多重检验与微阵列数据分析:FDR控制与原假设估计的改进方法
版权申诉
72 浏览量
更新于2024-07-02
收藏 798KB PDF 举报
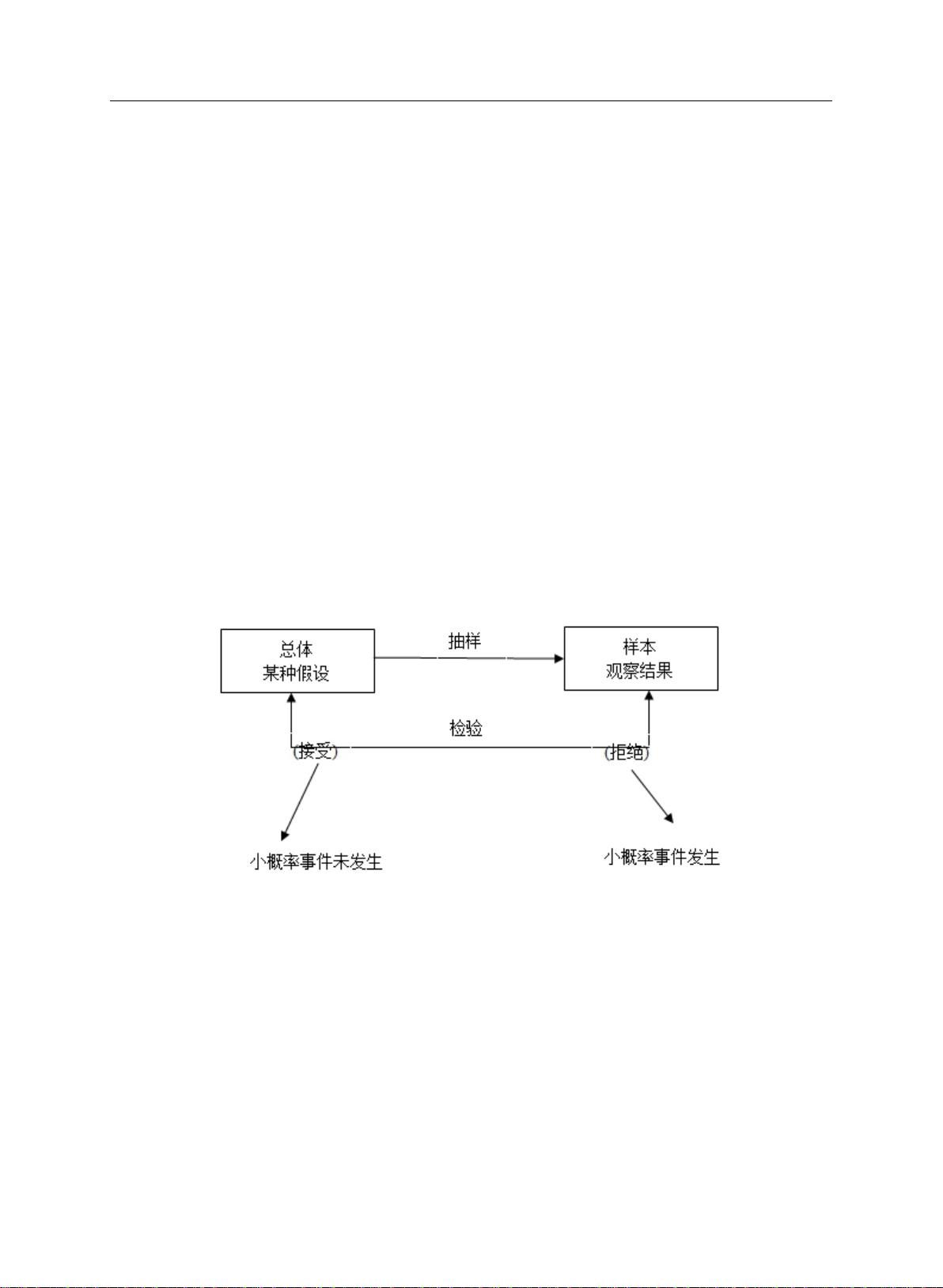
多重检验技术是生物信息学和基因组学等领域中不可或缺的数据分析工具,特别是在微阵列数据分析中发挥着关键作用。该论文深入探讨了多重检验中两个核心问题:错误发现率(False Discovery Rate, FDR)的控制和正确原假设比例(true null hypothesis proportion, m0)的估计。多重检验的目标是在众多独立测试中,既要控制因过度解读而导致的第一类错误(Type I error),即误判非差异基因为差异,又要提高显著性水平,从而找出真正有意义的差异基因。
论文首先介绍了多重检验的基本理论,特别强调了控制第一类错误的重要性,通常通过调整Family Wise Error Rate (FWER)和FDR来实现。FWER虽然传统上被广泛采用,但过于保守;而Benjamini-Hochberg (1995)提出的FDR控制方法提供了一种更为灵活且效果更好的策略。文章重点研究了四种能够有效控制FDR的算法,包括Bonferroni方法,通过对模拟数据的对比分析,展示了q值方法在控制FDR的同时保持较高检验功效的优势。
其次,论文针对估计原假设比例m0的问题进行了深入研究。通过模拟实验,文中对几种常见的估计方法进行了比较,如Jiang&Doerge(2008)的均值法,以及作者对其进行了改进,使用三次样条法替代bootstrap法,以提高估计精度。实验结果显示,改进后的样条平滑估计方法在估计m0时比李伟(2014)的方法更为精确。
论文还通过实际案例,如Hendenfalk(2001)的乳腺癌数据和FengPan等人(2009)的B细胞数据,验证了改进的估计方法在微阵列数据分析中的性能。相比于Hochberg&Benjamini(2000)、Storey&Tibshirani(2002)和Langaas等人(2005)提出的降密度算法,作者的方法能够发现更多或更少数量的差异基因,同时保持了与李伟算法相当的功效,这证明了改进的均值估计法的有效性。
总结来说,这篇论文深入探讨了多重检验技术在微阵列数据分析中的应用,重点在于如何有效控制FDR和准确估计m0,从而提高基因差异筛选的精确性和效率。通过实际案例和模拟实验,作者提出了改进的估计方法,对于生物信息学研究者而言,这些研究成果为微阵列数据分析提供了实用的工具和技术指导。

第一章 绪论
pFDR 三个测度的研究。在这里我们特别关注其对 FDR 理论的研究,他将数据分为独立
分布情形、相依分布情形、自由分布情形,分别介绍了 FDR 的控制算法,为我们提供
了坚实的理论基础
[20]
。山东大学的姜凌在其论文中针对 FDR 准则提出差值法来对 FDR
进行调整。在他的论文中明确提出使用 q 值来对错误发现率进行控制,然后选用差值法
来对零假设中的 p 值作差,从而确定 p 值存在相对较密集的区间,从而确定一个拒绝域,
拒绝处在拒绝域中的零假设
[21]
。此外,李兵(2014)在其文章中提出了错误发现率的参数
混合模型的估计以及非参数模型的估计,对参数模型进行研究时,采用随机检验,分别
使用正态分布模型和 Beta 混合模型给出了 m
0
的计算方法,这也是我们以后可以发展的
方向
[22]
。
1.3 本文研究的主要内容
本文主要探讨多重检验技术中错误发现率控制以及正确原假设比例估计两类问题,
并且把它们用于进行微阵列数据差异基因的筛选。本文第一章介绍了课题的研究背景以
及多重检验技术的研究现状。本文第二章先介绍假设检验中的基本概念,从而扩展到多
重检验,而后从多重检验假设的错误测度的角度出发,引入 FWER 和 FDR 两个错误发
现率的标准。实验部分以四类能有效控制 FDR 的算法为主要研究目标,以控制 FWER
的 Bonferroni 算法作为其他算法比较的基准,使用模拟数据对各种控制算法进行比较,
并且对原始 p 值进行优化调整,在新的 p 值集合下比较每种错误率控制方法的功效大小。
在第三章中,我们着重探讨中正确原假设的个数 m
0
的估计方法,最重要的是改进的均
值算法以及样条平滑法都作为比较的对象,以表格形式列出了各种算法估计 m
0
的值,
将各种算法估计出的 m
0
的值与理论值的偏差以折线图的形式进行展示,从而作为我们
评定算法好坏的一个辅证。第四章以微阵列数据为例,进行仿真研究,比较各个方法正
确寻找有效基因的效果。第五章对本文进行一个系统性的总结,同时指出在仿真环境下
存在的一些问题,给出了对以后研究内容的建议。
3
万方数据
剩余39页未读,继续阅读
2023-12-23 上传
2022-07-02 上传
2010-11-13 上传
2021-07-26 上传
2021-07-26 上传
2022-07-02 上传
2021-07-26 上传

programyp
- 粉丝: 89
- 资源: 9323
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
