Pig数据模型深度解析:Schema与数据类型
188 浏览量
更新于2024-08-28
收藏 146KB PDF 举报
"本文主要分析Pig的数据模型,包括数据结构和数据类型,以及在处理不同情况下的schema处理规则。"
在Pig的数据模型中,关键概念包括relation、bag、tuple和field,以及schema。首先,relation是PigLatin表达式操作的核心对象,它由一系列的操作如FILTER、FOREACH、GROUP和SPLIT等来处理。这些操作的对象是bag,bag本质上是一个tuple的集合。每个tuple则是一个有序的field列表,field代表了数据的基本单元,可以理解为数据的字段或列。
Schema在Pig中扮演着至关重要的角色,它定义了数据的结构和类型。Schema包含field的名称和类型,用户可以通过`as`语句自定义schema,或者在`load`函数中指定schema,例如使用PigStorage或AvroStorage加载数据。如果在定义field时未指定类型,那么默认类型是bytearray。在处理未知schema时,有特定的规则:join、cogroup、cross操作遇到未知schema会返回nullschema;flatten一个empty inner schema的bag会得到nullschema;union操作中如果两个relation的schema不匹配,结果也会是nullschema;而field的schema为null时,该字段被视为bytearray。
Pig提供了丰富的数据类型,包括基本数据类型和复杂数据类型。基本数据类型对应于Java类,如int对应Integer,chararray对应String等。复杂数据类型如bag、tuple和map允许数据的嵌套结构。例如,一个tuple中可以包含另一个tuple或bag,如`(a, (b, c, d))`或`(a, { (b, c), (d, e) })`。但必须遵循数据类型的规则,如bag只能包含tuple,像`{a, {(b), (c)}}`这样的结构是非法的。
此外,Pig有一个特殊的null数据类型,它表示未知或不存在的数据。这不同于Java或C中的null,它用来表示数据类型不明确的情况。
在编写自定义用户定义函数(UDF)时,为了确保Pig脚本的正确执行,开发者需要在outputSchema方法中明确定义返回结果的schema。这样,Pig才能正确地理解和处理数据,从而进行进一步的计算和分析。
理解Pig的数据模型和schema处理机制对于编写高效且可靠的Pig脚本至关重要,这涉及到如何正确地组织和操作数据,以及如何处理不同类型的数据结构。通过深入分析Pig的数据模型,我们可以更好地利用Pig进行大数据处理和分析任务。
【【Pig源码分析】谈谈源码分析】谈谈Pig的数据模型的数据模型
1. 数据模型
Schema
Pig Latin表达式操作的是relation,FILTER、FOREACH、GROUP、SPLIT等关系操作符所操作的relation就是bag,bag为
tuple的集合,tuple为有序的field列表集合,而field表示数据块(A field is a piece of data),可理解为数据字段。
Schema为数据所遵从的类型格式,包括:field的名称及类型(names and types)。用户常用as语句来自定义schema,或是
load函数导入schema,比如:
A = foreach X generate .. as field1:chararray, .. as field2:bag{};
A = load '..' using PigStorage(' ', '-schema');
A = load '..' using org.apache.pig.piggybank.storage.avro.AvroStorage();
若不指定field的类型,则其默认为bytearray。对未知schema进行操作时,有:
若join/cogroup/cross多关系操作遇到未知schema,则会将其视为null schema,导致返回结果的schema也为null;
若flatten一个empty inner schema的bag(即:bag{})时,则返回结果的schema为null;
若union时二者relation的schema不一致,则返回结果的schema为null;
若field的schema为null,会将该字段视为bytearray。
为了保证pig脚本运行的有效性,在写UDF时要在outputSchema方法中指定返回结果的schema。
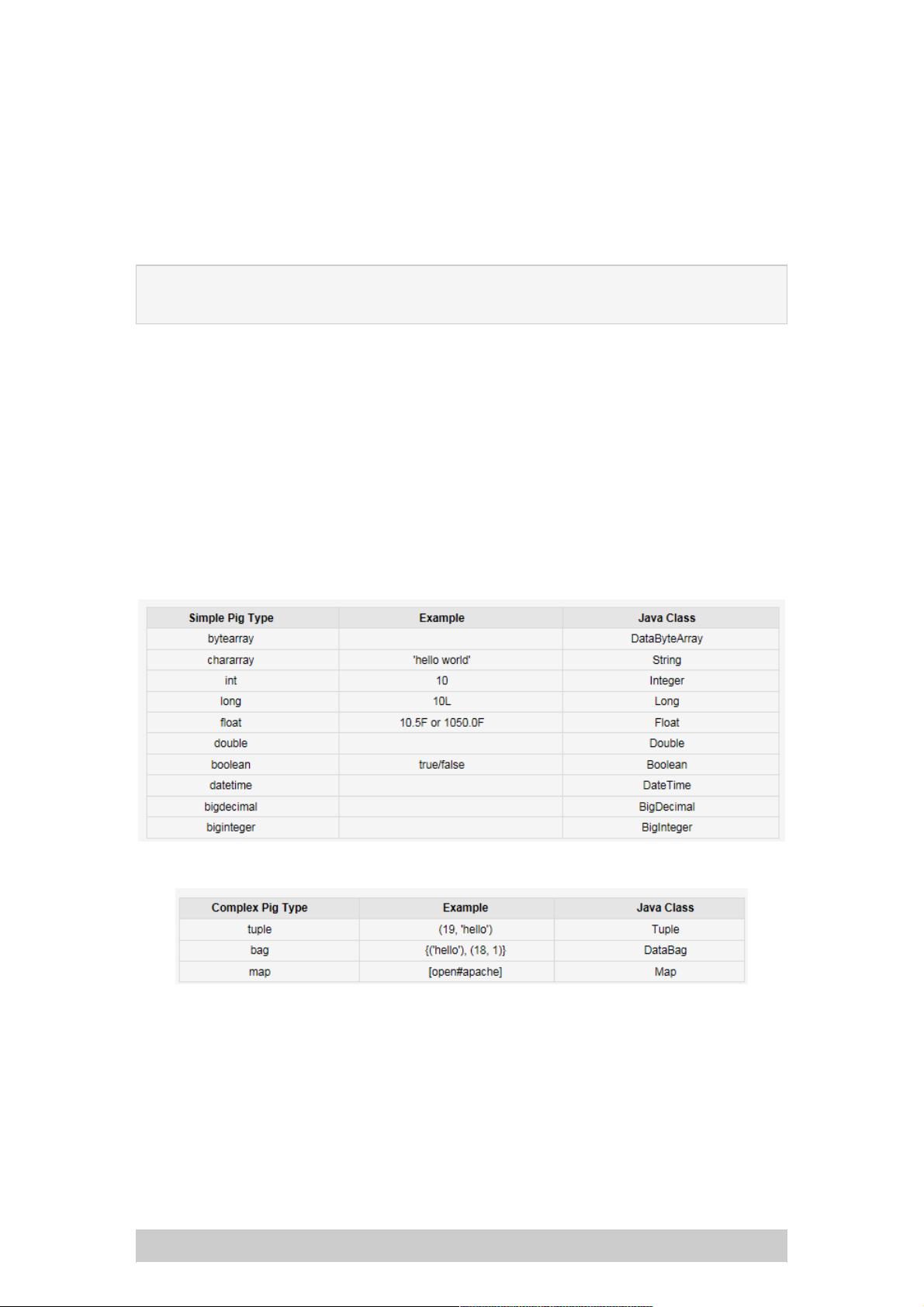
数据类型
Pig的基本数据类型与对应的Java类:
复杂数据类型及其对应的Java类:
Pig的复杂数据类型可以嵌套表达,比如:tuple中有tuple (a, (b, c, d)),tuple中有bag (a, {(b,c), (d,e)})等等。但是一定要遵从
数据类型本身的定义,比如:bag中只能是tuple的集合,比如{a, {(b),(c)}}就是不合法的。
Pig还有一种特殊的数据类型:null,与Java、C中null不一样,其表示不知道的或不存在的数据类型(unknown or non-
existent)。比如,在load数据时,如果有的数据行字段不符合定义的schema,则该字段会被置为null。
2. 源码分析
以下源码分析采用的是0.12版本。
Tuple
在KEYSET源码中,创建Tuple对象采用工厂+单例设计模式:
下载后可阅读完整内容,剩余4页未读,立即下载
2019-03-24 上传
2015-04-14 上传
2021-06-26 上传
2021-08-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38747815
- 粉丝: 54
- 资源: 889
 我的内容管理
展开
我的内容管理
展开







