Elasticsearch 5.5.1中文分词实践教程:避免常见问题与高效设置
在Elasticsearch 5.5.1版本中,进行中文分词实践是一项关键任务,特别是在处理大量非英文文本时。本文将详细介绍如何在实际项目中创建索引、配置分词器以及执行基本操作,以避免新手在使用过程中遇到的问题。
首先,让我们从创建索引和文档开始。在Elasticsearch中,索引和类型是数据组织的基本单元。在`createData`方法中,你看到一个名为`megacorp`的索引被创建,类型设置为`employee`。这表示数据将存储在'megacorp'索引下的'employee'类型中。文档的结构包含字段如`name`、`age`和`interests`,其中`name`字段存储字符串值,`age`字段存储整数值,而`interests`字段则存储了一个字符串数组。
分词器在Elasticsearch中扮演着至关重要的角色,负责将中文文本分解成可搜索的单个词。在Elasticsearch 5.x版本中,你需要导入`packagesearch.text`包,特别是`org.elasticsearch.client.Client`和`org.elasticsearch.action.index.IndexResponse`等类,以便执行分词和数据操作。在这个场景中,`packagesearch.text`可能包含了针对中文文本的特定分析器,如IK Analyzer或ES内置的`StandardAnalyzer`,用于处理中文字符的分割。
在创建文档时,你可以选择自动生成文档ID(如UUID)或者手动指定,但后一种方式不太推荐,因为这样可能导致ID管理混乱。使用UUID可以确保每个文档都有唯一的标识符。`setSource(map)`方法用于设置文档内容,这里用HashMap来构建,包含键值对对应的数据。
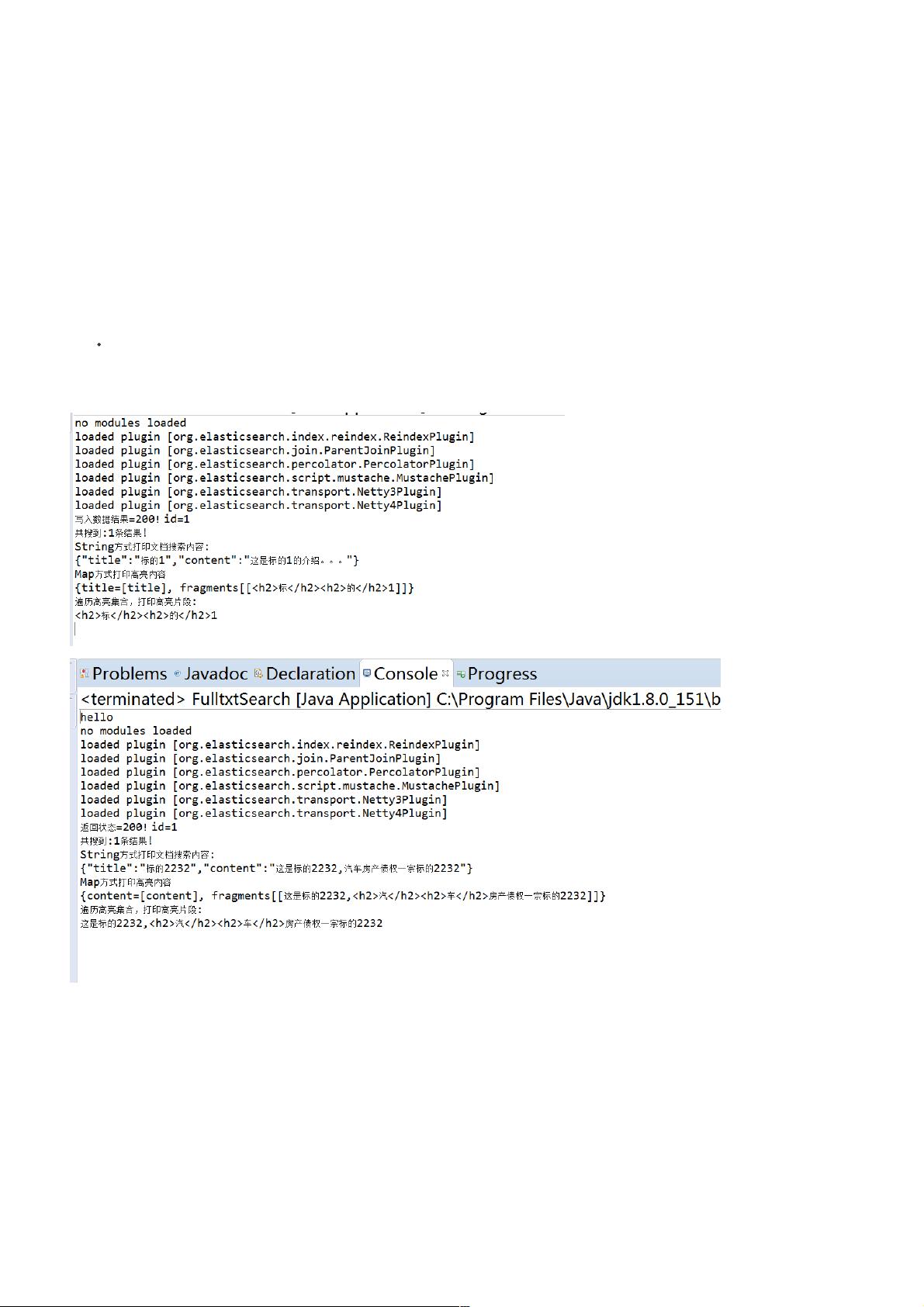
当执行`client.prepareIndex()`方法时,你需要提供一个`IndexResponse`对象,这个对象会返回一个表示操作状态的结果,包括HTTP状态码和文档ID。通过打印`response.status().getStatus()`和`response.getId()`,你可以验证数据是否成功写入到索引。
如果你还需要执行搜索操作,可以使用`SearchResponse`,它提供了搜索结果和相关元数据。例如,`import org.elasticsearch.action.search.SearchRequest;` 和 `import org.elasticsearch.action.search.SearchHit;` 包含了搜索请求和搜索结果的处理。
在配置分词器时,你可能需要了解如何调整`settings`,比如定义一个自定义的分析器,以适应中文文本的特点,比如全角半角转换、词性标注等。这通常涉及对`Settings`对象的修改,如添加语言相关的分析器设置:
```java
Settings settings = Settings.builder()
.put("analysis.analyzer.my_chinese_analyzer.type", "custom") // 自定义分析器类型
.put("analysis.analyzer.my_chinese_analyzer.tokenizer", "my_chinese_tokenizer") // 自定义tokenizer
.build();
```
最后,别忘了处理可能出现的异常,如网络问题(`UnknownHostException`)或Elasticsearch服务连接问题。在实际项目中,确保正确处理这些异常可以提高代码的健壮性。
总结来说,Elasticsearch 5.5.1的中文分词实践涉及到创建索引、配置分析器、执行数据操作(包括插入和搜索),以及处理潜在的异常。通过深入了解这些核心概念,你将能有效地在项目中集成Elasticsearch处理中文文本,提升搜索性能和用户体验。
elasticsearch
public void createData() {
Map<String, Object> map = new HashMap<String, Object>();
// map.put("name", "Smith Wang");
map.put("name", "Smith Chen");
// map.put("age", 20);
map.put("age", 5);
// map.put("interests", new String[]{"sports","film"});
map.put("interests", new String[] { "reading", "film" });
// map.put("about", "I love to go rock music");
map.put("about", "I love to go rock climbing");
IndexResponse response = client.prepareIndex("megacorp", "employee", UUID.randomUUID().toString())
.setSource(map).get();
System.out.println("写入数据结果=" + response.status().getStatus() + "!id=" + response.getId());
}
说明:prepareIndex第一个参数是 index(索引) ,第二个是type(类型),第三个是记录ID(不推荐使用UUID,后面会说)
package search.text;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
下载后可阅读完整内容,剩余4页未读,立即下载
2019-06-10 上传
2023-08-08 上传
2023-11-03 上传
2024-09-30 上传
2023-05-19 上传
2023-09-12 上传
2023-08-23 上传

chw_csdn_chw
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
