BERT原理解析:自然语言处理与Transformer网络
版权申诉
117 浏览量
更新于2024-07-04
1
收藏 1.91MB PDF 举报
该资源是一份关于自然语言处理(NLP)技术的详细讲解文档,主要聚焦于BERT(Bidirectional Encoder Representations from Transformers)模型的原理和应用。课程通过通俗易懂的方式讲解知识点,并结合项目实战,涵盖了从环境配置到模型应用的全过程。文档提供了谷歌开源项目的指导,包括所有必要的数据和代码,且会随着技术热点进行持续更新。
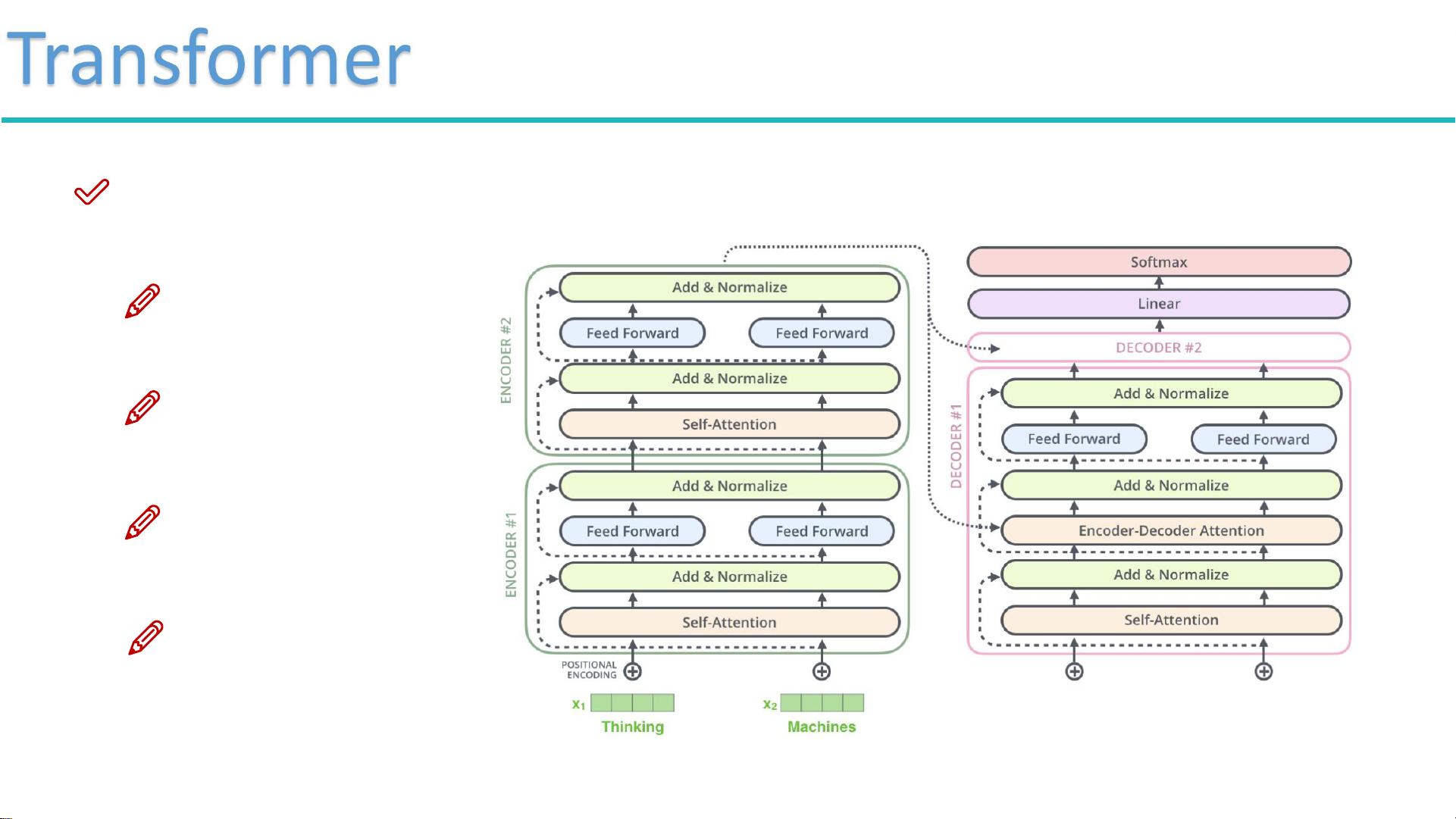
在NLP领域,通用解决方案通常涉及对word2vec和RNN(循环神经网络)的理解,以及如何构建词向量。文档的重点在于Transformer网络结构,这是BERT的基础,它通过自我注意力(Self-Attention)机制解决了RNN在并行计算上的限制。Transformer允许在同一时间处理输入序列的所有部分,显著提高了计算效率。BERT模型采用预训练的方法,可以方便地应用于各种基础任务,无需从头训练。
传统RNN在处理长序列时存在梯度消失或爆炸的问题,无法有效捕捉长距离依赖。而BERT通过Transformer中的Self-Attention机制,解决了这个问题。Self-Attention机制的核心是计算输入序列中各个元素之间的关联性,通过三个矩阵(Query、Key和Value)来实现。Query代表要查询的部分,Key表示等待被查询的元素,Value则是实际的特征信息。通过计算Query与Key的内积,可以得到匹配程度,经过softmax归一化,得到每个元素的权重,进而形成上下文相关的表示。
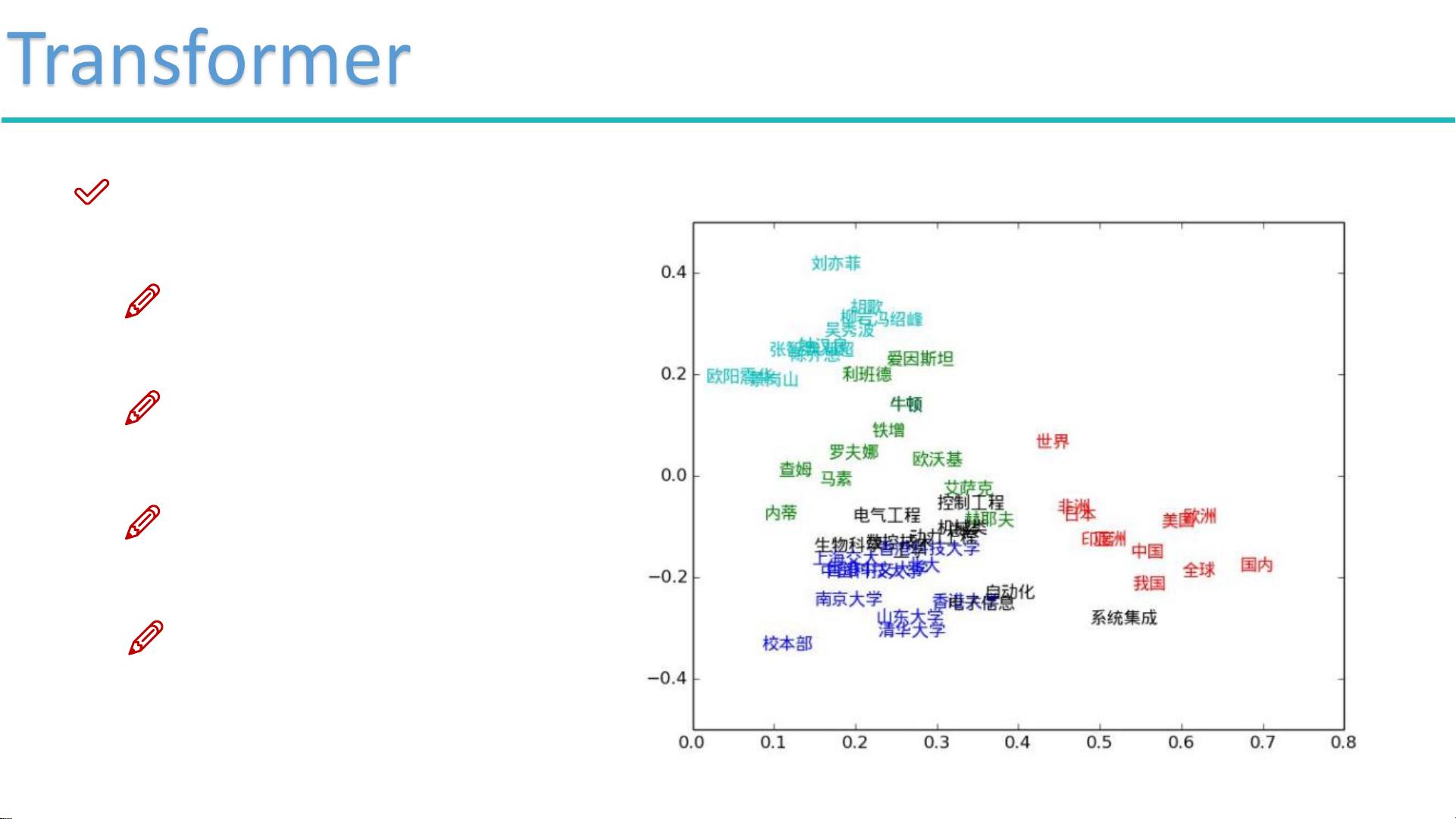
文档还深入介绍了Attention的概念,即在处理输入数据时,如何让计算机关注到关键信息。Self-Attention则是在不考虑顺序的情况下,计算当前元素与其他元素的关系,以获取全局的上下文信息。这种机制使得BERT能够在无序的文本序列中捕获丰富的语义信息,从而在各种NLP任务中展现出强大的性能,如问答系统、文本分类和情感分析等。
这份33页的PDF文档是一个全面介绍NLP技术,特别是BERT模型的教程,适合希望深入理解和应用自然语言处理技术的读者。通过学习,读者不仅可以掌握word2vec、RNN以及Transformer的基本概念,还能了解到最新的预训练模型BERT的实现细节和实际应用。
传统的word2vec
表示向量时有什么问题?
如果‘干哈那’是一个词
不同语境中相同的词如何表达
预训练好的向量就永久不变了
剩余32页未读,继续阅读

passionSnail
- 粉丝: 452
- 资源: 6944
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
