最大熵模型教程:条件估计与优化
需积分: 9 32 浏览量
更新于2024-07-19
1
收藏 10.28MB PDF 举报
"这篇教程是关于最大熵模型的,由斯坦福大学的Dan Klein和Chris Manning主讲,曾在HLT-NAACL2003和ACL2003会议上进行过分享。教程强调了数学在理解最大熵模型中的重要性,而非依赖于魔法般的直觉。"
最大熵模型是一种在自然语言处理、信息检索和语音识别领域广泛应用的条件概率模型。近年来,这些模型因其高精度表现、便于融入大量具有语言学意义的特征以及支持自动构建语言独立且可重定向的NLP模块而备受青睐。
在统计自然语言处理中,模型分为两种主要类型:联合(生成)模型和条件(判别)模型。联合模型,如n-gram模型、朴素贝叶斯分类器、隐马尔科夫模型和概率上下文无关文法,它们为观察数据及其隐藏信息共同赋予权重,即生成观察数据。而条件模型则假设数据已知,然后在给定数据的情况下对隐藏结构分配概率,如逻辑回归、条件逻辑线性模型、最大熵马尔科夫模型,以及支持向量机和感知机。
最大熵模型,全称最大熵马尔科夫模型(MaxEnt Markov Model),是一种判别式模型。其基本思想是,在所有可能的概率分布中,选择一个熵最大的分布来建模,这种选择满足贝叶斯定理的边缘概率约束,同时最大化了模型的不确定性,即信息熵。在实际应用中,这意味着模型能够尽可能地保持对未知数据的中立,避免对未观察到的信息进行过度假设。
最大熵模型通过优化过程来确定模型参数,最常用的优化方法是梯度上升或Lagrange乘子法。这些方法确保模型在满足先验约束(如特征函数的期望值)的同时,使得模型的熵达到最大。在自然语言处理任务中,特征通常包括词性、句法结构、词汇共现等信息,通过最大化熵,模型可以平衡各种特征,避免对某些特征过于偏重。
此外,最大熵模型也可以被看作是逻辑回归模型的一个扩展,它允许使用非线性特征,从而在复杂问题上表现更优。最大熵模型在文本分类、命名实体识别、句法分析等任务中表现出色,能够有效地处理多类分类问题,并且容易融合各种特征,为解决实际问题提供了强大的工具。
总结来说,最大熵模型是通过数学方法而非直观直觉来理解和构建的模型,它在NLP领域扮演着重要角色,为许多关键任务提供了准确且灵活的解决方案。通过深入理解并熟练运用最大熵模型,我们可以更好地设计和实现自然语言处理系统。
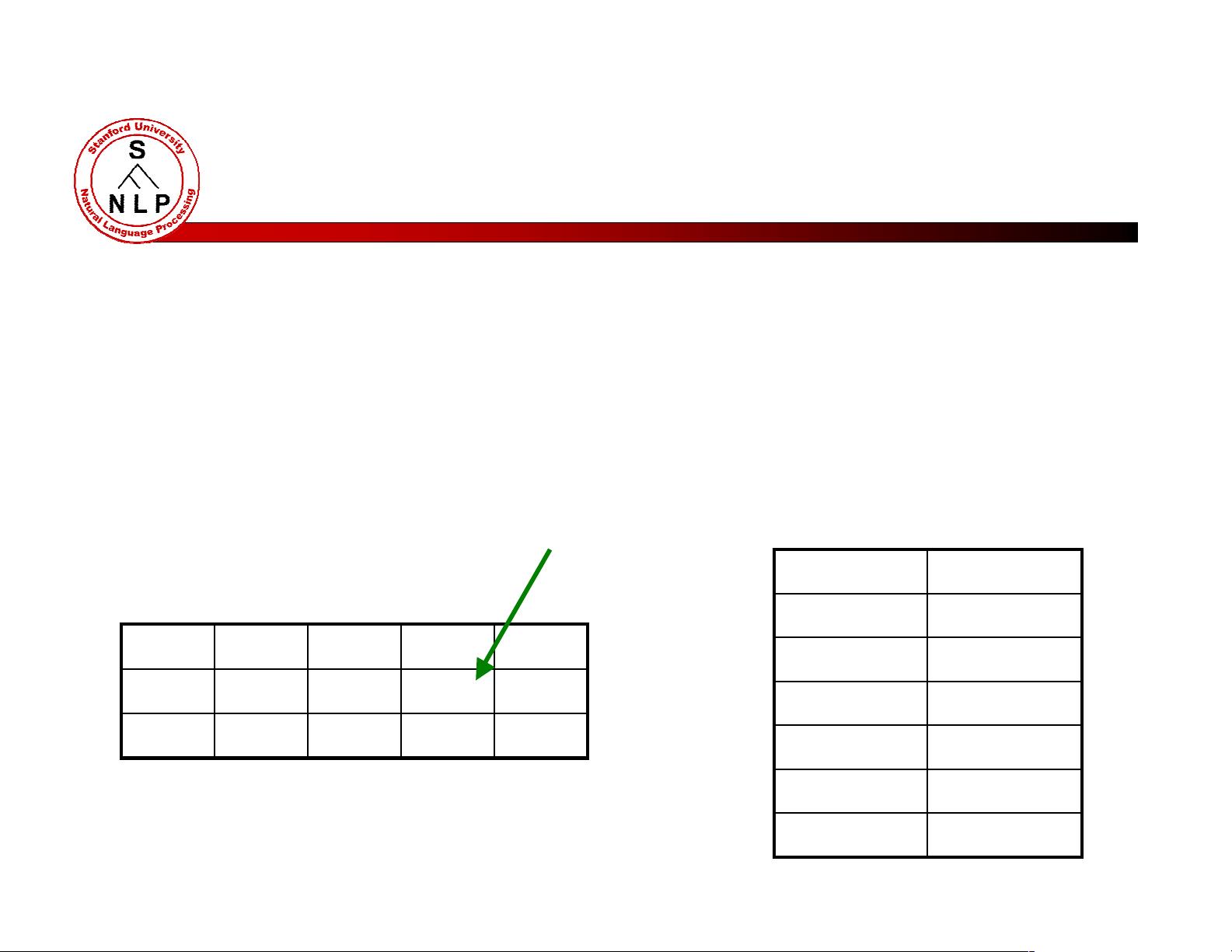
Example: Tagging
Features can include:
Current, previous, next words in isolation or together.
P revious ( or next) one, two, three tags.
W ord-internal f eatures: word ty pes, suf f ixes, dashes, etc .
%2 2 . 6f e l lD o wT h e
? ? ?? ? ?VBDN N PDT
+ 10-1-2-3
Local Context
F eatu r es
trueh a s D i g i t?
……
N N P -V B DT
-1
-T
-2
V B DT
-1
f el lW
-1
%W
+ 1
2 2 . 6W
0
D eci s i on P oi nt
( R a t n a p a r k h i 19 9 6 ; T o u t a n o v a e t a l . 2003, e t c . )


剩余118页未读,继续阅读
453 浏览量
407 浏览量
215 浏览量
1337 浏览量
239 浏览量
467 浏览量

mafanhe
- 粉丝: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
