优化阈值与分类器以最大化F1分数
需积分: 9 18 浏览量
更新于2024-07-19
收藏 515KB PDF 举报
"这篇论文探讨了在二分类和多标签分类任务中如何通过调整阈值最大化F1分数。F1分数是评估罕见类别分类性能的常用指标,它是由精确率和召回率的调和平均值构成。在多标签分类中,有微平均、宏平均和每个实例平均的F1分数。作者揭示了对于任何产生实值输出的分类器,最佳F1分数与实现这一最优值的决策阈值之间的关系。特别地,如果分类器输出的是良好的条件概率,那么最优阈值是最佳F1分数的一半。另一方面,如果分类器完全没有信息性,最优策略是将所有样本都分类为正类。实际正例的流行率通常会影响最佳阈值的选择。"
本文深入研究了如何优化二元分类和多标签分类中的F1分数,这是衡量分类器性能的重要指标,尤其是在处理不平衡数据集时。F1分数综合考虑了精确率(Precision)和召回率(Recall),对于稀有类别的识别尤其关键。在多标签分类中,可以使用不同类型的平均F1分数来评估模型性能,包括微平均(Micro-average)、宏平均(Macro-average)和每个实例平均(Per-instance average)。
论文提出,对于任何给出连续输出的分类器,存在一个最佳的阈值,使得F1分数达到最大。这个阈值的选择依赖于分类器的输出特性。例如,如果分类器能够输出准确的条件概率,即输出值代表样本属于正类的概率,那么最佳阈值是最佳F1分数的一半。这种情况下,通过调整阈值,可以在保持精确率和召回率之间平衡,从而最大化F1分数。
另一方面,如果分类器没有提供任何有用信息,即其输出与真实类别无关,那么最佳策略是将所有样本都预测为正类,这会得到100%的召回率,但精确率可能很低,具体取决于数据集中正例的比例。实际上,真实场景中正例的分布(即阳性样本的预估比例)会显著影响最佳阈值的选取,因为选择阈值的目标是最大化F1分数,而F1分数是对精确率和召回率的综合权衡。
该论文为优化分类器性能提供了理论基础,指导了在面对不同情况时如何选择合适的阈值,以提高模型对罕见或不平衡类别的识别能力。这对于开发和评估实际应用中的机器学习模型具有重要意义。
4 Zachary C. Lipton, Charles Elkan, and Balakrishnan Naryanaswamy
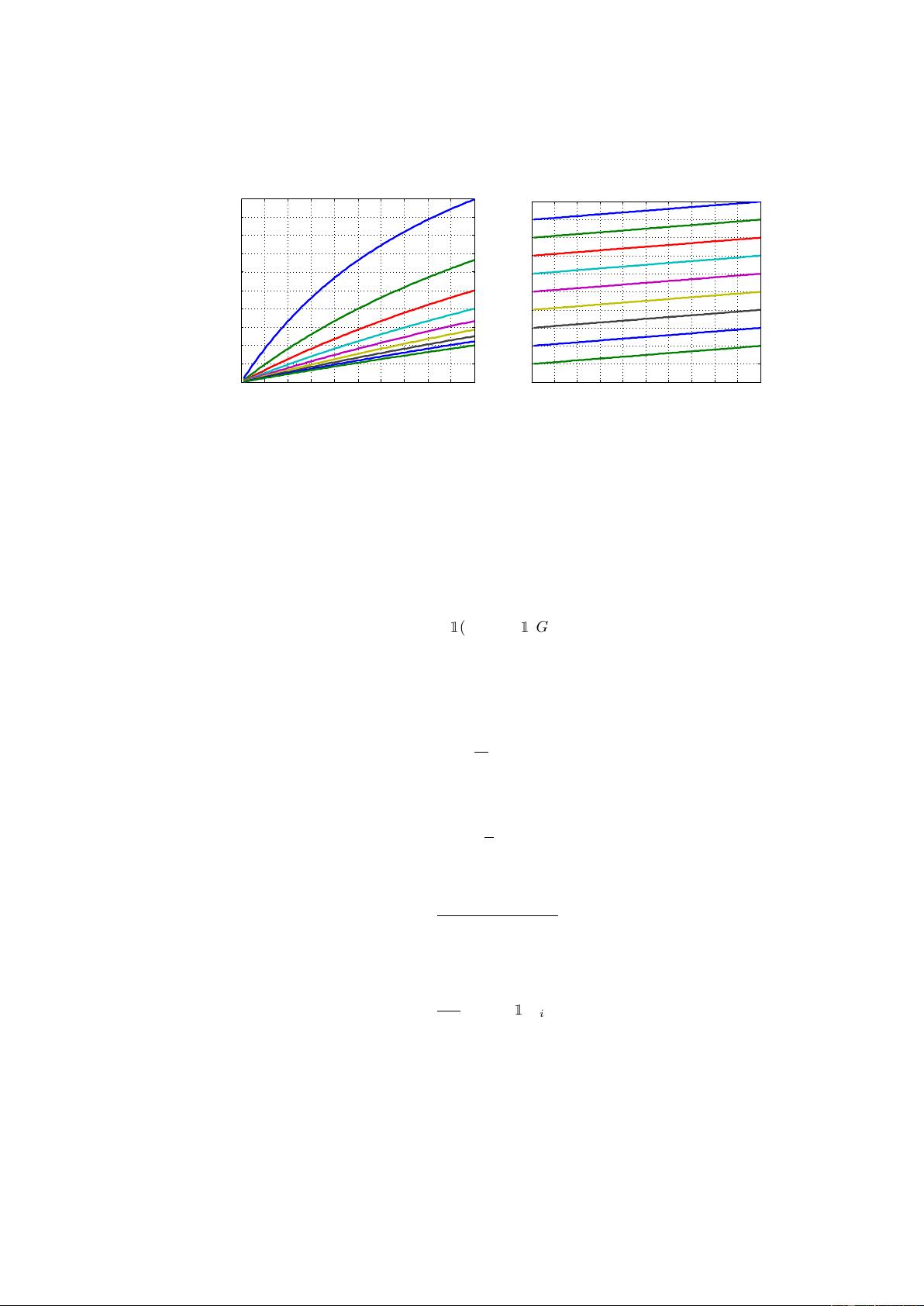
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
True Positive
F1 score
Base Rate of 0.1
Fig. 2: Holding base rate and fp con-
stant, F1 is concave in tp. Each line
is a different value of fp.
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
True Positive
Accuracy
Base Rate of 0.1
Fig. 3: Unlike F1, accuracy offers lin-
early increasing returns. Each line is
a fixed value of fp.
2.2 Multilabel Performance Measures
While F1 was developed for single-label information retrieval, as mentioned there
are variants of F1 for the multilabel setting. Micro F1 treats all predictions on
all labels as one vector and then calculates the F1 score. In particular,
tp = 2
n
X
i=1
m
X
j=1
1
(P
ij
= 1)
1
(G
ij
= 1).
We define fp and fn analogously and calculate the final score using (1). Macro
F1, which can also be called per label F1, calculates the F1 for each of the m
labels and averages them:
F 1
Macro
(P |G) =
1
m
m
X
j=1
F 1(P
:j
, G
:j
).
Per instance F1 is similar but averages F1 over all n examples:
F 1
Instance
(P |G) =
1
n
n
X
i=1
F 1(P
i:
, G
i:
).
Accuracy is the fraction of all instances that are predicted correctly:
Acc =
tp + tn
tp + tn + f p + fn
.
Accuracy is adapted to the multilabel setting by summing tp and tn for all labels
and then dividing by the total number of predictions:
Acc(P |G) =
1
nm
n
X
i=1
m
X
j=1
1
(P
ij
= G
ij
).
剩余15页未读,继续阅读
2009-07-13 上传
2023-08-11 上传
2021-05-31 上传
2011-06-17 上传
2013-03-22 上传
2019-08-27 上传
135 浏览量
2015-08-14 上传
2009-08-15 上传


RoaringKitty
- 粉丝: 6w+
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
