华为云CloudStream中Flink与Spark的实时流计算实践
需积分: 0 105 浏览量
更新于2024-06-30
收藏 5.25MB PDF 举报
"本文主要探讨了智能流计算中Flink和Spark在华为云CloudStream平台的应用实践,并重点解析了实时流计算的关键特性、挑战以及适用场景。此外,还介绍了Flink的运行机制和数据流编程模型。"
智能流计算是大数据处理领域的重要组成部分,它针对持续不断的数据流进行实时分析和处理。Flink和Spark作为两种流行的开源流计算框架,被广泛应用于实时业务场景。在华为云CloudStream平台上,它们提供了高效、可靠的实时计算能力。
1. **乱序**: 实时流计算中,数据到达的时间顺序可能与事件发生的时间顺序不一致,这是由于网络延迟、并发处理等因素造成的。Flink和Spark通过特定的数据排序策略来处理乱序事件,保证结果的准确性。
2. **内存计算**: 为了实现快速响应,流计算通常在内存中处理数据,避免了磁盘I/O带来的延迟。Flink和Spark都支持高效的内存管理,优化计算性能。
3. **流速不定与数据倾斜**: 实时数据流的速度可能会突然变化,且数据分布可能不均匀,导致部分节点负担过重。这两者都是流计算面临的挑战,Flink和Spark通过动态调整资源分配和负载均衡策略来应对这些问题。
4. **基于消息事件的逐条处理**: 流计算系统以事件驱动,对每个输入事件进行单独处理,这要求系统能够高效处理海量的独立数据单元。
5. **可靠快照**: 在流计算中,为了保证容错性和状态一致性,系统需要定期生成快照,以便在故障发生时恢复计算状态。Flink提供了高度精确的一致性快照,而Spark则利用检查点机制实现状态持久化。
6. **Stream Transformation**:流计算的核心操作包括数据源(Source)、转换(Transformation)和接收器(Sink)。在Flink中,这些转换可以通过API或函数调用链进行,经过逻辑优化后调度到物理节点执行。
Flink的运行时架构特点包括:
- **数据流模型**:Flink的数据流模型基于DataStream API,其中的StreamOperator和Function定义了各种操作。
- **并行处理**:Flink支持数据并行,可以根据需要设置并行度,提高处理效率。
- **反压机制**:通过Netty通信和网络Buffer实现自然反压,避免数据积压,保持系统的稳定运行。
适用场景广泛,如实时推荐、股市监控、网约车服务、金融风控、异常检测、交通物流监控等。Flink和Spark结合各自的优势,为CloudStream提供了强大的实时分析能力,帮助企业及时发现业务趋势,提升决策效率。
DATAFLOW编程模型是流计算的典型抽象,它将无限的数据流分配到窗口(Window)中进行处理,并通过触发器(Trigger)和增量处理(Incremental Processing)来控制计算的时机和频率,使得实时计算能够在无界数据流中有效进行。
Flink和Spark在华为云CloudStream中的应用实践展示了实时流计算在应对复杂业务需求和挑战方面的强大能力,为企业提供了一种高效的数据处理解决方案。
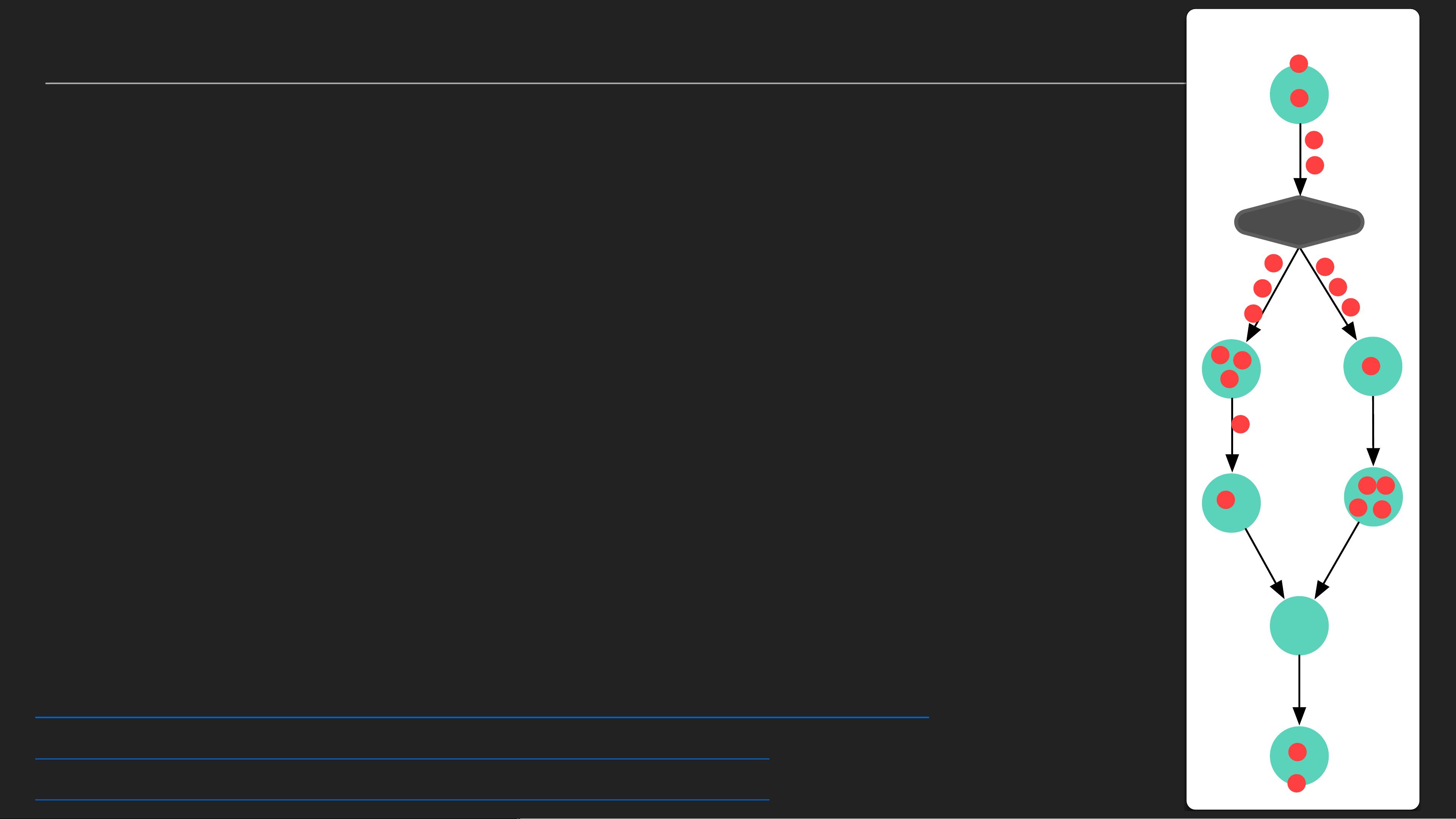
DATAFLOW编程模型
•
infinite stream data
•
window:分配/合并
•
trigger and incremental processing
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
http://people.csail.mit.edu/matei/courses/2015/6.S897/readings/google-dataflow.pdf
'DWDƊRZ
keyBy
剩余25页未读,继续阅读
2025-02-19 上传
2024-10-25 上传
2024-12-10 上传
2025-02-13 上传
241 浏览量
116 浏览量
2025-03-12 上传
2024-10-25 上传
144 浏览量

蓝洱
- 粉丝: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java实现推箱子小程序技术解析
- Hopp Doc Gen CLI:打造HTTPS API文档利器
- 掌握Pentaho Kettle解决方案与代码实践
- 教育机器人大赛51组代码展示自主算法
- 初学者指南:Android拨号器应用开发教程
- 必胜客美食宣传广告的精致FLASH源码解析
- 全技术领域资源覆盖的在线食品商城购物网站源码
- 一键式FTP部署Flutter Web应用工具发布
- macOS下安装nVidia驱动的简易教程
- EGOTableViewPullRefresh: GitHub热门下拉刷新Demo介绍
- MMM-ModuleScheduler模块:MagicMirror的显示与通知调度工具
- 哈工大单片机课程上机实验代码完整版
- 1000W逆变器PCB与原理图设计制作教程
- DIV+CSS3打造的炫彩照片墙与动画效果
- 计算机网络基础与应用:微课版实训教程
- gvim73_46:最新GVIM编辑器的发布与应用
