机器学习实战:KNN算法的测试集与超参数优化
160 浏览量
更新于2024-08-29
收藏 710KB PDF 举报
在机器学习的“傻瓜式”理解中,第四个章节深入探讨了KNN算法的数据处理以及超参数的重要性。KNN(K-Nearest Neighbors)算法是一种基于实例的学习方法,其核心思想是根据新样本与训练集中已知样本的相似性来进行预测。然而,单纯依赖训练数据的准确性评估并不全面,因为真实环境中的表现才是关键。
数据处理是KNN应用的基础,为了评估模型在未见过的数据上的性能,我们会遵循训练集和测试集分离的原则。这个过程通常将数据集划分为两部分,80%的数据用于训练模型(训练集),剩下的20%用于验证模型的泛化能力(测试集)。这样可以确保模型在未知数据上的预测效果,减少过拟合的风险。通过`train_test_split`函数,我们可以方便地对数据进行划分,示例代码中展示了如何利用`numpy`库进行这一操作。
超参数是KNN中的关键要素,特别是`K`值。`K`决定了近邻的数量,影响了分类决策的依据。如果`K`值较小,模型会更关注样本的局部特征;如果`K`值较大,模型则倾向于整体的平均行为。例如,当`K=3`时,新点被归类为其最近的三个邻居中最常见类别的多数决定,这就涉及到了另一个超参数`weights`的选择。`weights`可以设置为“uniform”(等权重)或“distance”(按距离加权),这会影响分类时对邻居的影响程度。
在距离计算时,选择合适的距离度量也是一项重要的数据预处理工作。常见的距离度量有欧氏距离、曼哈顿距离和余弦相似度等。选择哪种度量取决于数据的特性和问题需求。
在KNN中调整超参数的过程通常通过交叉验证进行,如网格搜索或随机搜索,以找到最优的`K`值和其他可能的参数组合,从而提高模型在实际应用中的性能。这一步骤旨在优化模型,使其能够在真实环境中表现出最佳的预测效果。
总结来说,KNN算法中的数据处理包括划分训练集和测试集,以及合理选择距离度量。而超参数如`K`和`weights`则直接影响模型的决策策略和预测精度。理解并正确设置这些参数对于KNN算法的成功至关重要。在实际应用中,需要不断尝试和优化这些设置,以适应不同的数据集和任务需求。
机器学习机器学习“傻瓜式傻瓜式”理解(理解(4))KNN算法(数据处理以及超参数)算法(数据处理以及超参数)
数据处理以及超参数的理解数据处理以及超参数的理解
首先我们需要了解到,我们在进行机器学习的过程中寻求的不是让训练处的在现有的数据集上达到最佳,而是我们需要让其在真实环境中达到最佳的效果。在上一节中我们将全部的
数据集全部用于训练模型中,对于我们所训练出的模型无法知道其具体的准确度便投入真实环境使用,这样的做法极具风险性,而且我们也不推荐。
解决方案解决方案:机器学习最常用的解决方案便是实现测试集和训练集的相互分离(此方法仍具有局限性,后续会补充)。具体的操作方式是:将全部数据集的80%当做训练数据集,训练
出来模型后我们通过另外20%的数据(称其为测试数据集)来验证所训练出来模型的准确度。
实现代码封装:实现代码封装:
import numpy as np
def train_test_split(X,y,test_train = 0.2,seed = None):
'''check'''
assert X.shape[0] == y.shape[0],\
"the size must be valid"
assert 0.0 <= test_train <= 1.0,\
"the ratio must be in 0-1"
if seed:
np.random.seed(seed)
shuffle_index= np.random.permutation(len(X))
test_ratio = test_train
test_size = int(len(X) * test_ratio)
test_indexes = X[:test_size] train_indxes = X[test_size:]
X_train = X[train_indxes] X_test = X[test_indexes]
y_train = y[train_indxes] y_test = y[test_indexes]
return X_train,X_test,y_train,y_test
KNN中的超参数:中的超参数:
首先明确一个概念,何为超参数?我们需要在机器学习中传入的参数便是指的是超参数。KNN中的超参数便是K,这是KNN中我们需要关注的第一个超参数。
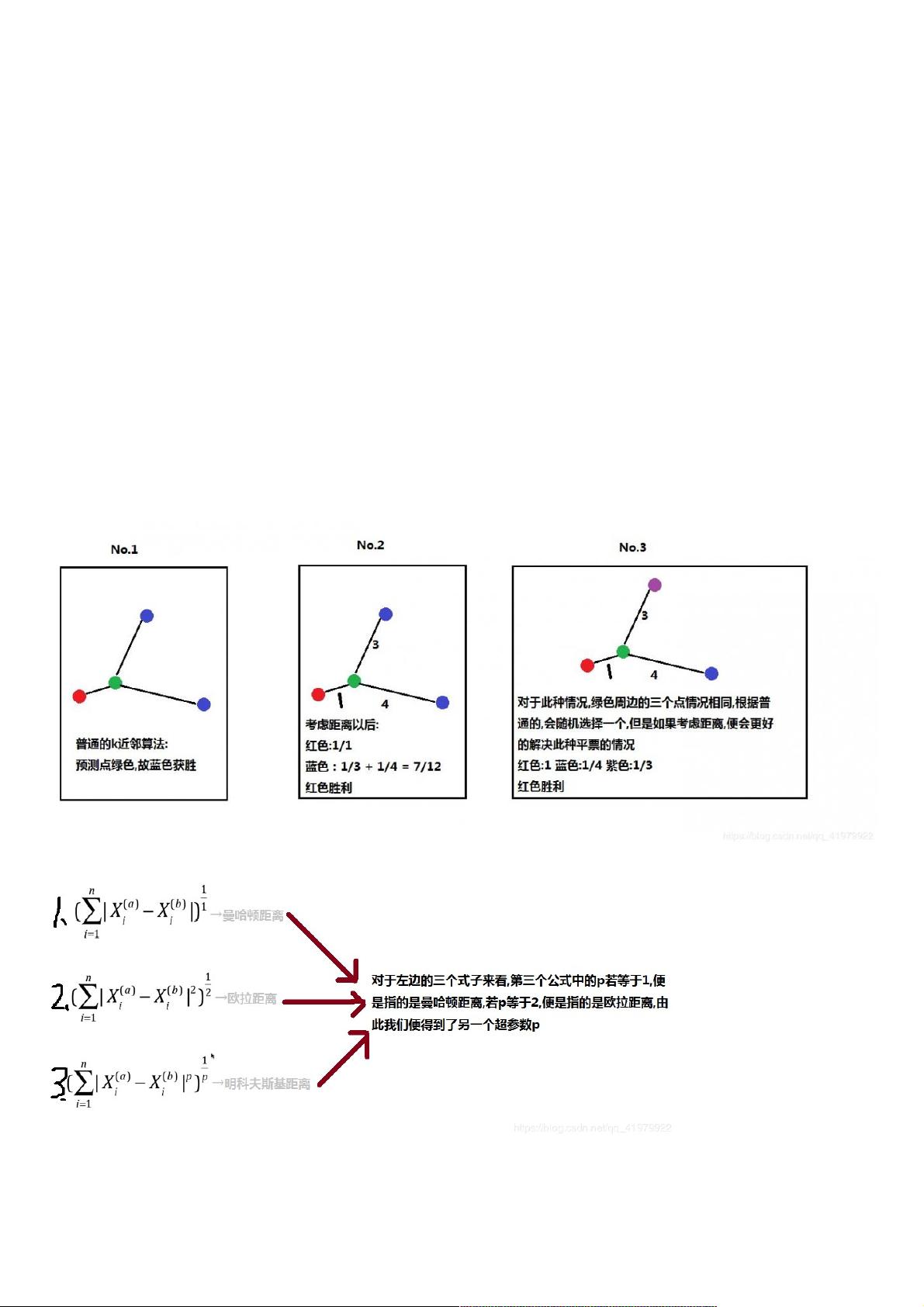
思考一个问题,加上K=3,距离最近的三个点之间的每个类别占1/3,我们如何确定是属于哪一个类别?如同下图所示:
如上我们便引出了第二个超参数weights.
另外,我们在计算预测点和我们数据点之间的距离时使用的是欧拉距离,但是观察下图后你会发现:
我们便得到了超参数p。
如何才能寻找到最好的超参数?如何才能寻找到最好的超参数?
有两个解决方案:
①我们可以采用经验数值,例如KNN算法中我们使用经验数值K=5,
②网格搜索策略寻找最优参数。
问题:何为最好的超参数?
我们需要一个评判标准,分类算法的评判标准便是模型准确度(accuracy)。
其实现代码如下:(在库中metrics中)
下载后可阅读完整内容,剩余3页未读,立即下载
2021-11-18 上传
2018-12-15 上传
2021-04-01 上传
2020-12-22 上传
2016-08-27 上传
2020-05-08 上传
2021-08-11 上传

weixin_38721252
- 粉丝: 5
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
