数据库设计:从第一范式到第四范式的实践解析
需积分: 9 70 浏览量
更新于2024-10-01
收藏 122KB DOCX 举报
"数据库设计需要遵循一系列的范式规则,以优化数据组织,减少冗余,消除异常。本文通过一个示例数据库表格,逐步展示如何从第一范式(1NF)到第二范式(2NF),再到第三范式(3NF)的过程。"
数据库设计中的范式规则是确保数据完整性、减少冗余和避免异常的关键概念。通常,满足前三范式(1NF、2NF、3NF)的数据库被认为是良好设计的。范式是一种标准化方法,其目标主要包括:
1. 减少数据冗余:这是最主要的好处,通过消除重复的数据,可以节省存储空间,提高查询效率,降低数据更新时的错误风险。
2. 消除异常:数据库中的异常包括插入异常、更新异常和删除异常。例如,当数据分布在多个表中时,不满足范式可能导致某些操作无法正常进行或产生不一致的结果。
3. 数据组织和谐:通过范式化,数据结构变得更加清晰,易于理解和维护。
让我们通过一个例子来看看如何实现这些范式:
原始表包含员工(Employee)、部门(Department)、岗位(Job)和技能(Skill)的信息,其中“Address”字段显然是可分的,不符合第一范式(1NF)。为了满足1NF,我们需要将地址字段分解成单独的表,如“EmployeeAddress”。
接下来,考虑第二范式(2NF),它要求非主属性完全依赖于整个主键。在原始表中,“departmentDescription”只依赖于“departmentName”,而不依赖于“employeeId”,这违反了2NF。因此,我们需要创建一个“Department”表,包含“departmentName”和“departmentDescription”,并与“Employee”表建立关联。
最后,第三范式(3NF)防止传递依赖,即非主属性不能依赖于其他非主属性。假设存在一个码“X”和属性组“Y”以及非主属性“Z”,若“X→Y”且“Y→Z”,则需拆分。在这个例子中,如果不存在这样的情况,那么当前设计已经满足3NF。
尽管满足高范式的设计可以提供许多优点,但也可能存在缺点,如增加查询复杂性,可能需要更多的联接操作来获取数据。因此,在实际应用中,数据库设计者需要根据性能需求、数据量和业务逻辑等因素权衡是否严格遵守更高范式。
数据库设计的范式规则是确保数据一致性、减少潜在问题的重要工具,但在实践中应根据具体场景灵活运用。通过理解并应用这些规则,可以构建出更稳定、高效的数据库系统。
简介
数据库范式在数据库设计中的地位一直很暧昧,教科书中对于数据库范式倒是都给出了学术
性的定义,但实际应用中范式的应用却不甚乐观,这篇文章会用简单的语言和一个简单的数据
库 DEMO 将一个不符合范式的数据库一步步从第一范式实现到第四范式。
范式的目标
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
1.减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
2.消除异常(插入异常,更新异常,删除异常)
3.让数据组织的更加和谐…
但剑是双刃的,应用数据库范式同样也会带来弊端,这会在文章后面说到。
什么是范式
简单的说,范式是为了消除重复数据减少冗余数据,从而让数据库内的数据更好的组织,让
磁盘空间得到更有效利用的一种标准化标准,满足高等级的范式的先决条件是满足低等级范式。
(比如满足 2nf 一定满足 1nf)
DEMO
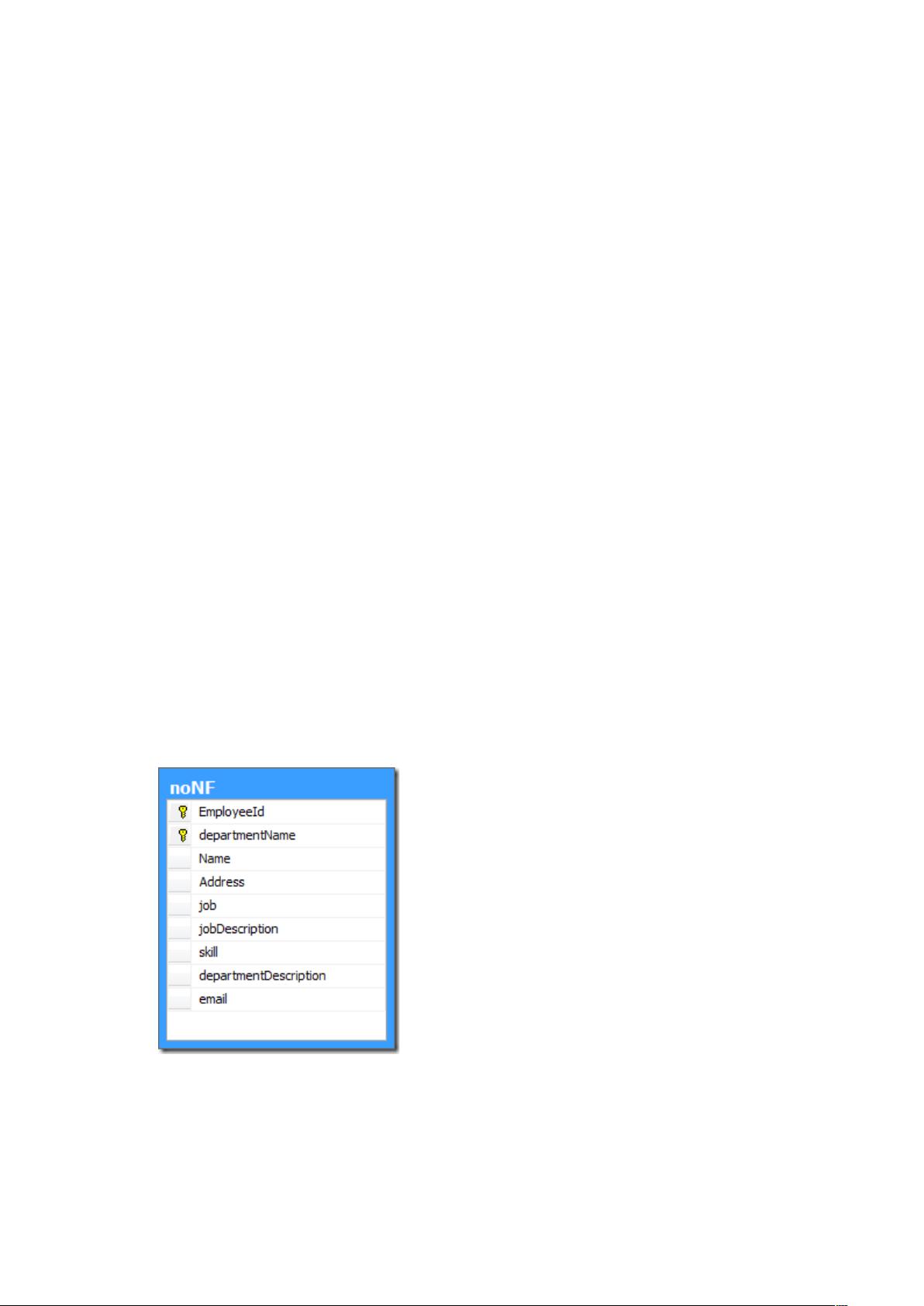
让我们先从一个未经范式化的表看起,表如下:
先对表做一个简单说明,employeeId 是员工 id,departmentName 是部门名称,job 代表
岗位,jobDescription 是岗位说明,skill 是员工技能,departmentDescription 是部门说明,
address 是员工住址
下载后可阅读完整内容,剩余8页未读,立即下载
2007-03-29 上传
2011-02-28 上传
2023-06-02 上传
2024-05-26 上传
2023-08-18 上传
2024-05-10 上传
2023-02-17 上传
2023-09-05 上传
2023-09-02 上传

yolandam
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- BGP协议首选值(PrefVal)属性与模拟组网实验
- C#实现VS***单元测试coverage文件转xml工具
- NX二次开发:UF_DRF_ask_weld_symbol函数详解与应用
- 从机FIFO的Verilog代码实现分析
- C语言制作键盘反应力训练游戏源代码
- 简约风格毕业论文答辩演示模板
- Qt6 QML教程:动态创建与销毁对象的示例源码解析
- NX二次开发函数介绍:UF_DRF_count_text_substring
- 获取inspect.exe:Windows桌面元素查看与自动化工具
- C语言开发的大丰收游戏源代码及论文完整展示
- 掌握NX二次开发:UF_DRF_create_3pt_cline_fbolt函数应用指南
- MobaXterm:超越Xshell的远程连接利器
- 创新手绘粉笔效果在毕业答辩中的应用
- 学生管理系统源码压缩包下载
- 深入解析NX二次开发函数UF-DRF-create-3pt-cline-fcir
- LabVIEW用户登录管理程序:注册、密码、登录与安全
