一维与多维梯度下降详解:降低函数值的优化策略
131 浏览量
更新于2024-08-28
收藏 180KB PDF 举报
在"动手学深度学习(七) 梯度下降"这一章节中,我们深入探讨了梯度下降这一核心优化算法在深度学习中的应用。梯度下降是求解最小化或最大化的函数问题时,最常用的一种数值优化方法,它源自微积分的基本概念,尤其是泰勒级数展开。在这个教程中,作者通过Python的PyTorch库进行实例演示。
首先,一维梯度下降的原理是基于函数的梯度信息来调整参数。我们通过一个简单的例子来证明,沿着函数梯度的负方向移动自变量x,函数值会逐渐减小。例如,定义函数f(x) = x^2,其导数gradf(x) = 2x。函数gd(eta)使用固定的学习率eta,通过迭代更新x值,每次减去梯度乘以eta,如gd(0.2)所示,可以看到随着学习率的减小,函数在接近局部最小值处收敛得更慢,如gd(0.05)和gd(1.1)的结果对比。
接着,作者引入了局部极小值的概念,通过一个非线性函数f(x) = x * cos(c * x),当初始学习率过大(如gd(2))时,可能会导致算法陷入局部极小值而不是全局最小值。这表明在选择学习率时需要谨慎,因为它直接影响到搜索过程的效率和结果质量。
进一步,章节扩展到了多维梯度下降,这在处理具有多个输入变量的复杂模型时尤为关键。在多维空间中,梯度下降寻找的是函数值下降最快的方向,通常涉及到向量化的梯度计算和更新。这个过程可能涉及到梯度下降的变种,如批量梯度下降、随机梯度下降或动量梯度下降,它们分别考虑了所有数据点、单个数据点或结合过去梯度信息来改进更新策略。
总结来说,本章通过具体的代码示例和理论阐述,讲解了梯度下降的基本概念、一维和多维应用,以及学习率对优化过程的影响。对于理解深度学习模型的训练过程,特别是优化算法的选择和调整,这部分内容至关重要。掌握梯度下降算法不仅有助于提升模型性能,也是成为高效数据科学家的必备技能。
动手学深度学习动手学深度学习(七七) 梯度下降梯度下降
梯度下降梯度下降
(Boyd & Vandenberghe, 2004)
%matplotlib inline
import numpy as np
import torch
import time
from torch import nn, optim
import math
import sys
sys.path.append('/home/kesci/input')
import d2lzh1981 as d2l
一维梯度下降一维梯度下降
证明:沿梯度反方向移动自变量可以减小函数值证明:沿梯度反方向移动自变量可以减小函数值
泰勒展开:
代入沿梯度方向的移动量 :
e.g.
def f(x):
return x**2 # Objective function
def gradf(x):
return 2 * x # Its derivative
def gd(eta):
x = 10
results = [x] for i in range(10):
x -= eta * gradf(x)
results.append(x)
print('epoch 10, x:', x)
return results
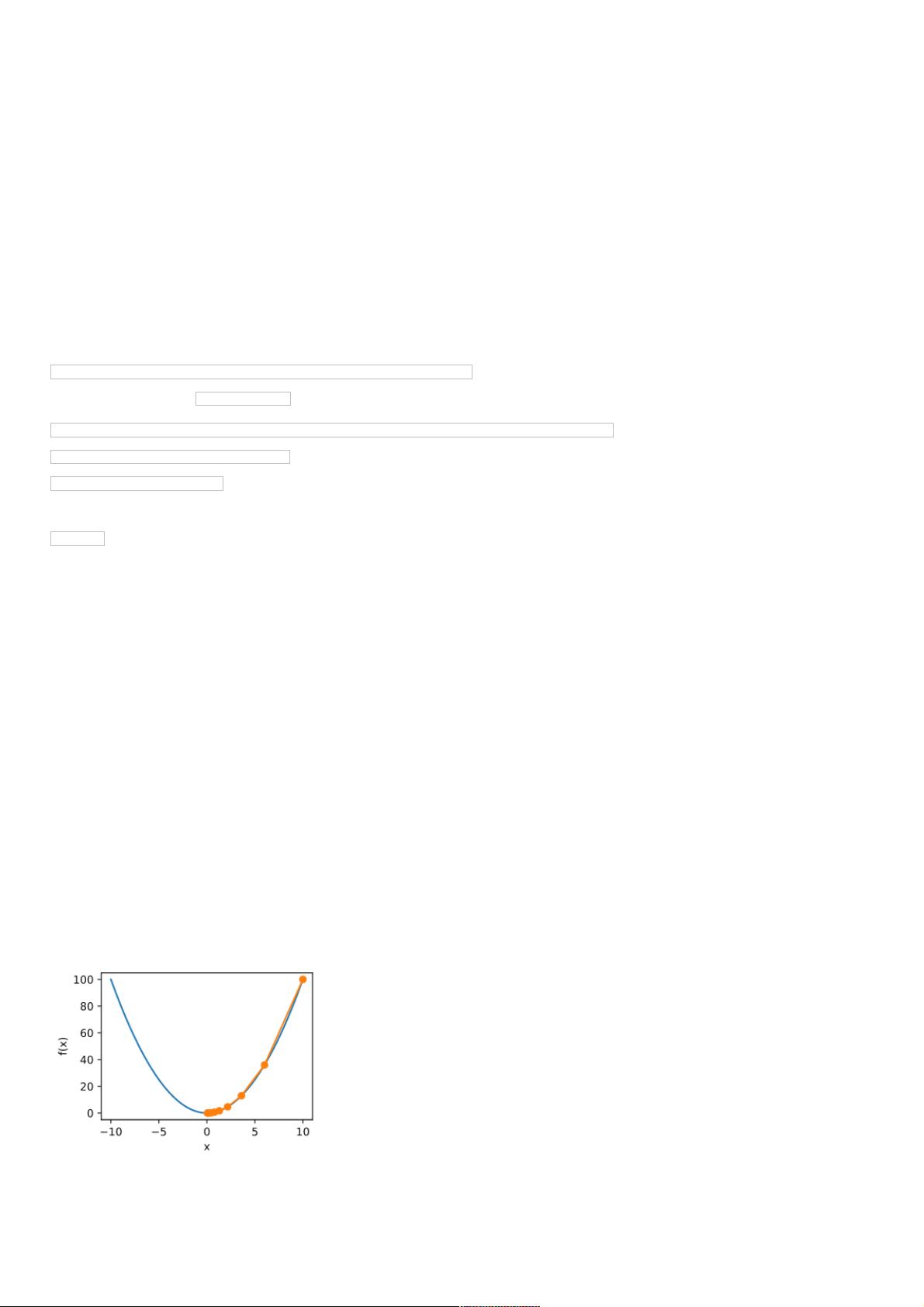
res = gd(0.2)
epoch 10, x: 0.06046617599999997
def show_trace(res):
n = max(abs(min(res)), abs(max(res)))
f_line = np.arange(-n, n, 0.01)
d2l.set_figsize((3.5, 2.5))
d2l.plt.plot(f_line, [f(x) for x in f_line],'-')
d2l.plt.plot(res, [f(x) for x in res],'-o')
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)')
show_trace(res)
学习率学习率
show_trace(gd(0.05))
epoch 10, x: 3.4867844009999995
下载后可阅读完整内容,剩余7页未读,立即下载
1484 浏览量
2897 浏览量
335 浏览量
373 浏览量
2024-05-08 上传
2024-05-08 上传
103 浏览量
124 浏览量
623 浏览量

weixin_38598703
- 粉丝: 2
- 资源: 905
 我的内容管理
展开
我的内容管理
展开







最新资源
- 驱动器:用于数据存储和传输的android应用
- wheather-kotlin-app:应用Kotlin博物馆
- cse427:uw的计算生物学课程
- bash入门学习实例
- spacedesk安装包
- RTSP拉流软件显示.zip
- ReCapProject:租车计划
- spooky-authors-identification:该存储库介绍了我们在哥伦比亚大学IEOR 4523数据分析课程的背景下实现的项目中的工作
- 在WPF MVVM应用程序中使用IValueConverter选择UserControl / View
- 一次性电子邮件域
- 教育核算点财务管理考核方案
- USIM_Explorer.rar
- ucsf_www.ucsf.edu_tests:www.ucsf.edu 重新设计的测试场景
- DummyWebApp
- C语言期末作业——民航票务系统
- 电信设备-基于改进蚁群AODV协议的多机器人通信组网方法.zip
