Hadoop分布式文件系统HDFS详解
"该资源是关于分布式文件系统HDFS的讲解,由星环科技的范颖捷于2018年11月分享。主要内容涵盖了HDFS的基本介绍、设计目标、优缺点,以及HDFS的工作原理,包括系统架构、存储机制、读写操作等核心知识点。"
Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的核心组成部分,它是一个开源的分布式文件系统,旨在处理和存储大规模数据集。HDFS的设计灵感来源于Google的GFS论文,其目标是在大量低成本商用机器上运行,提供高容错性和高可用性。
HDFS具有以下设计目标:
1. 容错性:HDFS预期硬件故障是常态,因此它通过数据冗余多副本来保证容错性,当副本丢失时可以自动恢复。
2. 简单一致性模型:数据一旦写入,就只能读取,支持追加但不支持修改,以确保数据一致性。
3. 流式数据访问:优化批量读取,关注系统吞吐量而不是单个操作的时间。
4. 大规模存储:支持GB到TB级别的文件,以及PB级别的数据存储,并且可以通过增加节点实现横向扩展。
HDFS的主要优点包括:
1. 高容错性和高可用性:通过副本策略和NameNode的HA(High Availability)确保系统的稳定运行。
2. 海量数据存储能力:适合存储大型文件和海量数据。
3. 构建成本低:基于廉价硬件,同时具备故障恢复机制。
4. 适合大规模离线批处理:数据位置暴露给计算框架,优化批处理性能。
然而,HDFS也存在一些局限性:
1. 不适合低延迟数据访问:HDFS优化了批量读取,而非快速响应单个请求。
2. 对小文件存储效率低:小文件会导致NameNode的元数据管理压力增大。
3. 不支持并发写入:一个文件在同一时间只能有一个写入者。
4. 不支持文件随机修改:只允许追加写入,不支持任意位置的修改。
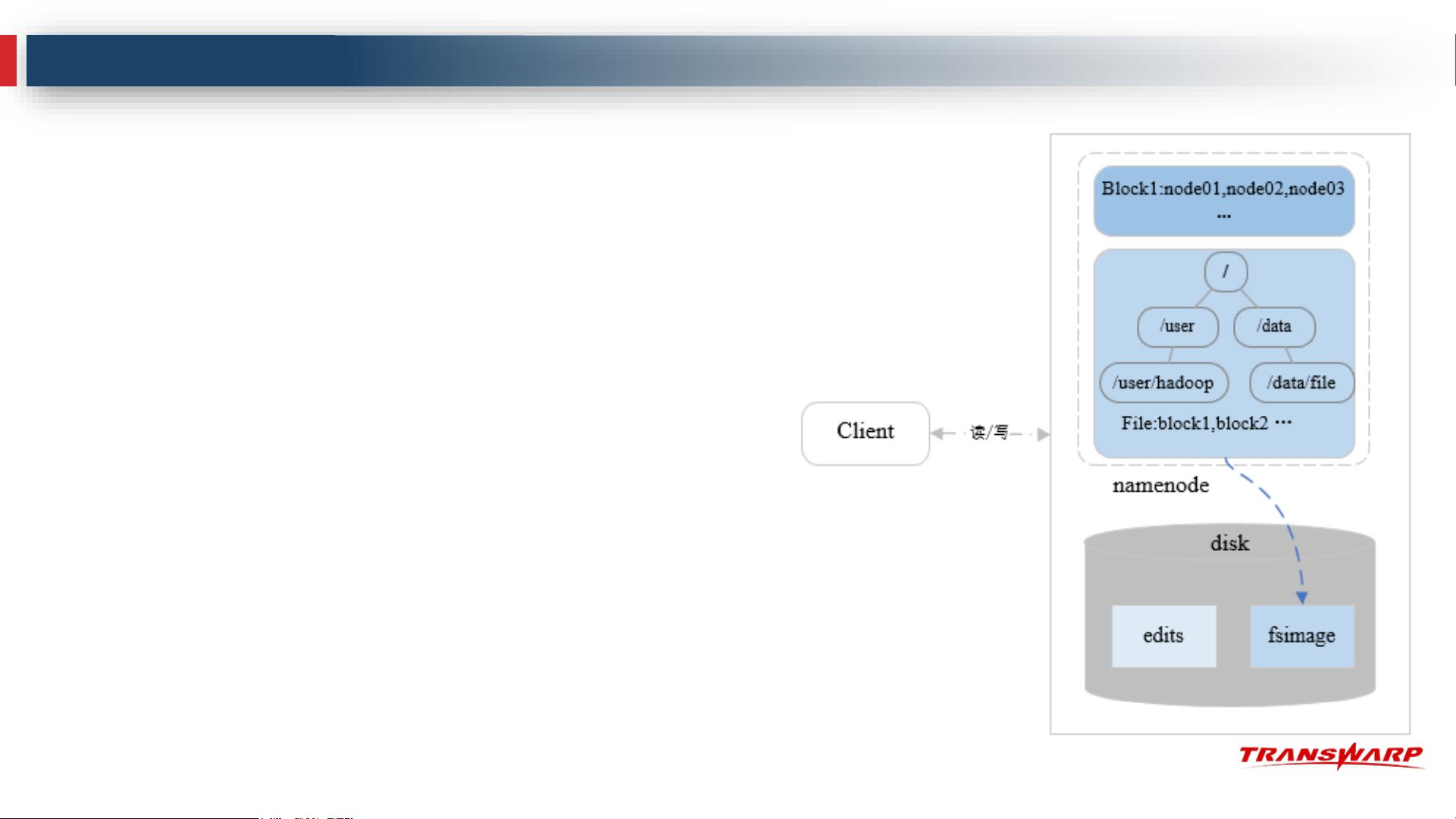
HDFS的系统架构采用主从(Master/Slave)结构,由NameNode(主节点)和DataNode(从节点)组成。NameNode负责元数据管理,DataNode则实际存储数据。读写操作涉及到客户端与NameNode的通信,以确定数据块的位置,然后直接与相关的DataNode进行数据传输。安全模式是HDFS的一种状态,在此状态下,系统不允许数据修改,直到足够数量的数据块副本被确认。高可用性通过设置备用NameNode实现,当主NameNode故障时,备用NameNode可以无缝接管。
HDFS是大数据处理领域的重要基石,尤其适用于需要处理大量数据的离线分析任务。尽管它在某些场景下表现不尽如人意,但其在大规模数据存储和处理上的优势使其成为许多企业选择的解决方案。
星 环 科 技
HDFS原理
2.1 系统架构:基本概念
Active NameNode(AN)
• 活动Master管理节点(集群中唯一)
• 管理命名空间
• 管理元数据:文件的位置、所有者、权限、数据块等
• 管理Block副本策略:默认3个副本
• 处理客户端读写请求,为DataNode分配任务
Standby NameNode(SN)
• 热备Master管理节点(Active NameNode的热备节点)
-Hadoop 3.0允许配置多个Standby NameNode
• Active NameNode宕机后,快速升级为新的Active
• 周期性同步edits编辑日志,定期合并fsimage与edits到本地磁盘


剩余50页未读,继续阅读
相关推荐


cntaizi
- 粉丝: 15
 我的内容管理
展开
我的内容管理
展开








最新资源
- 擎天科技JAVA笔试题解析与解答
- STM32-USART2控制舵机控制板教程
- 提升接待技能:国外客户接待实用技巧分享
- AI图片处理插件:一键美化照片技术
- STM32F103C8T6最小系统原理图及PCB库下载
- DOPDropDownMenu:自定义下拉菜单功能的实现
- TeeChart三维散点动态显示教程与示例
- 实现仿微信语音播放功能的jQuery mp3播放代码
- MATLAB程序:最小二乘法拟合圆曲线教程
- Python客户端新闻API接口教程与应用
- 实用劳动关系管理教案,挖掘潜能,提升参考价值
- i-SpectrAnalysis_BullsPower MetaTrader 5脚本详解
- STM32系列逆变器控制板设计与应用
- 深层强化学习网络结构及其源码解析
- 实现图片背景的jQuery鼠标滑动切换效果
- 易语言实现163邮箱自动登录功能
