一站式CentOS大数据分布式集群搭建教程:Hadoop+Spark+HBase等
需积分: 34 181 浏览量
更新于2024-07-15
2
收藏 15.52MB DOCX 举报
在本文档中,我们将深入探讨如何在CentOS操作系统上搭建一个包含多个组件的大数据分布式集群环境,以支持Hadoop、Spark、HBase、Hive、Solr、Elasticsearch、Redis、Zookeeper、RocketMQ、MongoDB、MariaDB、Storm和Kafka等关键工具。整个过程将从单机Hadoop环境的搭建开始,逐步扩展到分布式集群的部署。
首先,我们介绍了一个虚拟机软件VMware Workstation Pro的链接,用于创建测试环境,它可以帮助你在一个安全的环境中进行大数据处理的实践。对于Java开发环境,文档提供了一份详细的安装指南,包括下载并解压JDK 8,配置环境变量,确保JAVA_HOME、PATH和CLASSPATH等设置正确。
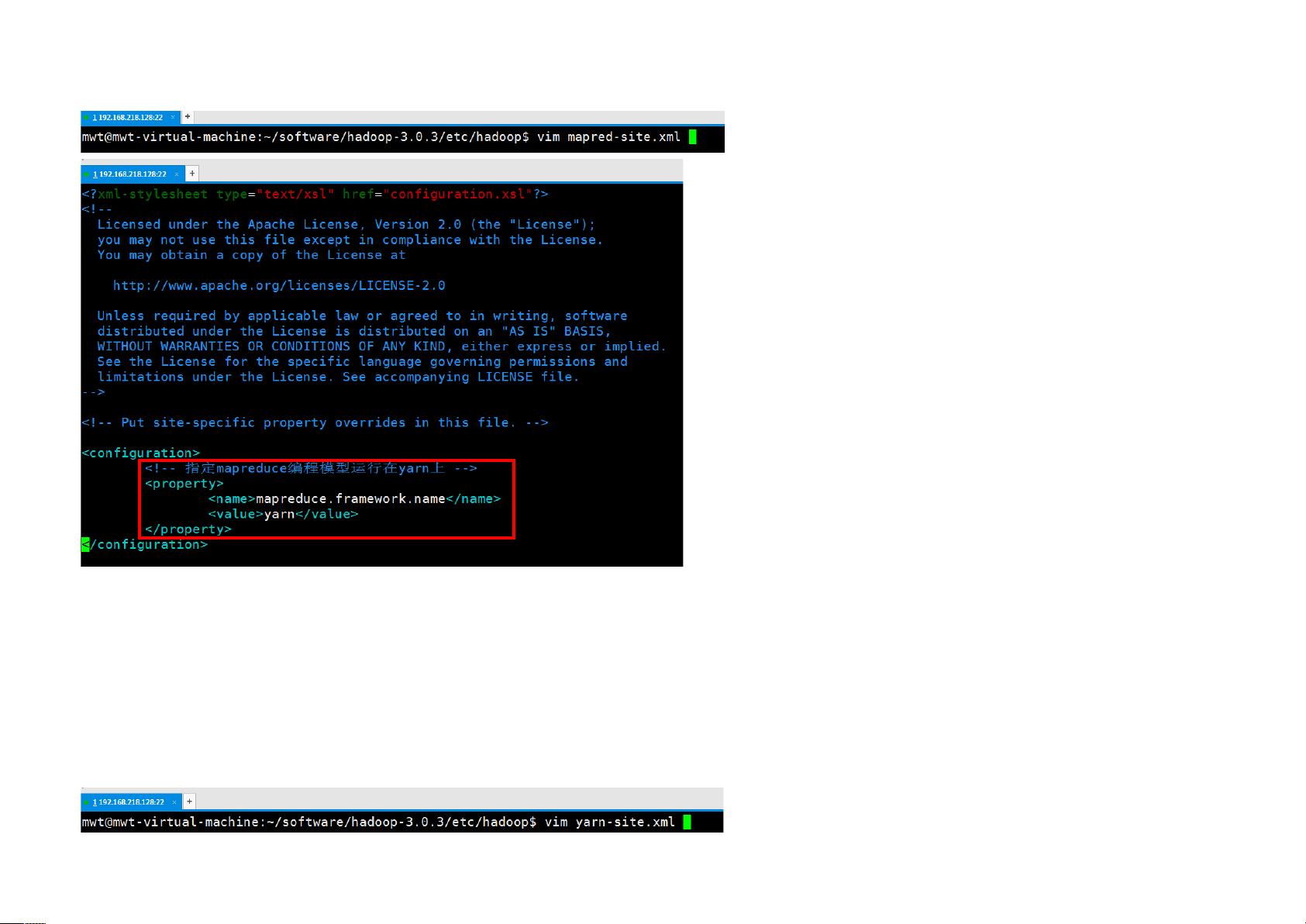
针对Hadoop的配置,文档重点介绍了三个关键配置文件:hadoop-env.sh、core-site.xml和hdfs-site.xml。在hadoop-env.sh中,再次设置了JAVA_HOME,并确保了JRE_HOME的指向。核心配置文件core-site.xml中,定义了HDFS的基本属性,如默认命名空间URL(hdfs://192.168.218.128:9000)和Hadoop的临时数据存储目录。hdfs-site.xml则配置了DFS(分布式文件系统)的副本数(设置为1,适用于伪分布式模式)、权限策略以及是否启用WebHDFS功能。
接下来,文档涵盖了其他分布式服务的安装和配置。例如,HBase是NoSQL数据库,可能需要配置存储目录;Hive是基于Hadoop的数据仓库工具,它的设置与HDFS紧密相连;Solr和Elasticsearch是搜索服务,它们在分布式环境下可能涉及到分片和复制策略;Redis作为内存数据库,可以优化数据缓存;Zookeeper是分布式协调服务,对于集群管理至关重要;RocketMQ是一个消息队列系统,常用于异步通信;而MongoDB和MariaDB则是关系型数据库,提供了不同的数据存储选择。
Spark是一个大数据处理框架,它的部署会涉及到集群启动和资源调度;Storm是一个实时流处理系统,需要配置流处理拓扑;最后,Kafka是分布式的发布/订阅消息系统,适合大规模数据传输。
在整个过程中,文档也提到了Docker的运用,可能涉及使用Docker来构建和管理这些服务的容器化部署,以实现更好的资源隔离和管理效率。
这个文档为想要在CentOS环境中构建大数据分布式集群的读者提供了一个详尽的步骤指南,覆盖了从基础环境配置到高级服务集成的全过程,适合有一定技术背景的读者参考和实践。
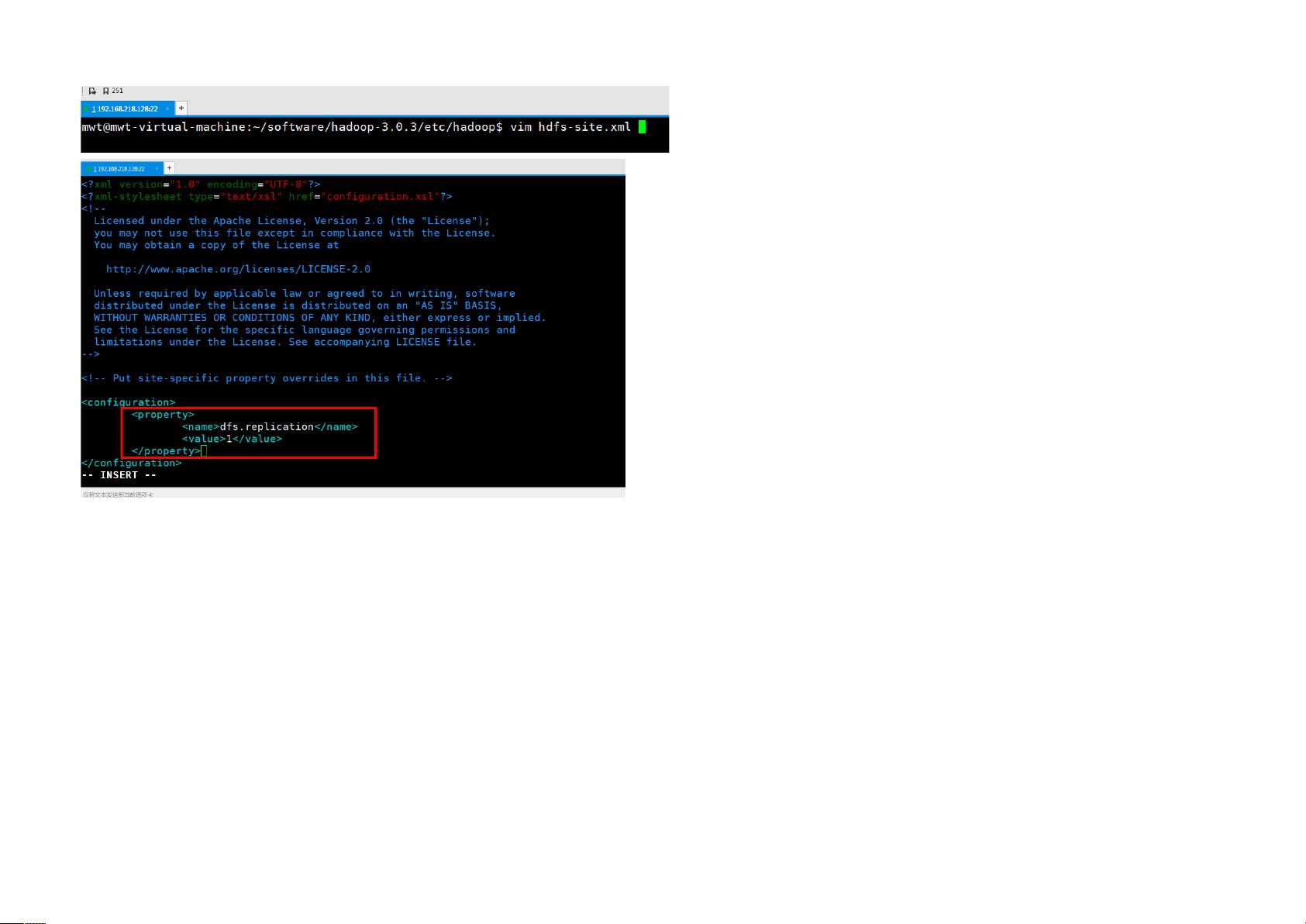
<configuration>
<!-- 每份数据存储副本数量,由于目前是伪分布式环境,一台机器只能存一份数据 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>

剩余63页未读,继续阅读
684 浏览量
101 浏览量
2022-06-21 上传
569 浏览量
190 浏览量
418 浏览量
2124 浏览量
2022-10-31 上传

林与夕
- 粉丝: 11
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高质量C/C++编程指南(作者:林锐博士,PDF完整版)
- PHP中的代码安全和SQL Injection防范3
- PHP中的代码安全和SQL Injection防范2
- PHP中的代码安全和SQL Injection防范1
- 51单片机指令系统,方便查阅
- 高级Bash脚本编程指南
- 升级PHP5的理由:PHP4和PHP5性能大对比
- oracle常用命令
- PHP上传文件涉及到的参数
- SymtemC user guide
- 联想内部独家资料windows XP 各个文件夹详细介绍.pdf
- VFP的功能及特点.ppt
- Windows 2008中文版安装实录.doc
- Spring开发指南
- Java Script 高端程序设计(精华).pdf
- 第6章 ASP.NET与XML讲解 C#
