大规模电商产品爬取与跟踪技术
需积分: 10 98 浏览量
更新于2024-07-19
收藏 3.03MB PDF 举报
"Crawling and Tracking Millions of eCommerce Products at Scale 是一篇关于大规模抓取和追踪电子商务产品信息的讨论,由Qiaoliang Xiang,一位数据科学负责人所撰写。文章探讨了如何灵活且可扩展地爬取电商网站的数据,并构建一个能够处理大量商品信息的系统。"
在电商行业,数据的获取和跟踪是至关重要的,因为这可以帮助企业了解市场动态、竞争对手的行为以及消费者偏好。这篇论文首先介绍了问题所在:如何有效地爬取海量的产品信息?作者指出,目标在于构建一个既灵活又能随业务增长而扩展的爬虫系统。
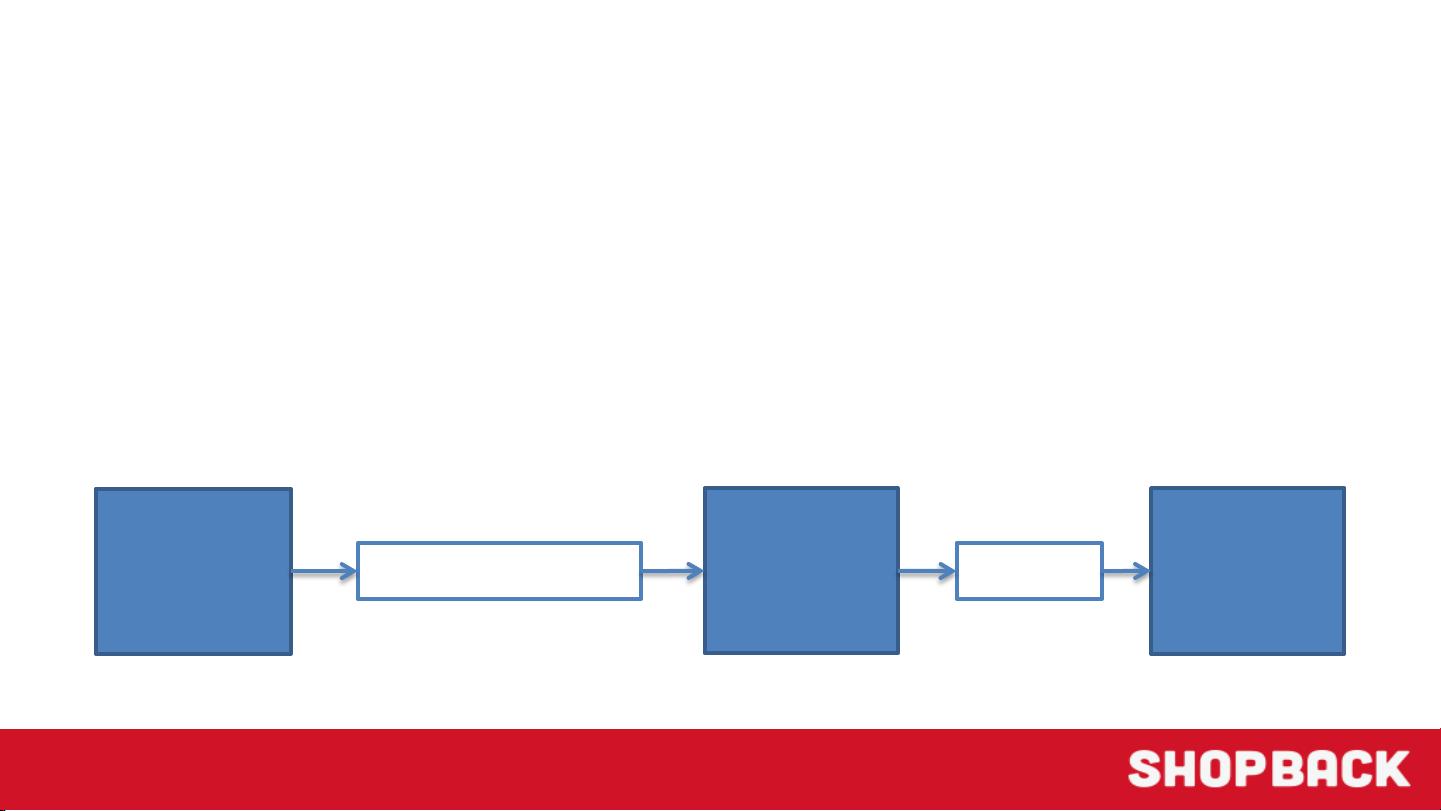
爬取过程主要分为三个步骤:
1. **Traversal(遍历)**:这个阶段涉及到如何遍历电商网站,获取产品链接。通过种子URL开始,系统会抓取页面,提取其中的链接,同时去除重复和已访问过的链接,以确保高效和准确的遍历。
2. **Fetch(抓取)**:一旦得到产品链接,系统将抓取对应的产品页面,通常是HTML形式。这一阶段的目标是从网页中获取产品数据,包括价格、描述、图片等。
3. **Extract(提取)**:提取阶段是对抓取的HTML进行解析,从中抽取关键的产品信息。由于不同电商网站的结构可能各异,因此需要设计一种域独立的工作流程,即能够适应各种网站布局的提取策略。
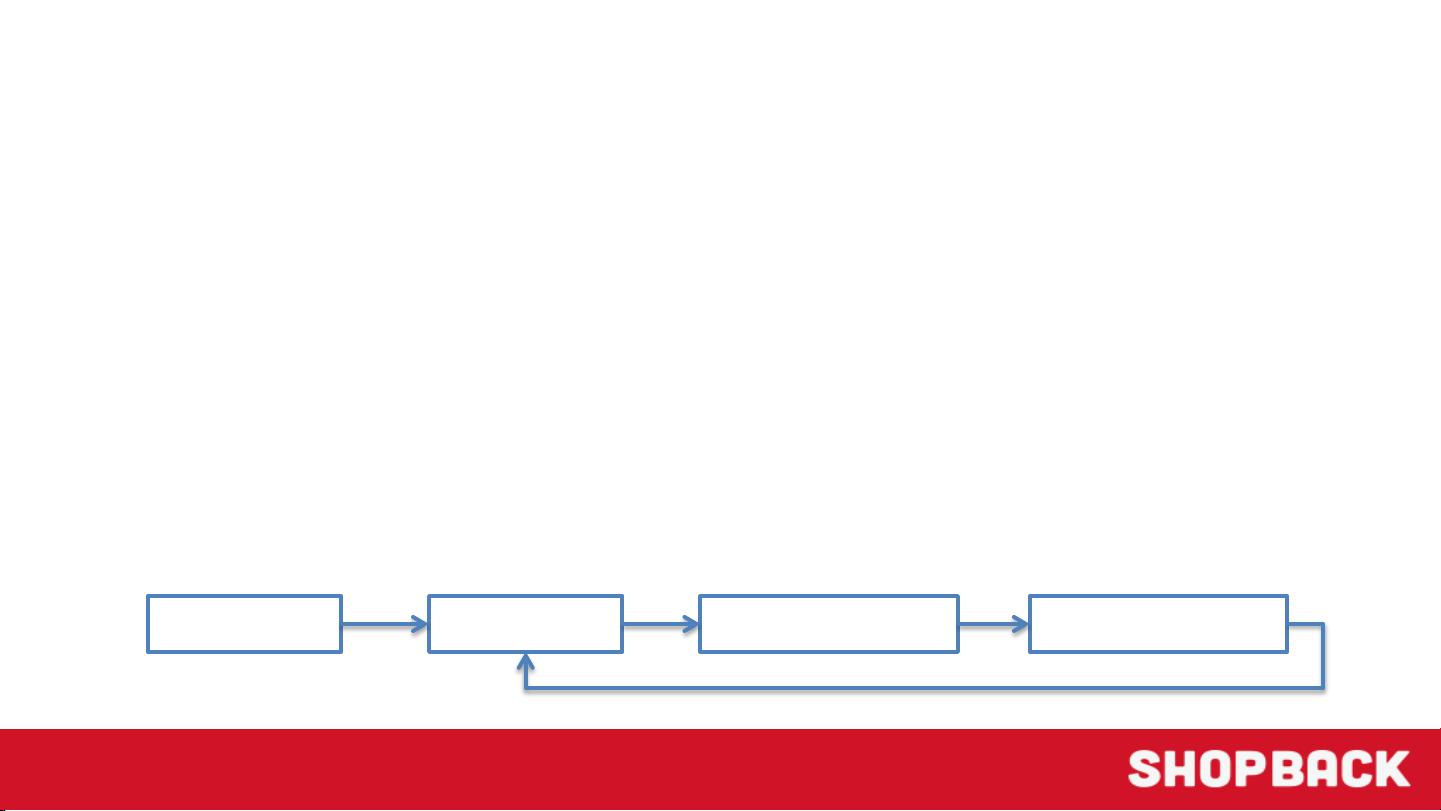
在实现域独立的工作流程中,系统需要处理种子URL,获取HTML页面,然后提取链接。而在域依赖的工作流程中,系统更专注于遍历产品链接,抓取产品页面,最终提取出具体的产品信息,如品牌、型号、库存状态等。
对于大规模的电商数据爬取,还需要考虑以下几个关键点:
- **反爬机制**:电商网站往往有反爬策略,比如IP限制、验证码等,因此爬虫需要能够处理这些问题,可能需要使用代理IP池、验证码识别技术等。
- **数据清洗与存储**:抓取到的数据可能包含噪声和不完整信息,需要进行清洗和预处理。同时,存储大量数据需要高效的数据存储解决方案,如分布式数据库或大数据处理框架。
- **实时性与更新**:产品信息实时变化,因此系统需要有能力定期更新数据,追踪产品的价格变动、库存状态等。
- **法律合规**:在进行数据爬取时,必须遵守各国家和地区的网络使用法规,尊重网站的robots.txt文件,避免非法抓取。
通过这样的系统设计和实施,可以实现对电商产品信息的大规模抓取和跟踪,为企业提供有价值的市场洞察,支持决策制定,优化运营策略,甚至推动创新业务模式的发展。
K/"-L/$)E);/3#&')C'*2?2'*2'6)
• K/"-L/$)
– +"#J2"02)$2@0&62)#'*)126,>):+.Q0)
– MI6"#,6)?"/*5,60)O*/3#&')-'/$%2*(2R)
K2@0&62)
+"#J2"02)S)H26,>)
:+.Q)
76/"2)
4"/*5,6)
76/"2)
MI6"#,6)
剩余47页未读,继续阅读
点击了解资源详情
612 浏览量
点击了解资源详情
2021-05-12 上传
2021-03-14 上传
169 浏览量
2023-07-27 上传
127 浏览量
2022-01-02 上传

frzhen77
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- QCo-editor:跨平台Cocos2d-x开源编辑器
- cocos2d-x 2.14版本SneakyJoystick API修改详解
- 石材辅助工具1.0快捷键RC自动编号功能评测
- 蚁群算法C语言实现及详细解析
- 将SQL数据高效转换为XML格式的方法
- C#实现RSA加密算法的示例教程
- dot_vim:Champion Champion的Vim插件和配置管理指南
- SSH框架人力资源系统开发指南
- 使用qt进行串口通信测试的方法与实践
- React封装Ladda按钮:加载指示器实现指南
- 云数据库CouchDB与Cloudant搜索的Docker集成实现
- 蚁群算法在VB中的实现及详细解析
- Easyxy图形界面实现Devcpp学生管理系统
- 飞凌-MX6UL GPS模块测试流程与连接指南
- MAYA建模插件精选合集:提升3D建模效率
- 无需权限的PHP文件上传模块实现
