Lucene全文检索技术详解
需积分: 3 20 浏览量
更新于2024-07-20
收藏 1.09MB DOCX 举报
"Lucene 全文检索技术笔记"
在深入探讨Lucene之前,我们首先要明白,Lucene是一个开源的全文检索引擎工具包,由Apache软件基金会开发。它不是一个完整的搜索引擎,而是一个用于构建搜索引擎的底层组件。Lucene提供了丰富的API,使得开发者能够方便地在Java应用程序中集成全文检索功能。
全文检索在现代互联网应用中扮演着重要角色,常见的应用场景包括搜索引擎(如Google)和站内搜索。站内搜索尤其受到关注,因为它可以帮助用户快速找到网站内部的特定信息。此外,文件系统的搜索也是全文检索技术的一大应用领域,使得用户能够高效地定位到存储在大量文件中的特定内容。
要理解全文检索,我们需要知道它的基本定义。全文检索是指在对文档进行分词后,创建一个索引,这个索引用于快速查找与查询条件匹配的文档。这就像字典的索引页,它提供了快速查找到具体词汇的途径。在Lucene中,索引是通过Field域来组织的,每个Field代表文档中的一个特性或属性,如标题、内容等。
实现Lucene全文检索涉及两个主要流程:索引流程和搜索流程。索引流程包括采集数据,处理文档,并将这些文档存储到索引库中。搜索流程则涉及用户输入查询条件,通过Lucene的查询解析器生成查询对象,然后查询索引库,最后将查询结果呈现给用户。需要注意的是,Lucene自身并不负责视图渲染,这部分通常需要结合其他Web开发框架来完成。
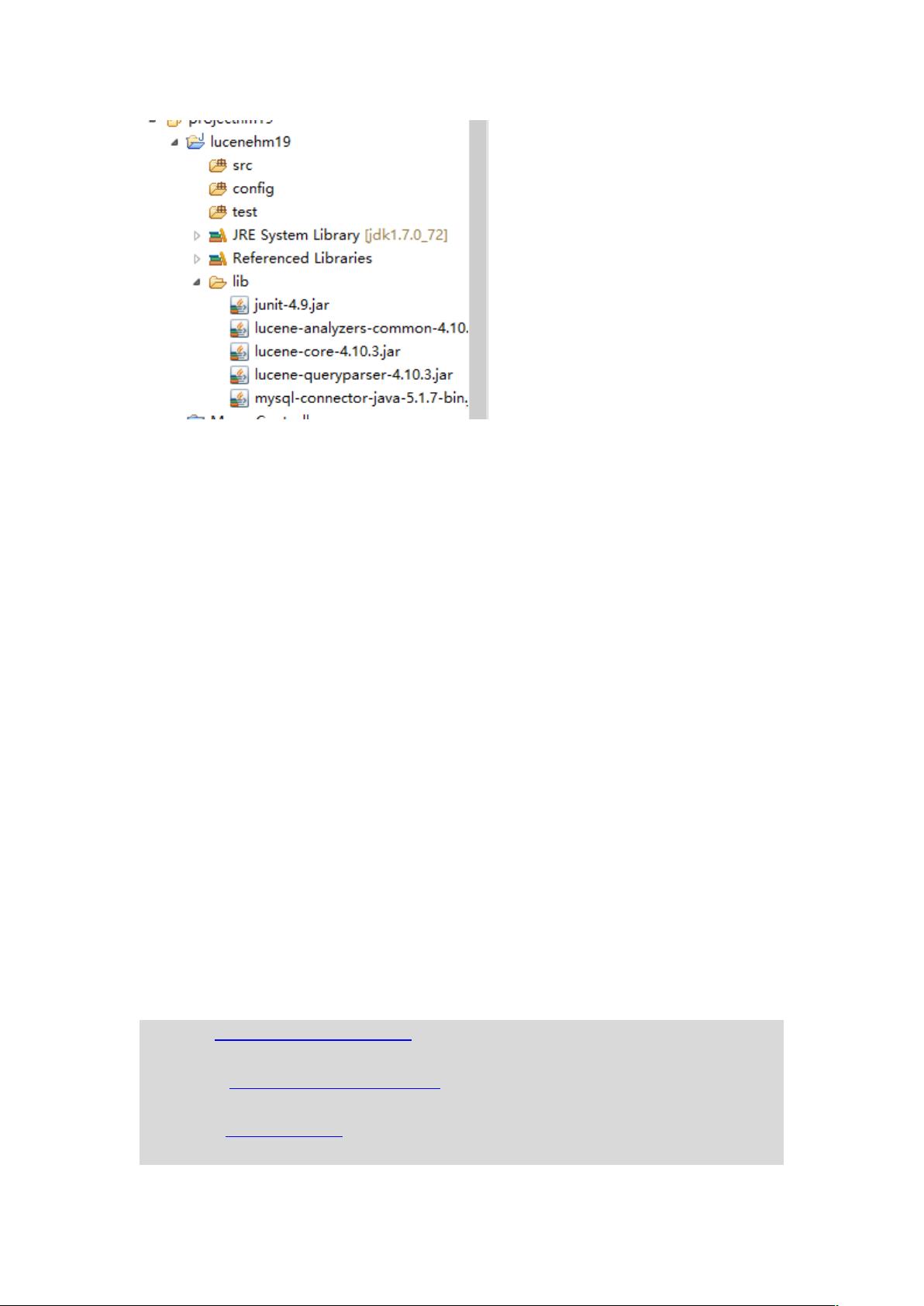
为了开始使用Lucene,我们需要配置好开发环境,包括安装JDK 1.7或更高版本,下载适合的Lucene版本(例如4.10.3),并将其添加到项目依赖中。同时,可能还需要集成数据库(如MySQL)来存储原始数据。在创建索引时,通常会从数据库中读取数据,然后使用Lucene提供的API将数据转换为索引。
在Lucene中,索引的维护包括添加、删除和修改索引项。添加索引意味着将新的文档加入到索引库;删除索引则是移除不再需要的文档;修改索引则是更新现有文档的内容。搜索过程可以通过创建不同的Query子类实例或使用QueryParser来构建查询条件,然后执行查询,获取相关的文档列表。对于中文分词,Lucene需要配合中文分词器,如IK Analyzer或SmartCNAnalyzer,以便正确处理中文文本。
Lucene提供了一个强大的框架,帮助开发者快速实现全文检索功能。通过理解其工作原理和流程,我们可以灵活地集成到各种应用中,提高数据检索的效率和用户体验。
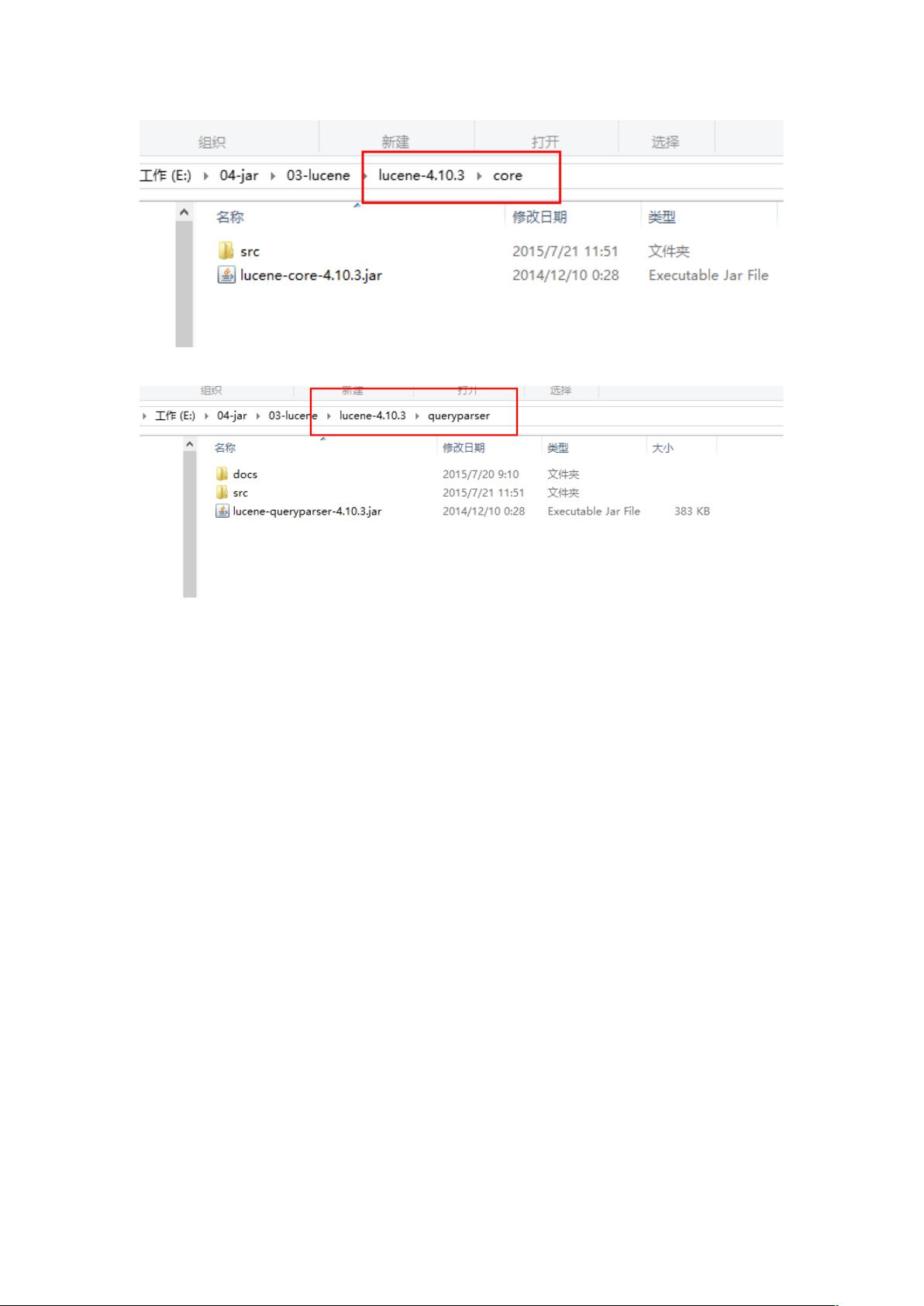
4.3 工程搭建
Mysql 驱动包
Analysis 的包
Core 包
QueryParser 包
Junit 包(非必须)
剩余35页未读,继续阅读
2015-05-10 上传
2020-05-19 上传
2008-11-01 上传
2014-01-05 上传
2010-02-28 上传

syn2203
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 作业1:cst438_assign1
- z.js:via通过Unicode的ZW(N)Js隐藏文本
- 基于Linux、QT、C++的点餐系统
- zerg:小程序教程源码-源码程序
- glogIntroduce,c语言会员积分管理系统源码,c语言程序
- 最新时时地震信息程序 V1.0
- studienarbeit2021:Niclas Mummert,斯图加特DHBW和Bertrandt Technologie GmbH的研究
- 全功能11-26A.zip
- 将Excel文件动态导入到SQL Server
- 信用卡养卡app开发HTML5模板
- Android应用源码之项目实例 商业项目源代码.zip项目安卓应用源码下载
- wx-computed2:几乎照搬vue原始码为小程序增加计算和观看特性-源码程序
- matlab 图片中隐藏信息以及提取的程序代码.zip
- level-0-module-1-alysiaroh:GitHub Classroom创建的level-0-module-1-alysiaroh
- easy_roles:轻松管理Rails的角色
- queue,c语言制作图书管理软件源码,c语言程序
