机器学习深度学习:张量、矩阵与范数解析
需积分: 40 159 浏览量
更新于2024-07-18
收藏 21.07MB PDF 举报
"这是关于机器学习和深度学习基础知识的概述,主要涵盖了数学概念,如标量、向量和张量,以及它们之间的联系。此外,还介绍了矩阵与向量的乘法以及不同范数的计算方法。"
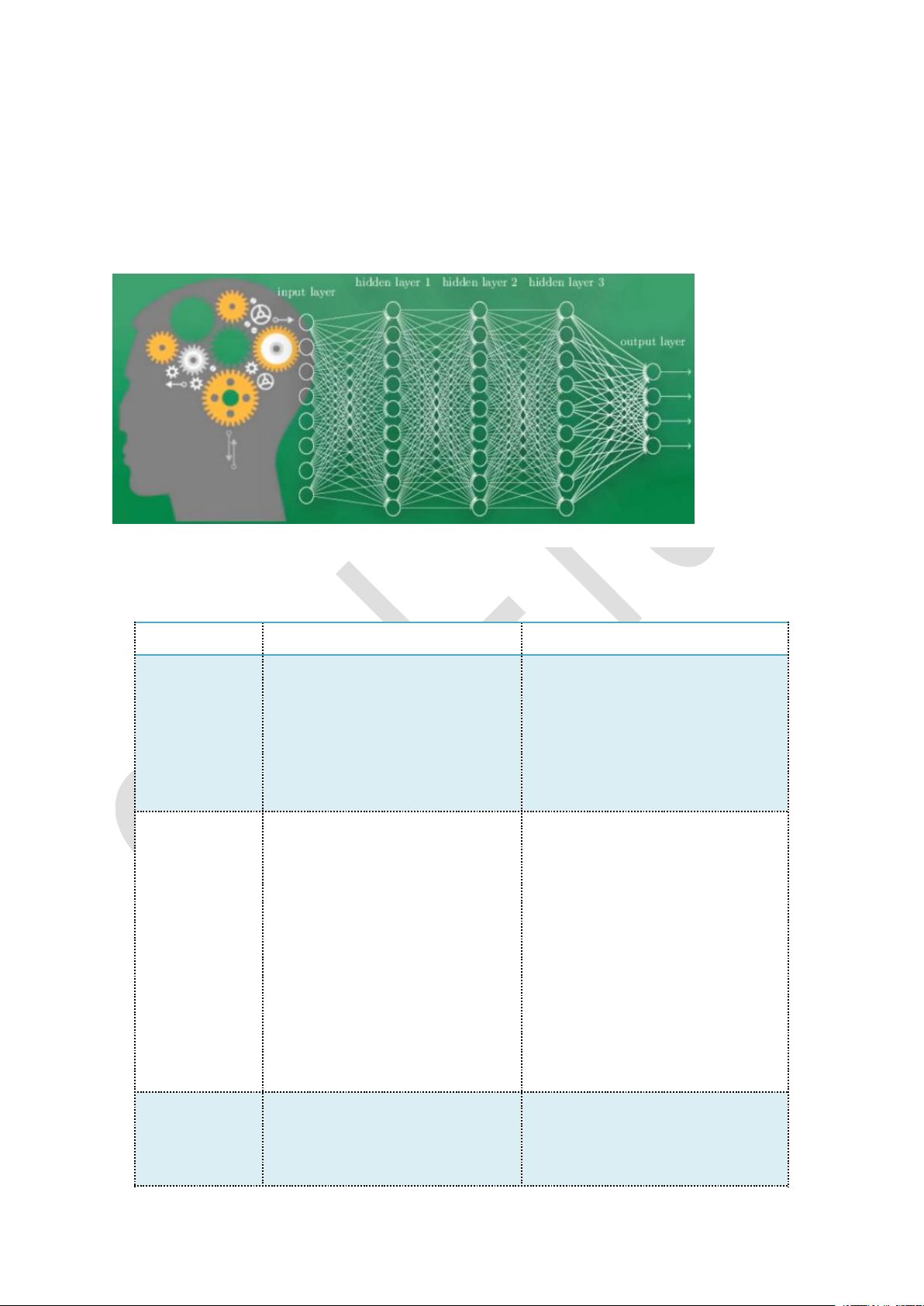
在机器学习和深度学习领域,扎实的数学基础至关重要。本资料首先阐述了标量、向量和张量的基本概念。标量是无方向的数值,如长度,只代表单一的量。向量则包含大小和方向,例如物理中的力,不仅有大小,还有朝向。而张量是更一般的概念,它可以是任意维度的数组,用来描述多维空间中的数据,如图像像素或多元统计数据。
张量与矩阵的关系在于,矩阵是二维张量的特例,可以视为一维向量的扩展。从代数角度看,矩阵是按行列排列的元素集合,而张量则扩展到了更多维度。几何上,矩阵和向量是不变量,不随坐标变换而改变。值得注意的是,尽管张量可以表示为矩阵,但其内涵更为广泛。
矩阵和向量的乘法运算遵循特定规则。当一个m行n列的矩阵与一个n维向量相乘时,结果是一个m维向量。这种乘法涉及每行矩阵元素与向量元素的逐个乘积之和。
向量和矩阵的范数是衡量其大小或强度的概念。对于向量,1范数是所有元素绝对值的和,2范数是元素平方和的平方根,相当于欧几里得距离,负无穷范数是最小绝对值,正无穷范数是最大绝对值。对于矩阵,1范数是所有列向量绝对值和的最大值,2范数是其转置与自身相乘后最大特征值的平方根,无穷范数是所有行向量绝对值和的最大值。
这些基础知识是理解机器学习和深度学习模型,如神经网络中权重矩阵、梯度计算、优化过程以及损失函数等核心概念的基础。掌握这些内容有助于深入探究复杂的机器学习算法和系统,从而进行有效的模型训练和预测。

16
4)举例,告诉一张包含气球的图片,需要得出气球在图片中的位置及气球和背景的分割
线,这就是已知弱标签学习强标签的问题。
在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。
在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习
是一个很热的话题。
2.3
监督学习有哪些步骤
监督式学习:
监督学习是使用已知正确答案的示例来训练网络。每组训练数据有一个明确的标识或结果,
想象一下,我们可以训练一个网络,让其从照片库中(其中包含气球的照片)识别出气球的照
片。以下就是我们在这个假设场景中所要采取的步骤。
步骤 1:数据集的创建和分类
首先,浏览你的照片(数据集),确定所有包含气球的照片,并对其进行标注。然后,将
所有照片分为训练集和验证集。目标就是在深度网络中找一函数,这个函数输入是任意一张照
片,当照片中包含气球时,输出 1,否则输出 0。
步骤 2:训练
选择合适的模型,模型可通过以下激活函数对每张照片进行预测。既然我们已经知道哪些
是包含气球的图片,那么我们就可以告诉模型它的预测是对还是错。然后我们会将这些信息反
馈(feed back)给网络。
该算法使用的这种反馈,就是一个量化“真实答案与模型预测有多少偏差”的函数的结果。
这个函数被称为成本函数(cost function),也称为目标函数(objective function),效用函数(utility
function)或适应度函数(fitness function)。然后,该函数的结果用于修改一个称为反向传播
(
backpropagation
)过程中节点之间的连接强度和偏差。
我们会为每个图片都重复一遍此操作,而在每种情况下,算法都在尽量最小化成本函数。
其实,我们有多种数学技术可以用来验证这个模型是正确还是错误的,但我们常用的是一
个非常常见的方法,我们称之为梯度下降(
gradient descent
)。
步骤 3:验证
当处理完训练集所有照片,接着要去测试该模型。利用验证集来来验证训练有素的模型是
否可以准确地挑选出含有气球在内的照片。
在此过程中,通常会通过调整和模型相关的各种事物(超参数)来重复步骤 2 和 3,诸如
里面有多少个节点,有多少层,哪些数学函数用于决定节点是否亮起,如何在反向传播阶段积
极有效地训练权值等等。

剩余366页未读,继续阅读
193 浏览量
291 浏览量
1136 浏览量
点击了解资源详情
点击了解资源详情
476 浏览量
2021-03-26 上传
462 浏览量
186 浏览量

lllzzr18
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 隐私数据清洗工具Java代码实践教程
- UML与.NET设计模式详细教程
- 多技术领域综合企业官网开发源代码包及使用指南
- C++实现简易HTTP服务端及文件处理
- 深入解析iOS TextKit图文混排技术
- Android设备间Wifi文件传输功能的实现
- ExcellenceSoft热键工具:自定义Windows快捷操作
- Ubuntu上通过脚本安装Deezer Desktop非官方指南
- CAD2007安装教程与工具包下载指南
- 如何利用Box平台和API实现代码段示例
- 揭秘SSH项目源码:实用性强,助力开发高效
- ECSHOP仿68ecshop模板开发中心:适用于2.7.3版本
- VS2012自定义图标教程与技巧
- Android新库Quiet:利用扬声器实现数据传递
- Delphi实现HTTP断点续传下载技术源码解析
- 实时情绪分析助力品牌提升与趋势追踪:交互式Web应用程序
