泰坦尼克生还预测:研究生徐荣钦的详细数据分析报告
需积分: 0 61 浏览量
更新于2024-07-01
5
收藏 2.24MB PDF 举报
本篇文档是深圳大学计算机技术研究生一年级学生徐荣钦在数据仓库与数据挖掘课程中完成的关于泰坦尼克号生还预测的研究项目报告。报告的主题是“基于泰坦尼克号生还预测的研究和分析”,由主讲教师陈小军指导。
1. **研究背景** (1.1)
研究背景部分介绍了机器学习的广泛定义,强调了其在模拟人类学习、获取新知识和技能方面的应用。在这个背景下,学生选择了泰坦尼克号乘客生还预测作为研究课题,利用数据挖掘技术来探索乘客的生存概率。
2. **研究选题** (1.2)
选题聚焦于实际问题,即通过分析泰坦尼克号灾难中的乘客数据,运用数据预处理、特征工程、模型选择等方法,预测哪些因素可能影响乘客的生还率,以期揭示历史事件中的模式和规律。
3. **任务描述** (1.3)
任务包括对原始数据集的探索性分析,如数据清洗(缺失值处理、异常值检测)、数据可视化,以及特征提取和转换,最终通过建立和比较不同的预测模型来评估生存概率。
4. **数据集描述** (1.4)
数据集包含了泰坦尼克号乘客的基本信息,如年龄、性别、船票类别、家庭成员数量、登船地点等,以及生死结果。这些数据是研究的基础,对于理解变量与生存率的关系至关重要。
5. **数据预处理** (3.1)
预处理阶段包括对数据集的深入观察,识别并处理缺失值,以及识别和处理可能的离群点。这是数据分析的关键步骤,确保数据质量对后续建模的影响。
6. **特征工程** (3.3)
特征工程涉及对Name、Ticket、SibSp、Parch、Cabin、Embarked和Sex等特征进行处理,可能包括编码、合并、转换等,以便模型能更好地理解和利用这些信息。
7. **模型选择与优化** (3.4 & 3.5)
学生尝试了单一模型(如逻辑回归、决策树等)和模型融合(如随机森林、梯度提升机等)来进行预测,并进行了参数调整和特征选择,以提高预测性能。
8. **项目结果** (4)
报告展示了经过处理后的数据和模型预测的结果,分析了哪些特征对生还率的影响最为显著,以及模型优化后预测的准确性和可靠性。
9. **项目总结** (5)
最后,学生总结了整个项目的收获,反思了方法的有效性,以及对未来可能改进的方向。
这篇报告不仅涵盖了数据科学中的基础知识,还展示了实际项目应用中如何通过机器学习技术解决实际问题的能力。
7
二、项目知识点
项目的知识点主要有以下几个,具体将会在下面的“实验过程”部分进行。
1. 数据预处理;
2. 数据可视化;
3. 特征工程;
4. 模型选择;
5. 实验结果的评价;
三、实验过程
在这一部分中,我们先对训练集 train.csv 和 test.csv 读进来,然后观察它们的某些
属性字段是否数据缺失。如果存在数据缺失,则需要根据属性字段的数据特征进行缺失值填
补。此外,在机器学习中,离群点(Outlier)又称为异常点,会影响预测模型的稳定性和
泛化性能。因此,我们需要对训练集的数据进行离群点检测和剔除离群点。
3.1 数据预处理
3.1.1 数据集观察
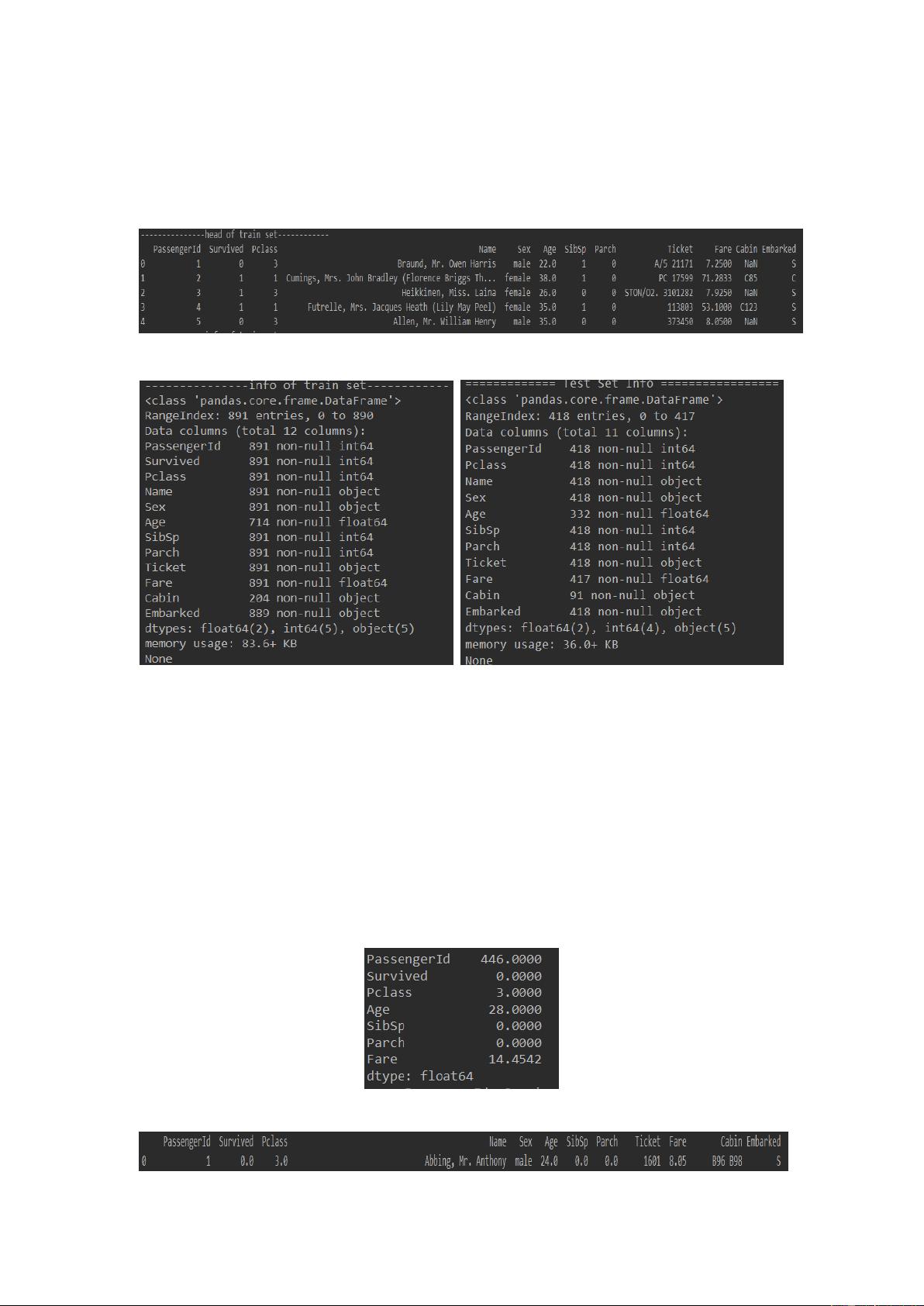
首先,我们利用读入训练集 train.csv 和测试集 test.csv。如图 3-2 所示,是训练集的
前 5 行数据以及每个数据样本的特征属性信息。此外,图 3-3 展示了每个属性字段的数值类
型和数目,我们可以从图 3-3 看出——train、test 数据集中的 Age、Cabin 发生了大量数
据缺失,train 数据集中 embarked 有少量缺失,test 数据集中 Fare 有少量缺失。图 3-1
是具体的代码。
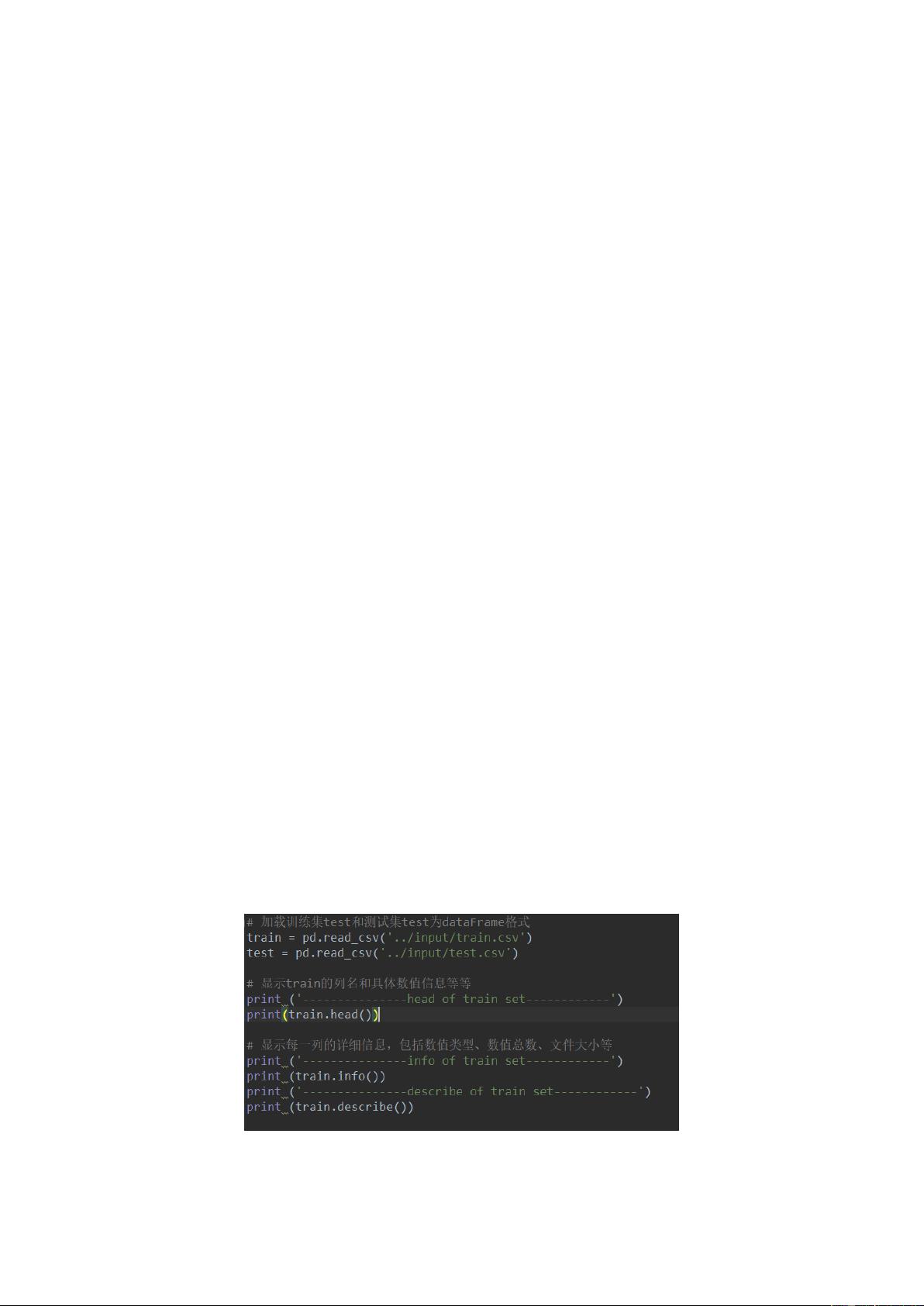
图 3-1 读入数据和显示数据预览的代码
剩余38页未读,继续阅读
1888 浏览量
695 浏览量
105 浏览量
112 浏览量
2022-08-08 上传

UEgood雪姐姐
- 粉丝: 42
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
