淘宝分布式数据层:从水平分库到服务化与读写分离的演进
淘宝分布式数据层的发展历程可以追溯到2005年,当时主要通过水平分库技术来处理业务数据,使用Oracle数据库和IBM小型机配合高端的EMC存储系统进行数据拆分。这一阶段的common-dao设计实现了基于数据库标识和用户ID的路由,但对开发人员来说并不完全透明,例如URL结构如"http://auction1.taobao.com/auction/item_detail-0db1-a0c6773727d2e1184badbcf9cdc54c07.jhtml"展示了这种设计的实际应用。
然而,随着业务的增长,到了2007年,数据库连接数问题成为瓶颈,多前台应用与共享数据库的模式导致了重复逻辑分散。为了解决业务核心的稳定性和一致性,以及减少数据库连接压力,淘宝开始转向服务化架构。这一转变不仅提升了系统的稳定性,还促进了分布式数据层的萌芽。
2008年,随着读写分离策略的引入,针对数据量大、访问量大且读写比例严重失衡(约18:1)的重要数据库,淘宝开始采用非对称数据复制的方法,将读请求分发到多个只读副本(Slave),而写请求则发送到主库(Master)。这样可以在低成本下解决大部分读取需求,并尽可能保持对开发者的透明性。
在实现读写分离的过程中,最初的尝试包括手动解析Master数据库的日志进行复制,以及通过拦截SQL操作来同步数据。这一阶段,虽然没有现成的成熟工具,但团队凭借创新精神和实践摸索,逐步构建起了分布式数据层的基础。
随着时间的推移,数据层的结构进一步发展,Master-Slave模型不断完善,Master负责处理读写请求,而Slave作为备份提供读服务,通过增加冗余来提高系统的可用性和可扩展性。这一系列的技术演进,使得淘宝能够应对日益增长的业务需求,为后续的分布式架构奠定了坚实基础。
淘宝分布式数据层的诞生和发展是一个不断适应业务需求和技术挑战的过程,它从简单的水平分库策略,经过服务化、读写分离等关键步骤,最终构建出了一套能够支持海量并发和复杂业务场景的高效分布式数据架构。这个历程体现了淘宝技术团队的创新精神和实践经验,对于其他企业来说,提供了宝贵的学习和借鉴案例。
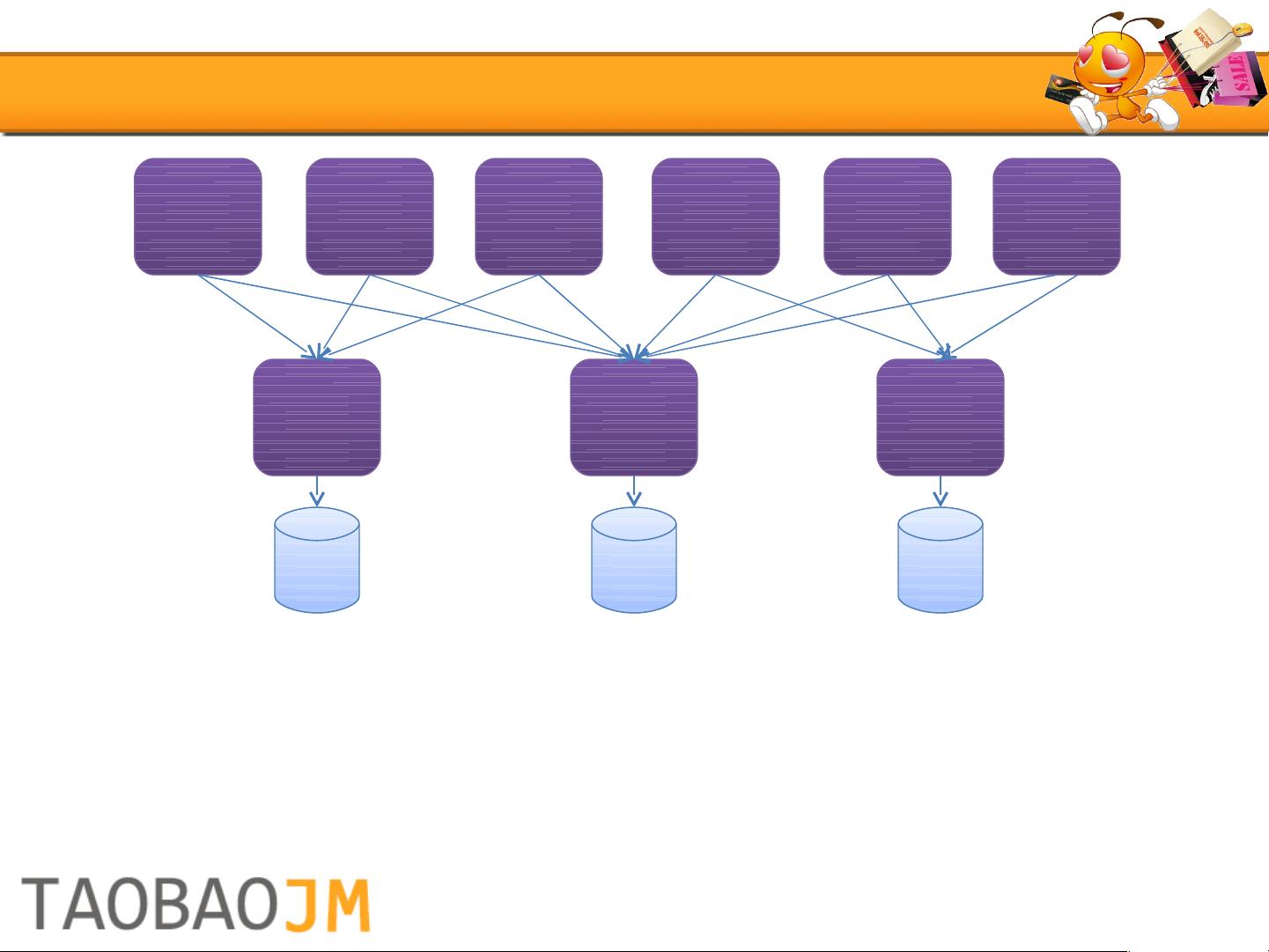
2007
业务
中心 1
业务
中心 2
业务
中心 3
服务化
解决了业务核心的稳定和一致的问题
解决了重要数据库的连接数的问题
也影响了淘宝分布式数据层的诞生和发展
前台
应用 1
前台
应用 1
前台
应用 1
前台
应用 2
前台
应用 2
前台
应用 2

剩余41页未读,继续阅读
2021-09-27 上传
2021-10-24 上传
2022-07-14 上传
2021-08-10 上传
162 浏览量
2021-08-10 上传
2024-07-08 上传
143 浏览量
114 浏览量

dongsheng329
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







