利用Hadoop架构的Pig编程:数据流处理指南
需积分: 9 73 浏览量
更新于2024-07-28
收藏 6.41MB PDF 举报
《Programming Pig:Dataflow Scripting with Hadoop》是一本由Alan Gates撰写的专业书籍,它详细介绍了如何在Hadoop架构下利用Pig语言进行数据处理。Pig是Apache Hadoop生态系统中的一个重要的大数据处理工具,它提供了一种声明式编程模型,允许开发者以类似SQL的方式处理海量数据。这本书旨在帮助读者理解和掌握Pig的基本概念、语法以及其在实际项目中的应用。
书中涵盖了以下关键知识点:
1. **Pig语言基础**:首先,作者会介绍Pig Latin(一种简洁的脚本语言)的概念,包括变量声明、常量定义、函数调用等核心元素。读者将学会如何编写Pig脚本来读取、转换和加载数据。
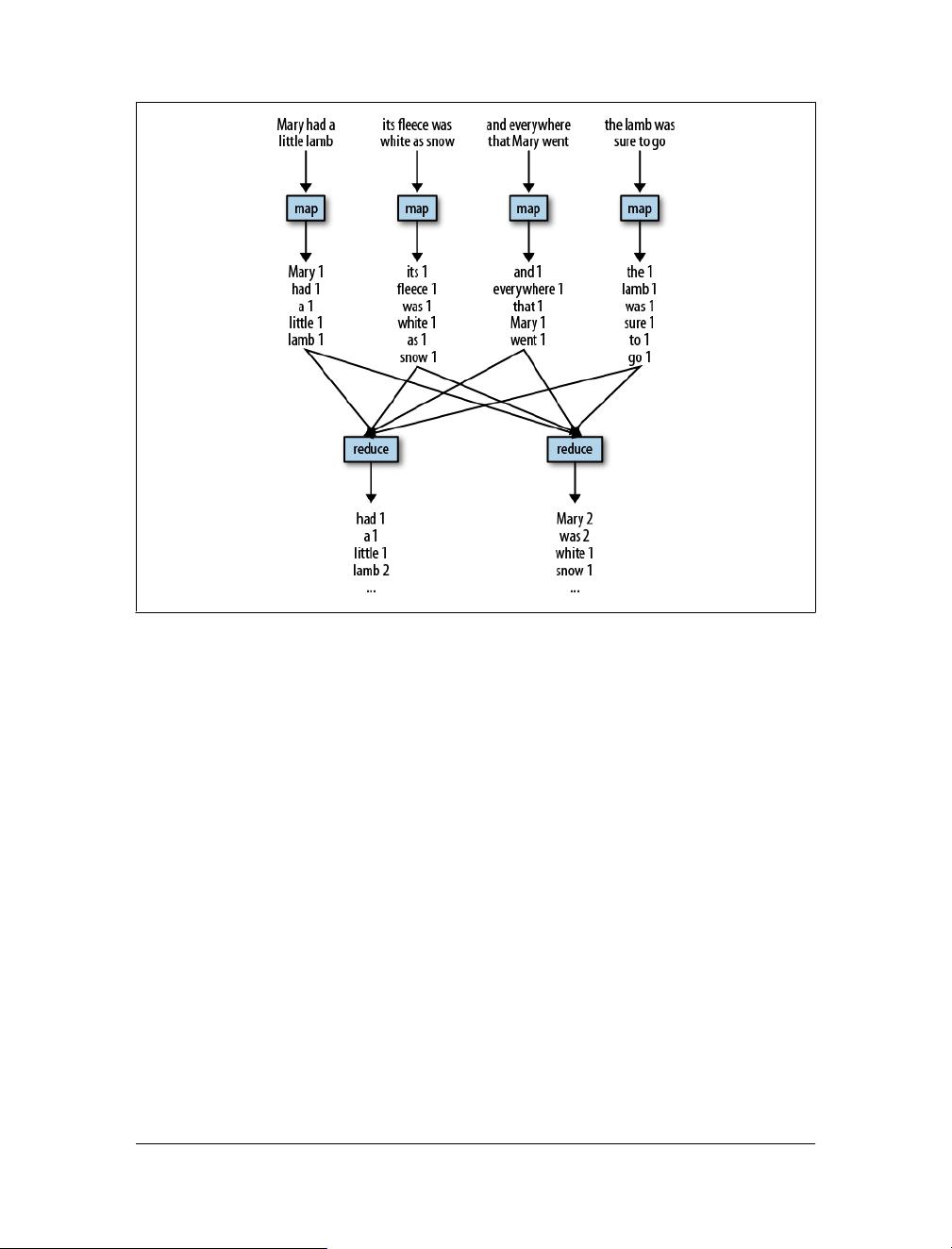
2. **数据流模型**:Pig设计的核心思想是基于数据流的数据处理,它将数据视为一系列的记录,并通过一系列算子(如装载、过滤、映射、联合、排序和存储)进行处理。理解这个模型对于编写高效的Pig脚本至关重要。
3. **Hadoop集成**:书中深入剖析了Pig如何与Hadoop MapReduce框架协作,解释了Pig如何执行任务并利用Hadoop集群资源。这包括分布式计算、分区策略、错误处理和优化策略。
4. **数据清洗与预处理**:Pig提供了丰富的函数库,用于数据清洗、转换和聚合操作,如日期处理、字符串操作和数学运算。这部分内容会展示如何利用这些工具进行数据预处理,为后续分析做准备。
5. **性能优化与调试**:为了确保在大规模数据集上获得最佳性能,本书会讨论如何调整Pig脚本,如优化查询计划、使用JOIN类型和配置参数等。此外,还有针对性能瓶颈的诊断和调试方法。
6. **实践案例**:书中包含多个实战案例,涵盖电商、社交媒体、日志分析等各种场景,使读者能够通过具体的例子理解Pig在实际项目中的应用场景和价值。
7. **最新版本更新**:由于出版时间是2011年,书中可能包含了当时最新的Pig版本特性,但要注意,对于更晚近的Hadoop和Pig发展,可能存在一些差异,需要读者结合官方文档和社区资料进行补充学习。
《Programming Pig》适合Hadoop开发者、数据分析师或任何希望在大数据领域运用Pig语言处理数据的人员阅读,通过深入浅出的讲解和实例,它将帮助读者提升在Hadoop生态系统中的数据处理能力。

Douglas of the Hadoop project provided me with very helpful feedback on the sections
covering Hadoop and MapReduce.
I would also like to thank Mike Loukides and the entire team at O’Reilly. They have
made writing my first book an enjoyable and exhilarating experience. Finally, thanks
to Yahoo! for nurturing Pig and dedicating more than 25 engineering years (and still
counting) of effort to it, and for graciously giving me the time to write this book.
xiv | Preface



剩余221页未读,继续阅读
2016-11-14 上传
2018-02-24 上传
2018-09-01 上传
2018-02-24 上传
2018-02-24 上传
2021-02-03 上传
2021-06-02 上传
2021-05-14 上传
2021-05-26 上传

quailman
- 粉丝: 0
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
