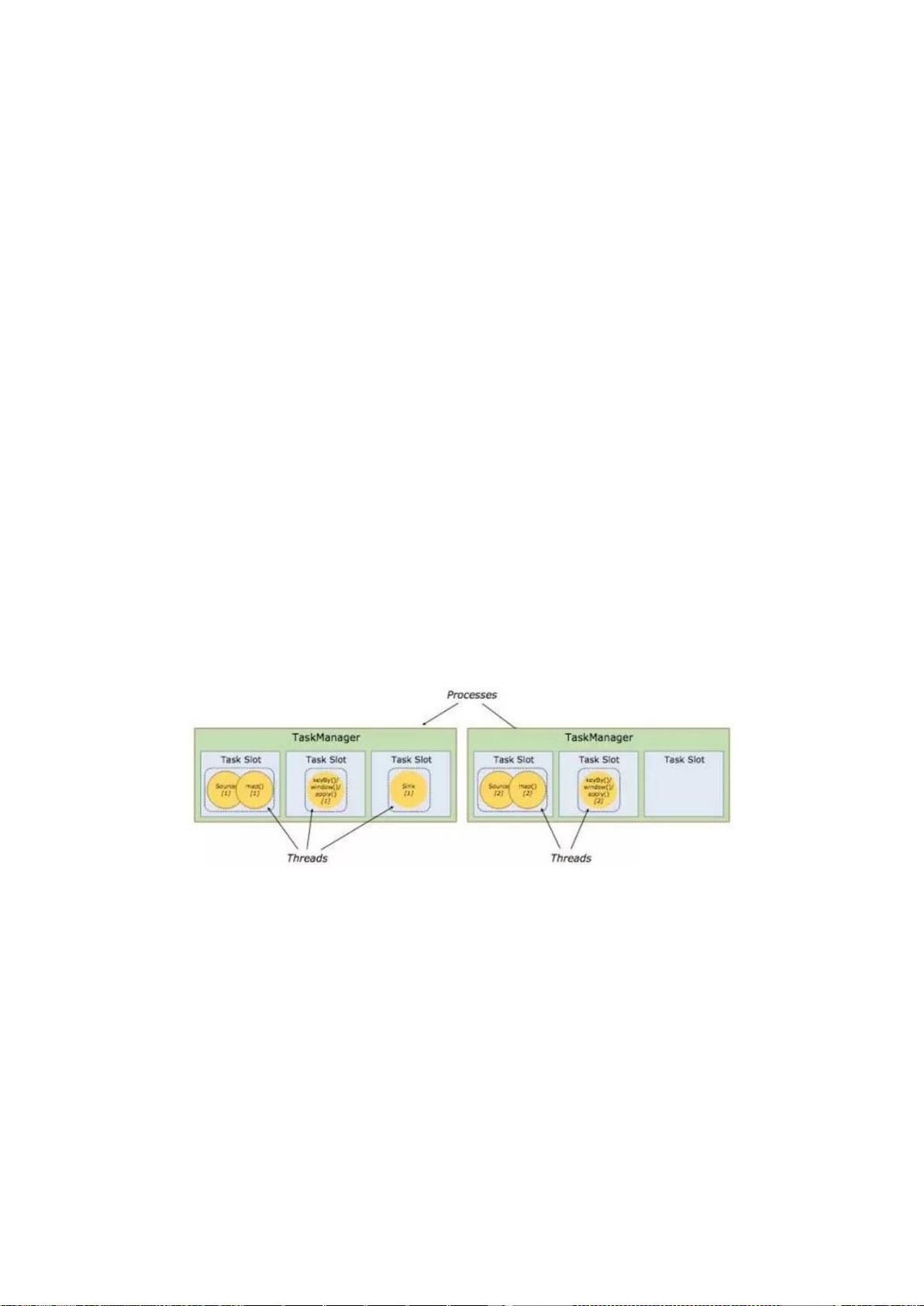
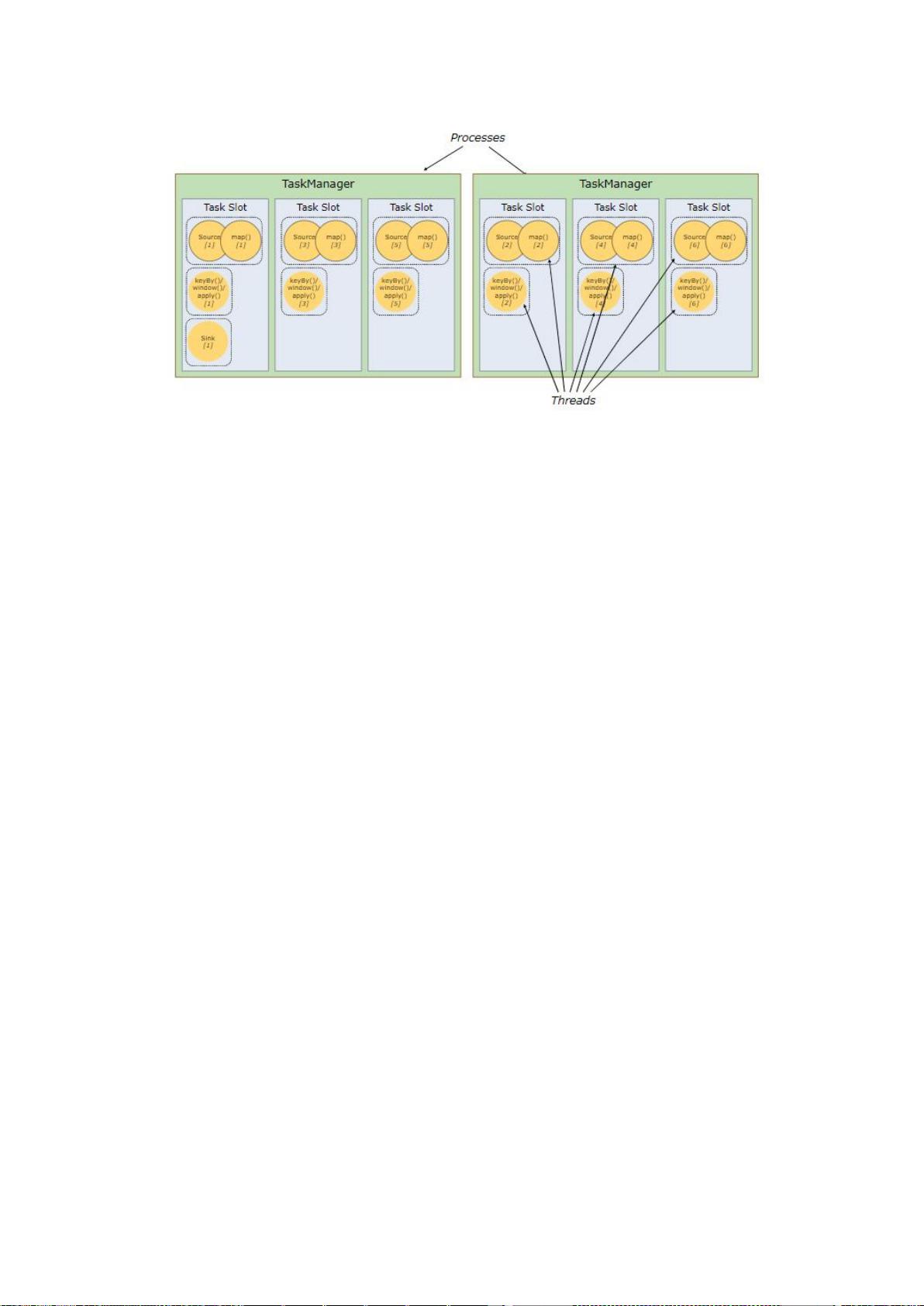
剩余99页未读,继续阅读
2019-11-20 上传
2022-12-24 上传
2022-06-21 上传
2021-12-10 上传
2022-12-16 上传
2022-04-29 上传
2021-07-15 上传

没工作的小白
- 粉丝: 33
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 程序靠边自动隐藏窗口-易语言
- Pipo:用于从Firebase提取数据并显示的Android项目
- school_project
- flutter_google_ml_vision:适用于Google ML Kit Vision的Flutter插件
- codeandsewn.github.io
- CheckHealth.github.io
- 林森塔
- Happy-Holi
- Prog2_Reseau:Prog2 Java LP SIL的小型项目Vianey Benjamin-Bodet Cindy
- c# 锁屏系统
- hackgt21-whispermom:HackGT'21的临时仓库
- 网址:霓虹灯线
- Webpack_PW_Anul_2
- 能否上网-易语言
- nonogram:基于遗传算法的非图求解器
- 控制
