HBase性能优化实践:从表设计到调优策略
版权申诉
PDF格式 | 519KB |
更新于2024-07-08
| 192 浏览量 | 举报
"Hbase性能优化百科全书,涵盖了Hbase在表设计、rowkey设计、内存管理、读写操作及配置等方面的调优实践,旨在帮助读者理解和应用Hbase的优化技术,适用于处理大规模读写流量的场景。"
在深入探讨Hbase性能优化之前,首先理解Hbase的基础特性至关重要。Hbase是一个基于HDFS的分布式列式存储系统,具备高可靠性和高性能,尤其适合非结构化数据的存储。其优点包括海量存储能力、列式存储模式、出色的扩展性、高并发处理以及数据的稀疏性。
1. **海量存储**:Hbase能处理PB级别的数据,通过分布式存储和内存缓存机制,能在短时间内响应查询请求,提供快速的数据访问。
2. **列式存储**:数据按列族组织,列族在创建时定义,列可以在运行时动态添加,这种设计有利于压缩和只读取所需数据,提高读取效率。
3. **极易扩展**:Hbase可以通过增加RegionServer节点提升处理能力,同时利用HDFS的扩展性增加存储容量。
4. **高并发**:尽管单个I/O操作可能有几十到上百毫秒的延迟,但Hbase在高并发环境下能保持较低的延迟增长,确保系统的整体吞吐量。
5. **稀疏性**:Hbase的列可以根据需求自由增删,空值不占用存储空间,降低了存储成本。
**性能优化策略**
**表的设计**:表预分区是一种重要的设计策略,避免因数据分布不均导致的Region不平衡。预分区可以在表创建时预先划分多个Region,随着数据增长,这些Region会自动分裂,减少热点现象,提高读写性能。
**Rowkey设计**:Rowkey是Hbase的主键,决定了数据的物理存储位置和访问效率。优化Rowkey设计应考虑以下原则:保持Rowkey有序,利于数据分布;避免热点,通过散列或时间戳等方式分散数据;考虑查询模式,使常见查询能快速定位。
**内存管理**:调整Hbase的Memstore大小和数量,平衡内存使用和磁盘I/O。Memstore是内存中的数据缓冲区,合理设置能提高写入速度并减少Region分裂。
**读写优化**:优化Get和Scan操作,避免全表扫描;使用批量操作如Put和Bulk Load提升写入性能;合理使用布隆过滤器和二级索引来减少不必要的磁盘访问。
**配置调优**:根据集群硬件和工作负载调整Hbase的各种配置参数,如HDFS副本数、RegionServer的线程池大小、Blocksize等,以最大化性能。
在实际应用中,监控和分析Hbase的性能指标也是必不可少的步骤,例如RegionServer的负载、Memstore使用情况、RPC延迟等,这些数据能帮助我们识别瓶颈并进行针对性优化。此外,持续关注Hbase社区的新特性和最佳实践,及时更新版本,也能进一步提升系统的性能和稳定性。
Hbase性能优化是一个涉及多个层面的综合过程,需要结合具体业务场景,从表设计、数据模型、内存管理、读写操作及系统配置等多个角度进行精细化调整。通过不断的学习和实践,我们可以构建出一个高效、稳定的大数据存储系统,应对大规模读写流量的挑战。
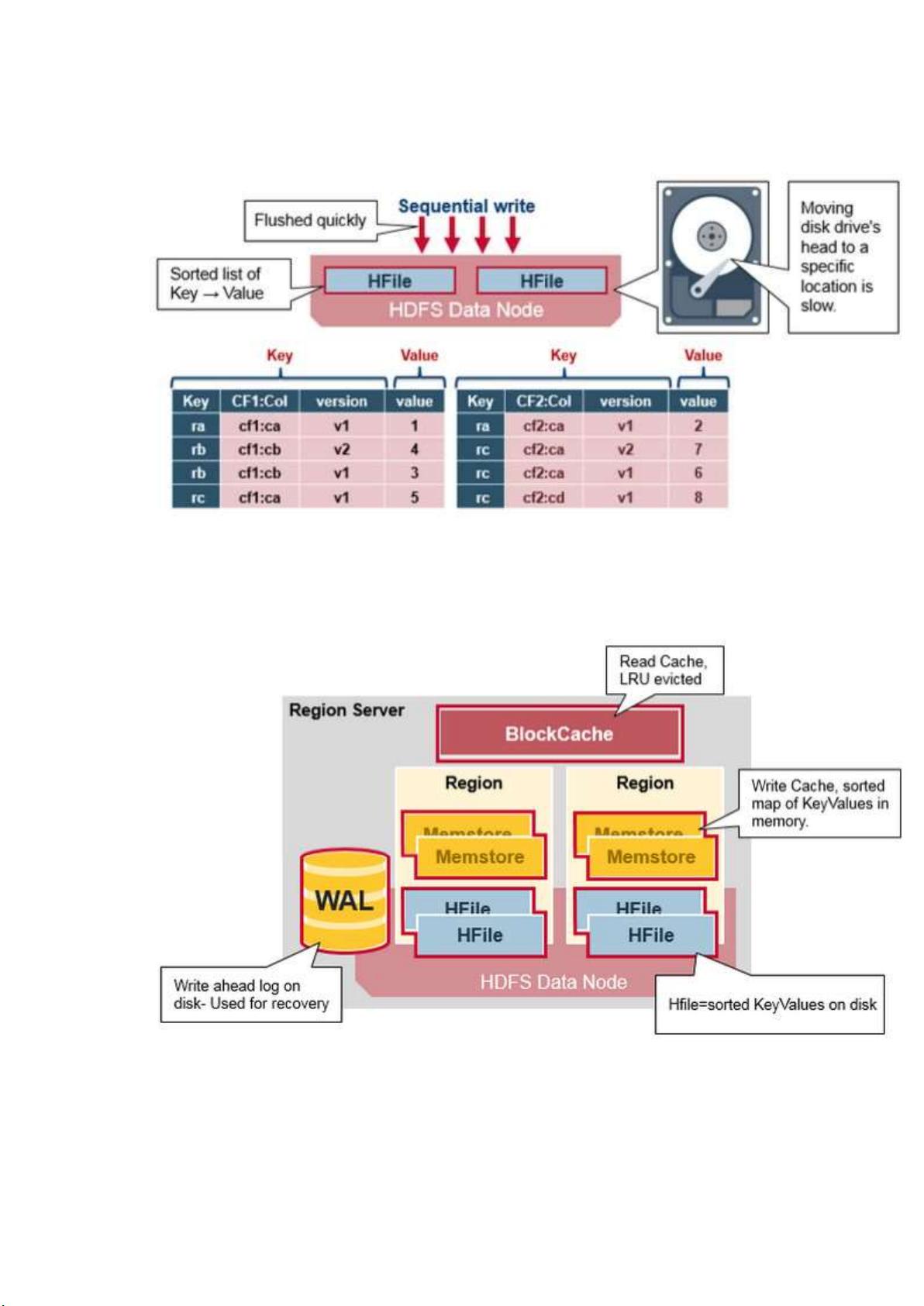
间,会影响 HFile 的存储效率。
HBase 中设计有 MemStore 和 BlockCache,分别对应列族/Store 级别的写入缓
存,和 RegionServer 级别的读取缓存。如果 RowKey 过长,缓存中存储数据的
密度就会降低,影响数据落地或查询效率。
另外,我们目前使用的服务器操作系统都是 64 位系统,内存是按照 8B 对齐
的,因此设计 RowKey 时一般做成 8B 的整数倍,如 16B 或者 24B,可以提高寻
址效率。
同样地,列族、列名的命名在保证可读的情况下也应尽量短。HBase 官方不推
剩余19页未读,继续阅读
相关推荐











