ART运行时CompactingGC内存分配优化详解:非移动对象与ThreadLocalBuffer
版权申诉
97 浏览量
更新于2024-07-07
收藏 201KB DOCX 举报
ART运行时引入CompactingGC后,堆内存分配过程得到了显著优化。首先,CompactingGC的特点在于为每个ART运行时线程引入了ThreadLocalAllocationBuffer,这是一个本地缓存区域,可以大大提高内存分配的效率,减少全局内存访问带来的开销。这种机制使得新创建的对象在本地分配,直到达到阈值才会向全局内存请求。
其次,为了避免内存碎片问题,尤其是在空间不足(Out Of Memory,OOM)前,ART会执行一次同构空间压缩(HomogeneousSpaceCompact)。这涉及对非移动对象(如类对象、类方法对象和类成员变量对象等)所在的Non-MovingSpace进行整理,将它们聚集在一起,腾出空间以便为新对象分配内存。非移动对象是通过AllocNonMovableObject接口分配的,这是为了确保这些对象在生命周期内不会被移动,从而保持内存的稳定性。
在接口层面,ART运行时提供两种主要的内存分配接口:AllocObject和AllocNonMovableObject。前者用于一般对象的分配,后者则针对那些确定不会被移动的对象。所有这些分配操作最终都会通过AllocObjectWithAllocator接口进行,这个接口负责根据具体需求进行内存分配,并可能进行预处理操作,如对象初始化和内存屏障。
在具体实现中,如上文提到的,heap类中的AllocObject方法是一个模板函数,它接收线程指针、类信息、所需字节数和一个预访问检查器作为参数,确保内存分配的完整性和安全性。在CompactingGC的背景下,这个过程进一步与空间管理和内存整理紧密关联,以确保ART运行时在高效和内存利用率之间找到平衡。
总结来说,ART运行时的CompactingGC通过引入局部分配缓存和同构空间压缩,优化了内存分配策略,特别是对于非移动对象的管理,以提升性能并降低内存碎片问题。理解这些细节对于深入学习ART垃圾回收机制以及优化Android应用的内存使用至关重要。
return obj;
}
这个函数定义在文件 art/runtime/gc/heap-inl.h 中。
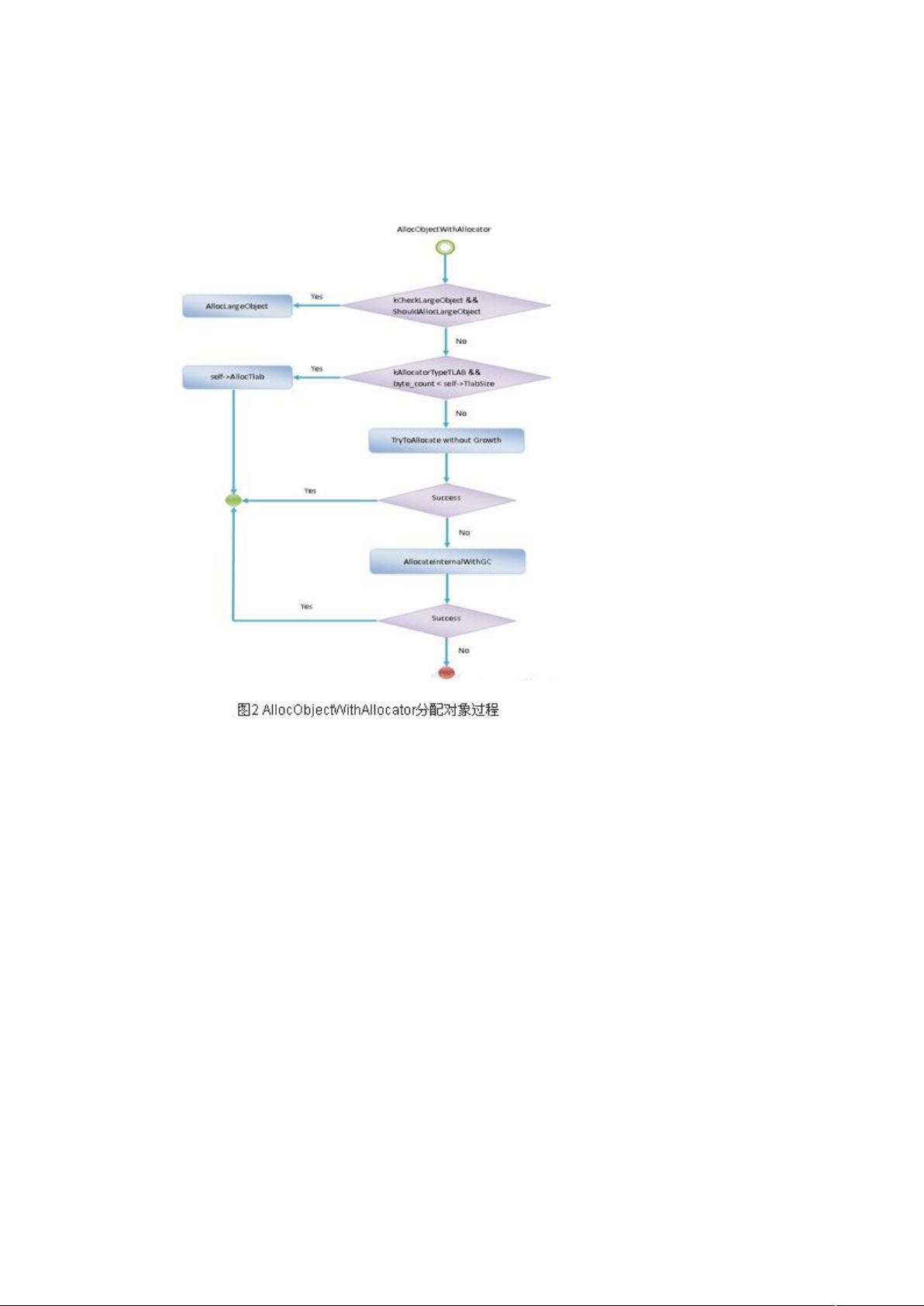
Heap 类的成员函数 AllocObjectWithAllocator 分配对象的主要逻辑如图 2 所示:
首先,如果模板参数 kCheckLargeObject 等于 true,并且要分配的是一个原子类型数组,且
该为数组的大小大于预先设置的值,那么忽略掉参数 allocator,而是调用 Heap 类的另外一
个成员函数 AllocLargeObject 直接在 Large Object Space 中分配内存。后一个条件是通过调
用 Heap 类的成员函数 ShouldAllocLargeObject 来判断是否满足的,它的实现如下所示:
[cpp] view plain copy 在 CODE 上查看代码片派生到我的代码片
inline bool Heap::ShouldAllocLargeObject(mirror::Class* c, size_t byte_count) const {
// We need to have a zygote space or else our newly allocated large object can end up in the
// Zygote resulting in it being prematurely freed.
// We can only do this for primitive objects since large objects will not be within the card table
// range. This also means that we rely on SetClass not dirtying the object's card.
return byte_count >= large_object_threshold_ && c->IsPrimitiveArray();
}
这个函数定义在文件 art/runtime/gc/heap-inl.h 中。
Heap 类的成员变量 large_object_threshold_初始化为 kDefaultLargeObjectThreshold,后
者又定义为 3 个内存页大小。也就是说,当分配的原子类型数组大小大于等于 3 个内存页
时,就在 Large Object Space 中进行分配。
回到 Heap 类的成员 AllocObjectWithAllocator 中,如果指定了要在当前 ART 运行时线

剩余36页未读,继续阅读
2022-10-24 上传
2024-09-05 上传

CSGOGOTO
- 粉丝: 38
- 资源: 27万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
