分层多线索建模:预测异构游客信息下的POI人气
90 浏览量
更新于2024-08-26
收藏 2.53MB PDF 举报
"具有异构游客信息的POI人气预测的分层多线索建模"
这篇研究论文探讨了在地点信息预测领域的一个重要问题——如何利用异构游客信息进行点兴趣(Point of Interest, POI)人气预测。POI人气预测在基于位置的服务中扮演着关键角色,比如用于POI推荐系统。当现有的方法由于POI信息稀缺而往往无法取得满意的效果时,这个问题显得尤为突出。这些方法通常将推荐范围限制在热门景点,而忽视了那些可能具有宝贵价值的不热门景点。
作者Yang Yang、Yaqian Duan、Xinze Wang、Zi Huang、Ning Xie以及Heng Tao Shen(均为IEEE成员)提出了一种新颖的层次多线索建模方法,旨在解决这一挑战。他们强调了利用不同类型的异构游客信息(如用户行为数据、社交网络互动、地理位置数据等)的潜力,这些信息可以提供更全面、更深入的洞察,帮助提高预测准确性。
文章的核心贡献在于开发了一个层次化的框架,该框架能够有效地整合和分析多种线索,包括但不限于:
1. **多层次线索集成**:论文中的“层次化”指的是对不同层面的游客信息进行建模,可能包括时间序列分析(如一天中的不同时间段、一周内的不同天数)、空间分布分析(POI之间的地理关系)和社会网络分析(用户的社交连接)。
2. **异构信息融合**:异构信息指的是不同类型的数据,如用户访问记录、评论文本、照片、评分等。通过有效的融合策略,这些信息可以相互补充,增强预测模型的鲁棒性。
3. **机器学习算法应用**:论文可能会介绍使用何种机器学习或深度学习技术来处理和学习这些多线索数据,如时间序列模型(如LSTM)、图神经网络(GNN)或协同过滤方法。
4. **性能评估与优化**:研究会通过实验验证所提方法的性能,并与其他现有方法进行对比,以证明其优越性。此外,可能会讨论参数调整和模型优化策略。
5. **案例研究**:论文可能会以实际的地理信息数据集为例,展示如何运用此方法进行POI人气预测,并分析预测结果的准确性和实用性。
通过这种创新的建模方式,研究期望能更准确地预测POI的人气,从而改善推荐系统的质量和用户体验,尤其是在旅游和本地服务领域。这种技术的进步对于提升用户满意度,促进相关商业活动的发展具有重要意义。
1041-4347 (c) 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TKDE.2018.2842190, IEEE
Transactions on Knowledge and Data Engineering
3
this spot to others. In order to solve the “sparsity problem”,
topic model method (TM) and its improvement are showed
in many works [15], [16], TM is a model that make POI rec-
ommendation by making use of visitors’ preferences. Even
though a user has few POI information, through discovering
the “topics”, we can also recommend proper POI to the user.
We mainly focus on the work by Jiang et al. [17], this
work presents a personalized travel sequence recommenda-
tion by a Topical Package Model. Dataset is built by mining
user travel interest in community-contributed photos and
travelogues, Jiang et al. specifically represent the structure
of data they crawled from IgoUgo. In the method of ranking
famous travel routes, they consider the popularity of attrac-
tions and visitors’ preferences at the same time. Referring to
these thoughts, we develop our methods based on hierarchi-
cal structure of data. Compared to single data source used
in this work, we collect data from several travel websites.
Because of the different focus of research in [17] and our
work, while they mention the popularity of attractions, the
problem setting and techniques are markedly different.
In the area of popularity prediction, research works
aiming at social influence and social behaviors are flourish-
ing [18]. Cui et al. [19] focus on measuring item-level social
influence. To deal with the social information effectively,
they propose a HF-NTF approach to study user-post specific
social influence prediction. Jiang et al. [20] consider one-
class collaborative filtering method in retweeting prediction
and achieve the improvement of the OCCF performance
by a novel weighting method that measures retweeting
probability score between user and message. There also exist
work that focus on strategies improving prediction. Song et
al. [21] propose a multiple social network learning model,
which is applied to predicting volunteerism tendency. They
solve the challenge of block-wise missing data as well by
utilizing multiple sources jointly. Wu et al. [22] focus on
time information on social media popularity. They utilize a
Multi-scale Temporal Decomposition method which aims at
factorizing contexts of both user-item and time-sensitive for
predicting photo popularity in social media. Meier et al. [23]
make several design suggestions based on the investigation
of re-finding strategies and demonstrate the possibility of
predicting if a tweet is likely to be re-found.
However, there are not many researches in popularity
prediction of scenic spots. In [7], Cho et al. conduct a
research on POI prediction in Location-Based Social Net-
works, where the prediction of POI to be visited next by
a user is evaluated based on a novel model of human
movement and mobility. While the method has an influence
on researches in POI prediction, the problem of concern in
this work is different from our work which concentrates on
popularity change of an attraction. Additionally, the data
used in this work is sparse, which leads to unsatisfactory
datasets to the requirements of their method.
Hierarchical method is applied effectively in various
fields [24], especially in dealing with UGC content. In [25],
Zhu et al. present an automatically generated and updated
topic hierarchy to organize information from multiple UGC
sources. The hierarchy considers topic items as well as sub-
topic relations by which UGC content can be organized.
Ahmed et.al provide a hierarchical method named nCRF.
This hierarchy is of three distributions over locations, topics,
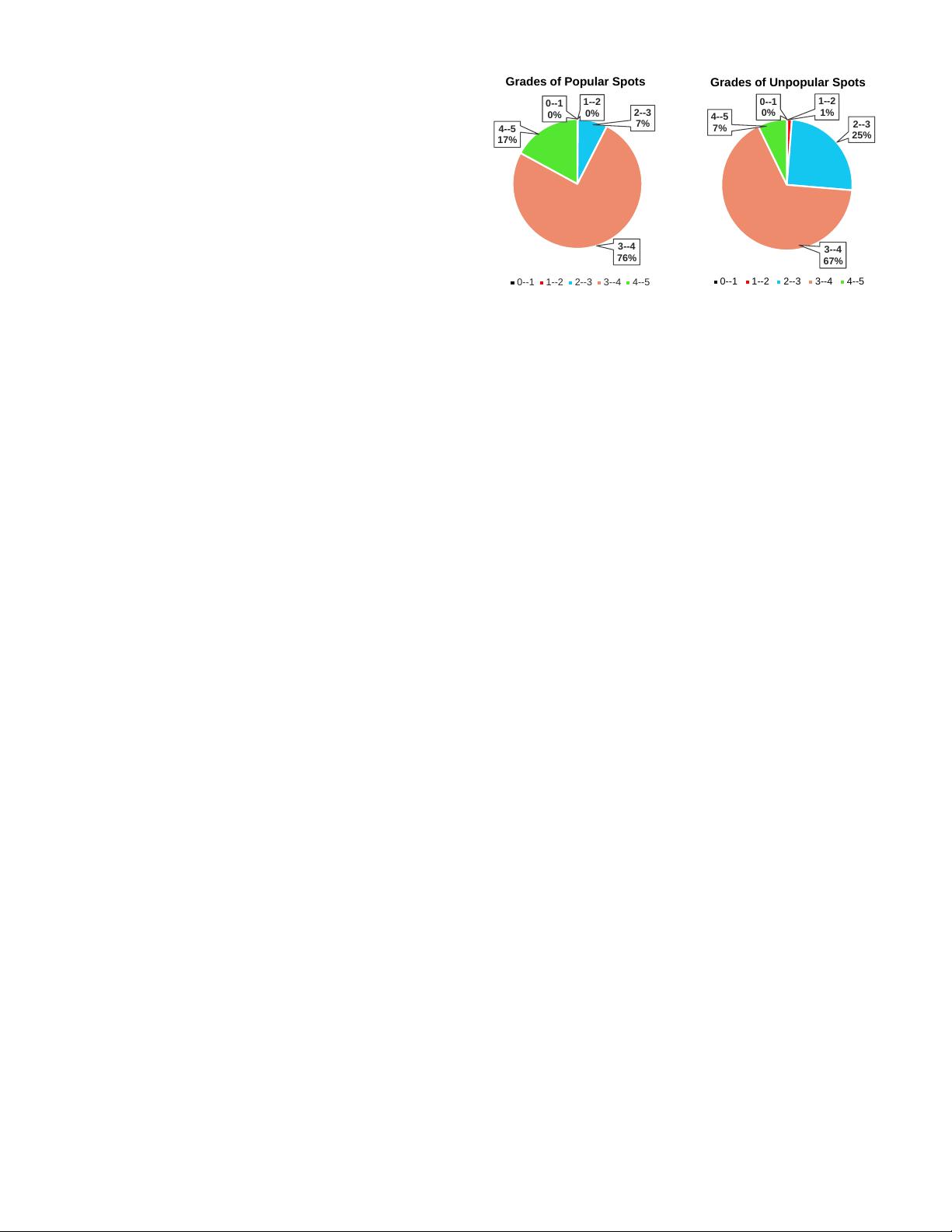
Grades of Unpopular Spots Grades of Popular Spots
0--1 0.11 0--1 0
1--2 1.12 1--2 0.13
2--3 25.08 2--3 7.4
3--4 66.47 3--4 75.4
4--5 7.22 4--5 17.07
0--1
0%
1--2
1%
2--3
25%
3--4
67%
4--5
7%
Grades of Unpopular Spots
0--1 1--2 2--3 3--4 4--5
0--1
0%
1--2
0%
2--3
7%
3--4
76%
4--5
17%
Grades of Popular Spots
0--1 1--2 2--3 3--4 4--5
Fig. 3: Grade Distribution.
and user characteristics, which performance well in location
estimation [26]. In [27], a feature learning model based on
hierarchy is proposed in event forecasting. The Nth-order
strong hierarchy has interaction with group Lasso across
multiple data sources. In the problem of prediction, Zhang
et.al [28] propose a hierarchical model combined with bi-
modal deep belief network, which considers both vision-
specific and text-specific DBN in the multinomial level.
Existing hierarchical models seldom refer to aspects of
POI, especially POI prediction. Besides, these hierarchies
overlook the combination of nature language models with
multi-feature models, which is especially significant to en-
sure the completeness of real-world information.
As compared to existing studies above-mentioned, our
work focus on POI popularity prediction by integrating
multiple sources with new hierarchical POI modelling
method, which is unexplored previously. The information
of POIs can be completed relatively even though very few
UGC content is in regard to certain POI.
3 DATA COLLECTION
Recently, as social networks keep emerging, people incline
to comment on POIs and share their experiences in on-
line tourism websites, where they also search for tourist
destination referring to other visitors’ comments. Multiple
media types are explored widely in existing researches [29].
Taking Dianping as an example, it has over 250 million
users and over 20 billion monthly page views, which pro-
vide comprehensive descriptions such as textual comments,
images, grades, for each individual POI. Considering the
fact of data scarcity problem and the incompleteness of
information from a single website, it is necessary to establish
our POI dataset across multiple sources. The illustration of
multi-source description of POIs is shown in Figure 2. Take
Chengdu Folk Custom Park as an example, while informa-
tion is complete in Dianping, there is still missing data on
other websites. This phenomenon is common among the
majority of POIs, even worse, a large number of POIs have
few information in every single platform.
We build a multi-source POI dataset by integrating
content of several specific provinces in China from four
main-stream tourism platforms, i.e., Dianping
2
, Mafengwo
3
,
2. https://www.dianping.com/
3. http://www.mafengwo.cn/
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-03-27 上传
2021-08-15 上传
2019-07-29 上传
2022-01-24 上传
2023-02-23 上传

weixin_38747815
- 粉丝: 54
- 资源: 889
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
