Python选择语句详解:if, if/else, if/elif/else
版权申诉
37 浏览量
更新于2024-08-11
收藏 195KB PDF 举报
"Python的三种选择语句:if语句,if/else语句和if/elif/else语句是编程中的基础控制结构,用于实现程序的逻辑选择。本文通过流程图和示例代码详细解释了这些语句的工作原理和使用方法。"
Python语言提供了三种选择语句来实现条件分支,这三种语句分别是:
1. **if语句**:这是最基础的选择语句,用于检查一个条件,如果条件为真,则执行相应代码块。其基本语法结构如下:
```python
if 条件表达式:
语句体
```
当条件表达式的结果为True时,`语句体`会被执行。如果条件不满足,程序会跳过`语句体`继续执行后面的代码。
2. **if/else语句**:在if语句的基础上增加了else子句,当条件不满足时执行另一段代码。语法结构如下:
```python
if 条件表达式:
语句体1
else:
语句体2
```
如果条件表达式为True,执行`语句体1`;否则执行`语句体2`。这种结构提供了两种可能的执行路径。
3. **if/elif/else语句**:这是一种更复杂的条件选择,可以检查多个条件,直到找到满足的条件并执行对应的代码。语法结构如下:
```python
if 条件表达式1:
语句体1
elif 条件表达式2:
语句体2
...
elif 条件表达式n:
语句体n
else:
语句体n+1
```
这里,程序会依次检查每个`条件表达式i`,如果有一个条件满足,就执行对应的`语句体i`,并且不再检查后续的条件。如果没有条件满足,最后执行`else`后的`语句体n+1`。
在Python中,语句体的代码块通常通过统一的缩进来表示。如果多行代码属于同一个语句体,它们需要在同一缩进级别下。这是Python语法的一个关键特性,也是其可读性高的原因之一。
例如,以下是一个使用if语句的简单程序,它接收用户输入的整数,并根据数值大小打印不同的消息:
```python
# -*-coding: cp936-*-
# 比较输入的整数是否大于6
integer = int(input('请输入一个整数:')) # 获取一个整数
if integer > 6:
print('输入的数字大于6')
else:
print('输入的数字不大于6')
```
这个程序首先获取用户输入的整数,然后检查这个数是否大于6。如果是,它会输出“输入的数字大于6”;否则,输出“输入的数字不大于6”。
掌握if、if/else和if/elif/else语句是编写复杂Python程序的基础。通过组合这些控制结构,开发者可以创建出适应各种逻辑需求的程序。在实际编程中,这些语句经常与其他结构(如循环、函数等)结合使用,以实现更复杂的逻辑控制。
print '%d 大于 6' %integer
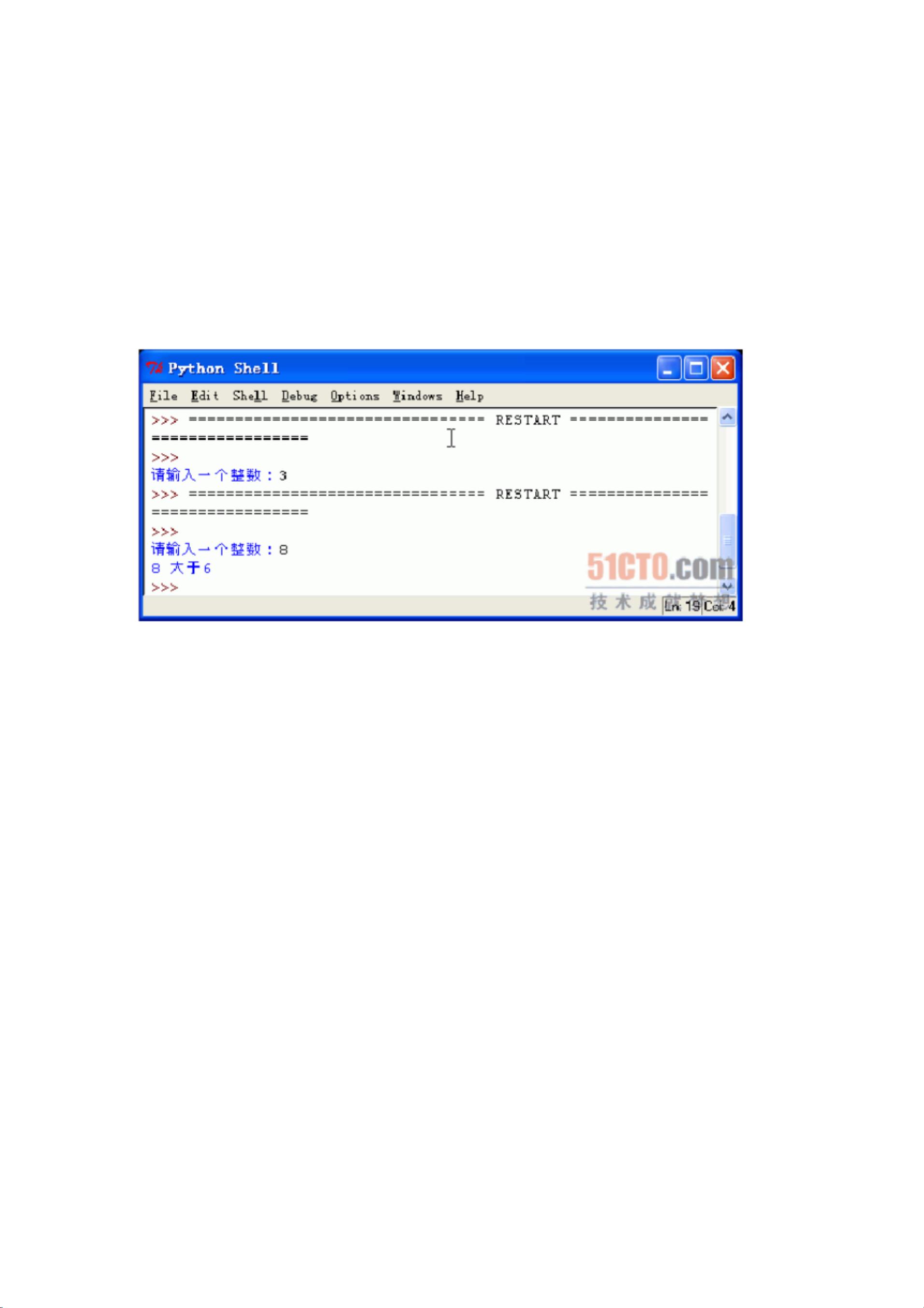
当我们在 IDEL 中运行该程序时,结果如下所示:
图 2 if 语句示例程序运行结果
我们看到,如果输入的数字不大于 6 时,程序马上退出,也就是说,下列代码
print '%d 大于 6' %integer
并没有执行;如果输入的数字大于 6,才会执行上面的这行代码,以打印一行文字。
三、 if/else 语句
上面的 if 语句是一种单选结构, 也就是说,如果条件为真 (即表达式的值为非零) ,那么执
行指定的操作; 否则就会跳过该操作。所以, 它选择的是做与不做的问题。 而 if/else 语句
剩余13页未读,继续阅读
197 浏览量
263 浏览量
278 浏览量
2021-09-30 上传
396 浏览量

cailibin
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Eclipse整合开发工具基础教程中文版
- 深入理解Struts架构与标签库
- CGLIB在Hibernate底层技术中的应用详解
- 深入理解Java Web中的session机制
- Spring框架中的属性配置与自动绑定详解
- 使用Token机制防止重复提交
- HTML中id与name的特性与差异解析
- Java图像处理:裁剪、缩放与灰度转换技巧
- Java反射机制详解与应用
- JavaBean事件处理:机制与应用场景
- SQL基础教程:操作数据与数据库管理
- Compiere ERP&CRM安装指南:Oracle数据库版
- UWB无线传感器网络:技术与应用
- Hibernate入门指南:环境配置与持久化映射详解
- 《Div+CSS布局大全》教程概述
- JSP 2.1官方规范:Java服务器页面开发指南
