基于粗糙集理论与遗传算法的股票价格预测混合模型
需积分: 10 165 浏览量
更新于2024-07-17
收藏 727KB PDF 举报
"基于粗糙集理论与遗传算法的股票价格混合模型"
在股票市场中,技术分析是一种预测股票价格的有效方法。尽管专业的股票分析师和基金经理通常会根据客观的技术指标做出主观判断,但对非专业人士来说,由于需要考虑的复杂技术指标过多,应用这种预测技术非常困难。过去的许多预测模型存在两个主要缺点:(1)时间序列模型如自回归滑动平均模型(ARMA)和自回归条件异方差性(ARCH)需要对变量进行统计假设来构建数学方程式的预测模型,这对股票投资者来说不易理解;(2)一些人工智能(AI)算法,如神经网络(NN),挖掘出的规则不易实现。
本文提出了一种结合粗糙集理论和遗传算法的混合模型用于股票价格预测。粗糙集理论是一种处理不完全或不确定信息的工具,能够简化数据并提取关键特征,而遗传算法则是一种全局优化策略,能够搜索大量的解决方案空间以找到最优解。通过结合这两种方法,可以克服传统模型的不足,提供更易于理解和实现的预测规则。
首先,粗糙集理论被用来从大量技术指标中提炼出影响股票价格的关键因素。这涉及到对原始数据的预处理,包括数据归一化和属性约简,以减少冗余和复杂性。然后,遗传算法被应用于生成一组优化的股票预测规则,这些规则基于选定的技术指标。遗传算法通过模拟自然选择和遗传过程来逐步优化规则集,确保生成的规则既具有预测准确性,又易于解释。
文章进一步讨论了两种方法在模型构建中的具体应用:累积概率分布法和最小熵原理法。累积概率分布法用于评估不同技术指标的预测能力,而最小熵原理法则用于寻找最简化的规则集,以减少预测的不确定性。这些方法的结合使得模型能够在保留预测精度的同时,提高可解释性和实用性。
该混合模型为股票市场的非专业投资者提供了一种实用的工具,他们可以通过理解和应用由模型生成的简单规则来进行股票价格预测。同时,这种方法也为未来的研究提供了新的思路,即如何将复杂的数据分析技术转化为更直观、用户友好的预测模型。通过不断优化和改进,这种基于粗糙集理论和遗传算法的模型有可能进一步提升股票预测的准确性和效率,对投资决策提供有力支持。
Assume that the value of the segment point is being sought for a sample in the range between x
1
and x
2
. An entropy equa-
tion is written for the regions ½x
1
; x and ½x; x
2
, and denotes the first region p and the second region q. Entropy with each value
of x is expressed as: [14]
SðxÞ¼pðxÞS
p
ðxÞþqðxÞS
q
ðxÞ ð7Þ
where
S
p
ðxÞ¼½p
1
ðxÞln p
1
ðxÞþp
2
ðxÞln p
2
ðxÞ
S
q
ðxÞ¼½q
1
ðxÞln q
1
ðxÞþq
2
ðxÞln q
2
ðxÞ
ð8Þ
and where p
k
ðxÞ and q
k
ðxÞ are the conditional probabilities that the class k sample is in region ½x
1
; x
1
þ x and ½x
1
þ x; x
2
,
respectively, and pðxÞ and q(x) are the probabilities that all samples are in region ½x
1
; x
1
þ x and ½x
1
þ x; x
2
, respectively.
pðxÞþqðxÞ¼1 ð9Þ
The value of x that gives the minimum entropy is the optimum value of the segment point. The entropy estimates of pk(x)
and qk(x), and p(x) and q(x) are calculated, as follows: [14]
pkðxÞ¼
n
k
ðxÞþ1
nðxÞþ1
ð10Þ
qkðxÞ¼
N
k
ðxÞþ1
NðxÞþ1
ð11Þ
pðxÞ¼
nðxÞ
n
ð12Þ
qðxÞ¼1 pðxÞ ð13Þ
where nk(x) is the number of class k samples located in ½x1; x1 þ x, n(x) is the total number of samples located in ½x1; x1 þ x,
Nk(x) is the number of class k samples located in ½x1 þ x; x2, N(x) is the total number of samples located in ½x1 þ x; x2, and n
is the total number of samples in [x1, x2].
2.4. Rough set theory
Rough sets theory (RST) was proposed by Pawlak [33–37] in 1982. In recent years, RST has been used in economic and
financial prediction. Many researchers have applied RST to discover trading rules [20,48]. The concept of RST is founded
on the assumption that with every associated object of the universe of discourse, some information objects characterized
by the same information are indiscernible in the view of the available information about them. Any set of all indiscernible
objects is called an elementary set and forms a basic granule of knowledge about the universe. Any union of elementary sets
is referred to as a precise set; otherwise the set is rough.
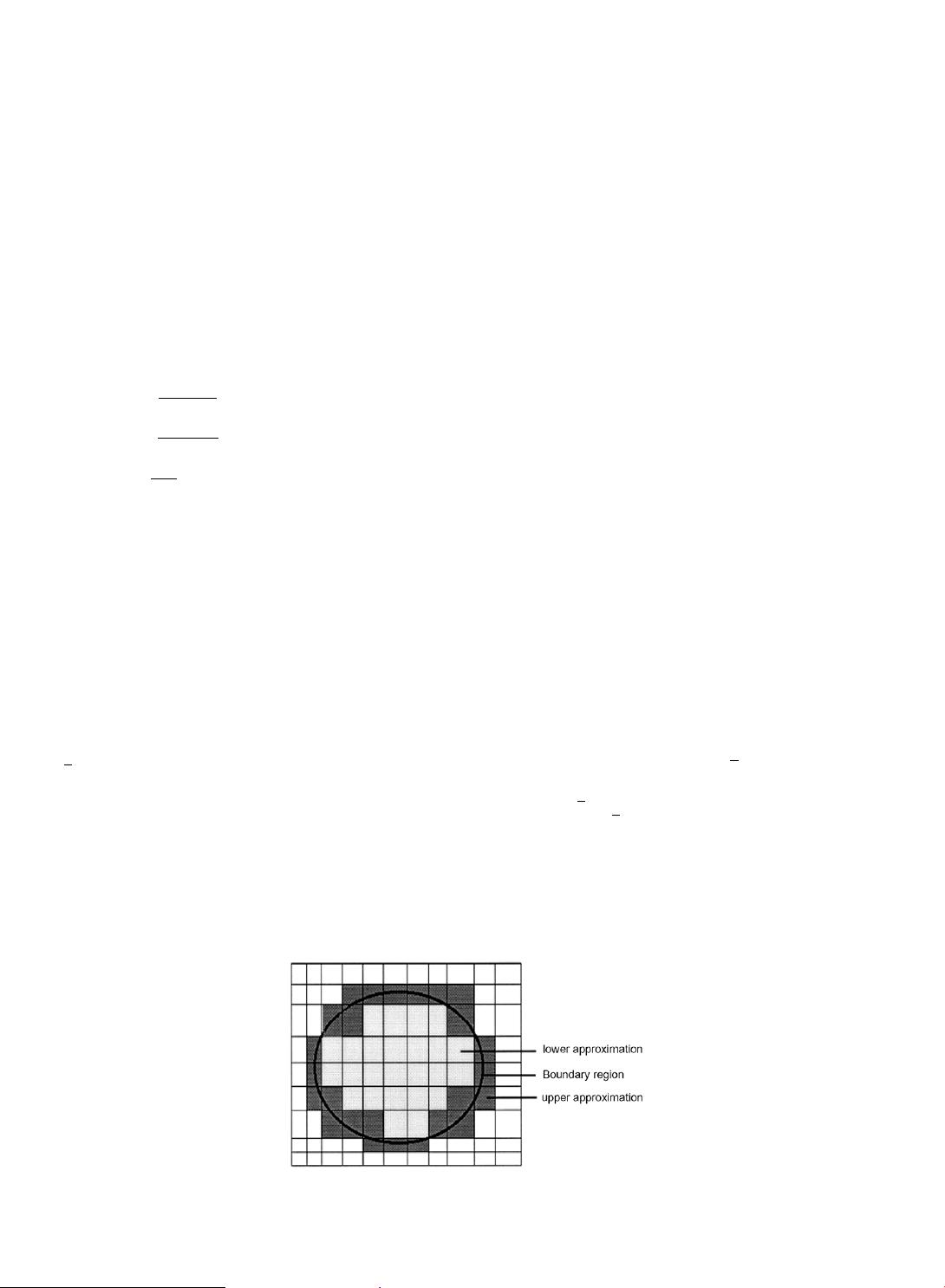
With any rough sets, a pair of precise sets, called the lower and upper approximation,
BX ¼fxj½x
B
# Xg and
BX ¼fxj½x
B
\ X – ;g of the rough sets, is associated [33]. The lower approximation consists of all objects that definitely be-
long to the set, and the upper approximation contains all objects that possibly belong to the set. The difference between the
upper and the lower approximation constitutes the boundary region, BN
B
ðxÞ¼BX BX, of the rough sets. The set X is called
‘‘rough” (or ‘‘roughly definable”) with respect to the knowledge in B, if the boundary region is non-empty. The basic notions
in rough sets are shown in Fig. 1.
The RST is a series of logical reasoning procedures used for analyzing an information system. An information system can
be seen as a decision table, denoted by S ¼ðU; A; C; DÞ, where U is the universe of discourse, A is a set of primitive features,
and C; D A are two subsets of features, assuming that A ¼ C [D and C \ D ¼;, where C is called the condition attribute and
D is the decision attribute. The measure to describe the inexactness of approximation classifications is called the quality of
Fig. 1. Basic notions of rough sets.
C.-H. Cheng et al. / Information Sciences 180 (2010) 1610–1629
1613
剩余19页未读,继续阅读

BoBoZhang
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ STL编程指南:设计组件解析
- 网站数据加密技术解析:DES、三重DES与RSA算法
- 单片机实验:LED闪烁灯实现与延时程序设计
- ABAP开发中常见问题及表结构查询方法
- RESTful HTTP应用实践与关键原则解析
- Java初学者指南:抽象类与接口解析
- CA3140A高增益运算放大器:集成MOSFET与双极晶体管的高性能解决方案
- 提升效率:Eclipse快捷键大全
- ActionScript 3.0 动画基础教程:从入门到精通
- AVR单片机实现的数字式SF6气体密度继电器设计
- ViSAGE:社会群体演化模拟与分析虚拟实验室
- Spring整合Struts与Hibernate:业务系统开发实践
- ActionScript 3.0 Cookbook 中文版:权威指南
- 信息技术在教务管理中的应用:Visual Basic6.0环境下的学生管理系统
- DIV+CSS学习难点实战经验梳理
- EJB设计模式解析:门面模式的应用与优势
