印刷数字叠加识别:一种基于自动编码器的神经网络方法
27 浏览量
更新于2024-06-17
收藏 1.93MB PDF 举报
本文主要探讨了一种新的手写数字识别方法,通过将手写数字叠加到印刷数字上,利用自动编码器和卷积自动编码器进行预处理,然后使用神经网络和卷积神经网络进行分类,提高了识别准确率,降低了计算开销。
本文的核心思想是对手写数字识别(HNR)的创新,它假设手写数字是印刷数字的变形。在该方法中,首先使用自动编码器和卷积自动编码器(CAE)将手写数字图像(HNI)转换为与印刷数字图像叠加的形式(PNI)。这种转换过程减少了识别任务的复杂性。接着,通过神经网络和卷积神经网络对叠加后的图像进行分类,以此提高识别的准确性。这种方法的一个显著优点是简化了预处理步骤,不需复杂的特征提取,从而降低了计算成本。传统的HNR方法通常包括预处理、特征提取以及使用机器学习算法,而这些步骤可能导致较高的计算负担。
实验结果显示,该方法在孟加拉语、梵文和英语的手写数字基准数据集上取得了优异的识别效果,准确率分别达到了99.68%、99.73%和99.62%。这些高精度的识别结果证明了该方法的有效性,特别是在处理不同语言的手写数字时。
1. 手写数字识别(HNR):HNR是一个关键的计算机视觉领域,它涉及到从手写输入中识别数字,广泛应用于银行支票自动处理、邮政编码识别等场景。HNR的挑战在于手写数字的变形、大小、角度和个体差异。
2. 自动编码器(AE):AE是一种无监督学习模型,主要用于数据压缩和特征学习。在本文中,AE用于将手写数字图像转化为一种更适合识别的表示形式。
3. 卷积自动编码器(CAE):CAE是AE的变体,结合了卷积神经网络(CNN)的特性,擅长处理图像数据,能有效地捕捉图像中的空间结构信息。
4. 卷积神经网络(CNN):CNN是深度学习中的一种重要模型,特别适用于图像识别和分类任务。在这里,CNN用于对预处理后的PNI进行分类。
5. 计算开销:计算开销指的是执行特定任务所需的计算资源量,包括时间和内存。本文提出的叠加方法降低了这一开销,提高了效率。
6. 预处理:预处理是数据处理的一部分,旨在清理和标准化数据,使其适合进一步分析或建模。本文的预处理仅涉及简单的操作,减少了传统方法中的特征提取步骤。
7. 特征提取:特征提取是从原始数据中提取有用信息的过程,通常用于机器学习模型的训练。本文的方法避免了这一过程,依赖于AE和CAE自动学习特征。
8. 识别准确率:衡量模型性能的关键指标,本文的高识别准确率显示了所提出方法的优越性。
9. 开放获取:该研究遵循开放获取政策,意味着公众可以免费访问和使用研究成果,促进了科学知识的传播和共享。
10. 许可证:文章根据CC BY-NC-ND 4.0许可发布,允许非商业性使用,但禁止修改原始内容。
这篇来自沙特国王大学学报的文章提出了一种基于自动编码器和卷积神经网络的手写数字识别新策略,通过减少计算开销和简化流程,实现了高准确率的识别效果,对于未来HNR技术的发展具有积极的推动作用。
M. I. R.
舒沃湾
A. H. Akhand
和
N.Siddique
沙特国王大学学报
7753
×
.
- 是
的
Σ
ð
Þ
.
Σ
CAE
或
AE
(用于叠加)与
CNN
或
ANN
(用于分类)的组合被研
究用于特定
HNR
任务的合适模型。
本文其余部分的结构如下。提出了建议HNR系统的方法 在第2节
中,连同其他先决条件,以更好地理解。第3节详细分析了拟议系统的
结果。本节还包括与其他相关工作的性能比较。最后,第4对研究进行
了简要总结
2.
手写体数字在印刷体上的叠加与识别
手写数字(
HN
)可以看作是印刷数字(
PN
)的变形将
HNI
叠加
到
PNI
上,然后从
PNI
识别是所提出的
HNR
方法的功能步骤 图图
1
显
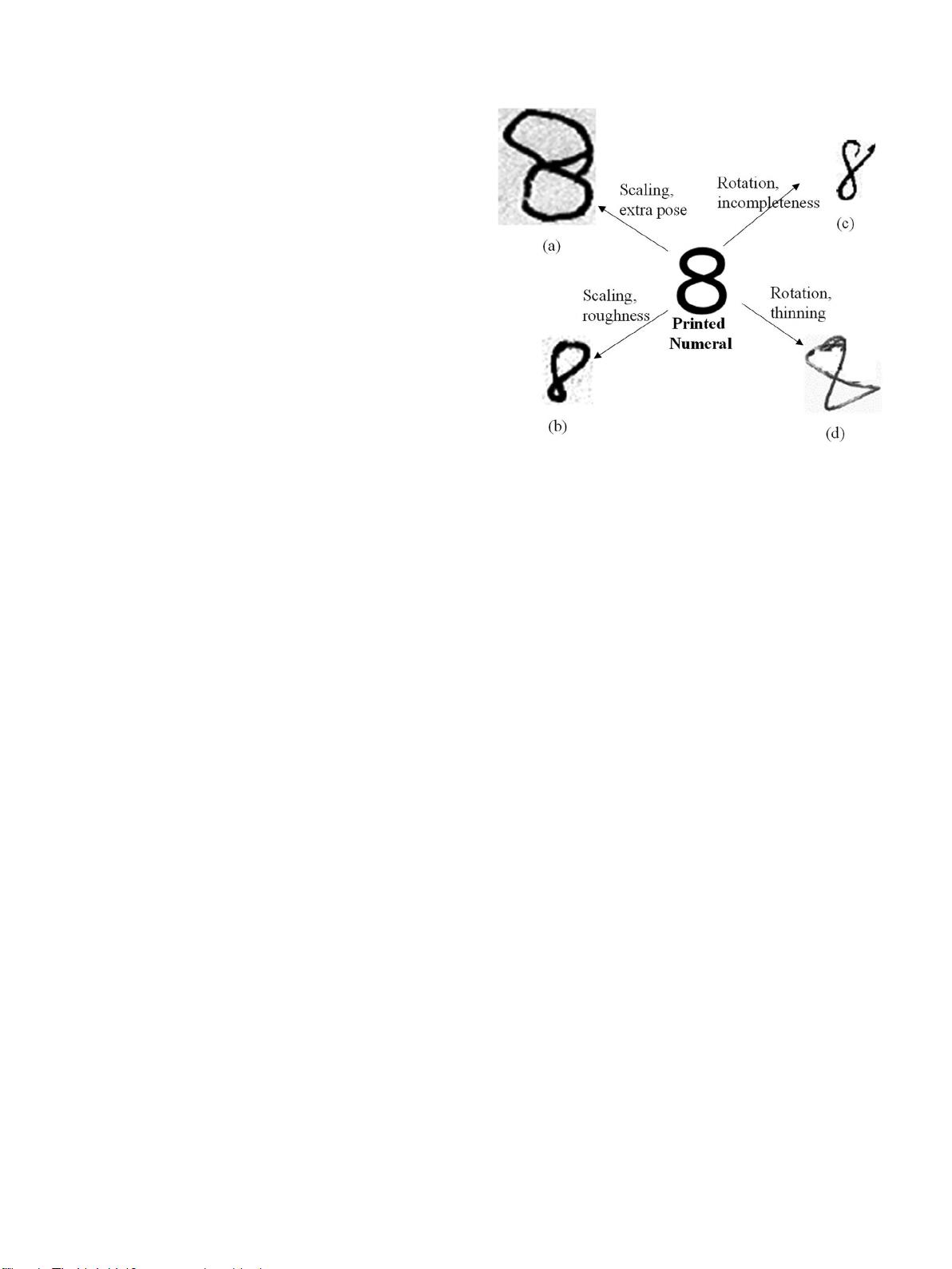
示了数字
8
(孟加拉语中的数字
4
)在手写情况下的不同变形。当人
们学习复制印刷形式并试图最小化差异时,发现手写图像在方向、缩
放、不完整、额外姿势、粗糙度、细化等方面变形由于单个
HN
图像
中的一个或多个变形,
HN
图像之间对于特定数字的相似性增加,因
此在传统分类中将所有这些图像置于相同的原始类别中的复杂性增加
另一方面,变形可以使
HN
移动到另一个数字类别的域
;
例如,孟加拉
语数字
“”
和
“”
中的变形将
HNI
定位到
PNI
上可以帮助降低识别任务中
的这种复杂性在通过成功叠加获得
PNI
之后,由于单个印刷数字的独
特形状和大小一眼看去,识别任务将更容易,并且通过将不同形
式、大小和方向的
HNI
叠加到相同大小的
PNI
上来提高准确性。
图
2
演示了建议的
HNR
系统通过叠加到打印形式(
HNRSP
)。
该模型由两个主要功能模块组成:叠加模块和分类器
.
叠加模块采用
具有变化变形的
HNI
形状,方向)并产生标准印刷形式和预定义的
固定尺寸(即,
28 28
)的
10
个
PNI
。最后,执行分类任务,将生成
的
PNI
分类到相应的数字类。
HNI
和
PNI
的大小分别定义为
H
x
×
H
y
和
P
x
×
P
y
,其中
P
x
6H
x
和
P
y
6H
y
.
所提出的模型的关键任务是
叠加模块的开发。另一方面,从PNI分类是一个普通的图像分类任务,
相对简单。因此,建议HNRSP模型由叠加和分类模块,这些是独立准
备的。
将
HN
叠加到
PN
上有助于定义
HN
和
PN
之间的误差
;
并且在迭代中
最小化
HN
和
PN
之间的误差叠加模块和分类器技术都需要计算任务
来进行叠加(即,
train
):由于已经用大量图像训练了叠加模块
(即,
18
,
000
个手写数字图像),主要的计算是为了准备它,并且
由于使用仅
10
个数字的打印图像,分类器训练成本非常小(并且可
以忽略)。此外,叠加模块和分类器方法的准备彼此独立,并且在
两个不同步骤的情况下训练时间不会增加在以下分节中
-
图1.一、可变形手写数字,例8(孟加拉语数字4):(a)缩放,额外姿势;(b)旋
转,不完整;(c)缩放,粗糙度;(d)旋转,细化。
描述了叠加模块和分类器的开发和训练
2.1.
叠加模块
图3示出了针对孟加拉语8(孟加拉语中的数字4)的样本HNI的所
提出的HNRSP中的叠加过程。 在该过程中,输入HNI x叠加到10个
孟加拉PNI z上(即,0、8、0和0),并生成相应的PNI(即,8)对于
输入HNI,其最小化HNI和PNI之间的误差Lxz。这里的挑战是实现叠
加任务,AE和CAE智能地适应它在拟议的HNRSP。AE和CAE的简要
描述以及在所提出的方法中使用的AE和CAE的新定义的结构在以下小
节中讨论。
2.1.1.
带自动编码器(
AE
)
AE
是传统
NN
的三层变体,它使用无监督学习算法,并规定输出
与输入相同,目的是减少维度或特征(
Akhand
,
2021
)。从体系结
构 的 角 度 来 看 , 最 简 单 的
AE
是 一 个 简 单 的 前 馈 多 层 感 知 器
(
MLP
),具有两端具有相同数量的神经元的单个输入和输出层以
及具有较少数量的神经元的一个隐藏层声发射的结构可以分为两部
分:编码器和解码器。首先,
AE
尝试根据下式应用确定性映射将原
始输入特征
x
编码到更低维的特征空间
h
。
h¼s
Wx
b1
其中
s
是激活函数,
W
是输入层和隐藏层之间的权重矩阵,
b
是偏置。
然后,
AE
的解码器部分尝试使用将低维特征映射到其重构的特征映
射
z
。
z
¼
s
0
W
0
x
b
0
2
其中,
s
0
:是激活函数,
W
0
¼W
T
(绑定权重),偏置
b
0
也是如此。
z
是
x
的预测,因此需要根据下式使反射误差最小化。
●
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-06-30 上传
2024-10-02 上传
2021-09-10 上传
2014-05-14 上传
2022-09-20 上传
2021-10-02 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
