基于U-Net的递归残差卷积神经网络在医学图像分割中的应用研究
需积分: 5 53 浏览量
更新于2024-08-03
1
收藏 1.73MB PDF 举报
基于U-Net的递归残差卷积神经网络(R2U-Net)在医学图像分割中的应用
基于U-Net的递归残差卷积神经网络(R2U-Net)是一种深度学习技术,应用于医学图像分割领域。该技术结合了U-Net、残差网络和递归卷积神经网络的优点,提高了医学图像分割的准确性和效率。
**U-Net技术**
U-Net是一种深度学习技术,广泛应用于图像分割领域。它的主要结构包括编码器和解码器,通过对称的编码器和解码器结构来实现图像的特征提取和分割。U-Net的优点在于可以对图像进行多尺度特征提取,提高图像分割的准确性。
**递归残差卷积神经网络(R2U-Net)**
R2U-Net是基于U-Net的递归残差卷积神经网络,结合了U-Net、残差网络和递归卷积神经网络的优点。该网络结构由多个递归残差卷积层组成,每个层都包含残差单元和递归卷积单元。残差单元可以帮助训练深度网络,提高网络的泛化能力。递归卷积单元可以accumulation特征,提高图像分割的准确性。
**R2U-Net的优点**
R2U-Net相比于传统的U-Net网络,具有多个优点。首先,残差单元可以帮助训练深度网络,提高网络的泛化能力。其次,递归卷积单元可以accumulation特征,提高图像分割的准确性。最后,R2U-Net可以设计更好的U-Net架构,具有相同数量的网络参数,达到更好的医学图像分割性能。
**医学图像分割**
医学图像分割是医学图像处理的关键步骤,旨在从医学图像中分离出感兴趣的目标区域。传统的图像分割方法主要基于thresholding、边缘检测和形态学操作等,但这些方法存在一定的局限性。基于深度学习的图像分割方法,如U-Net和R2U-Net,具有更高的准确性和效率,被广泛应用于医学图像分割领域。
**结论**
基于U-Net的递归残差卷积神经网络(R2U-Net)是一种高效的医学图像分割技术,结合了U-Net、残差网络和递归卷积神经网络的优点,提高了医学图像分割的准确性和效率。该技术具有广泛的应用前景,在医学图像处理领域具有重要的研究价值。
evaluated on different modalities of medical imagining as
shown in Fig. 1. The contributions of this work can be
summarized as follows:
1) Two new models RU-Net and R2U-Net are introduced for
medical image segmentation.
2) The experiments are conducted on three different
modalities of medical imaging including retina blood vessel
segmentation, skin cancer segmentation, and lung
segmentation.
3) Performance evaluation of the proposed models is
conducted for the patch-based method for retina blood vessel
segmentation tasks and the end-to-end image-based approach
for skin lesion and lung segmentation tasks.
4) Comparison against recently proposed state-of-the-art
methods that shows superior performance against equivalent
models with same number of network parameters.
The paper is organized as follows: Section II discusses related
work. The architectures of the proposed RU-Net and R2U-Net
models are presented in Section III. Section IV, explains the
datasets, experiments, and results. The conclusion and future
direction are discussed in Section V.
II. RELATED WORK
Semantic segmentation is an active research area where
DCNNs are used to classify each pixel in the image
individually, which is fueled by different challenging datasets
in the fields of computer vision and medical imaging [23, 24,
and 25]. Before the deep learning revolution, the traditional
machine learning approach mostly relied on hand engineered
features that were used for classifying pixels independently. In
the last few years, a lot of models have been proposed that have
proved that deeper networks are better for recognition and
segmentation tasks [5]. However, training very deep models is
difficult due to the vanishing gradient problem, which is
resolved by implementing modern activation functions such as
Rectified Linear Units (ReLU) or Exponential Linear Units
(ELU) [5,6]. Another solution to this problem is proposed by
He et al., a deep residual model that overcomes the problem
utilizing an identity mapping to facilitate the training process
[26].
In addition, CNNs based segmentation methods based on
FCN provide superior performance for natural image
segmentation [2]. One of the image patch-based architectures is
called Random architecture, which is very computationally
intensive and contains around 134.5M network parameters.
The main drawback of this approach is that a large number of
pixel overlap and the same convolutions are performed many
times. The performance of FCN has improved with recurrent
neural networks (RNN), which are fine-tuned on very large
datasets [27]. Semantic image segmentation with DeepLab is
one of the state-of-the-art performing methods [28]. SegNet
consists of two parts, one is the encoding network which is a
13-layer VGG16 network [5], and the corresponding decoding
network uses pixel-wise classification layers. The main
contribution of this paper is the way in which the decoder up-
samples its lower resolution input feature maps [10]. Later, an
improved version of SegNet, which is called Bayesian SegNet
was proposed in 2015 [29]. Most of these architectures are
explored using computer vision applications. However, there
are some deep learning models that have been proposed
specifically for the medical image segmentation, as they
consider data insufficiency and class imbalance problems.
One of the very first and most popular approaches for
semantic medical image segmentation is called “U-Net” [12].
A diagram of the basic U-Net model is shown in Fig. 2.
According to the structure, the network consists of two main
parts: the convolutional encoding and decoding units. The basic
convolution operations are performed followed by ReLU
activation in both parts of the network. For down sampling in
the encoding unit, 2×2 max-pooling operations are performed.
In the decoding phase, the convolution transpose (representing
up-convolution, or de-convolution) operations are performed to
up-sample the feature maps. The very first version of U-Net was
used to crop and copy feature maps from the encoding unit to
the decoding unit. The U-Net model provides several
advantages for segmentation tasks: first, this model allows for
the use of global location and context at the same time. Second,
it works with very few training samples and provides better
performance for segmentation tasks [12]. Third, an end-to-end
pipeline process the entire image in the forward pass and
directly produces segmentation maps. This ensures that U-Net
preserves the full context of the input images, which is a major
advantage when compared to patch-based segmentation
approaches [12, 14].
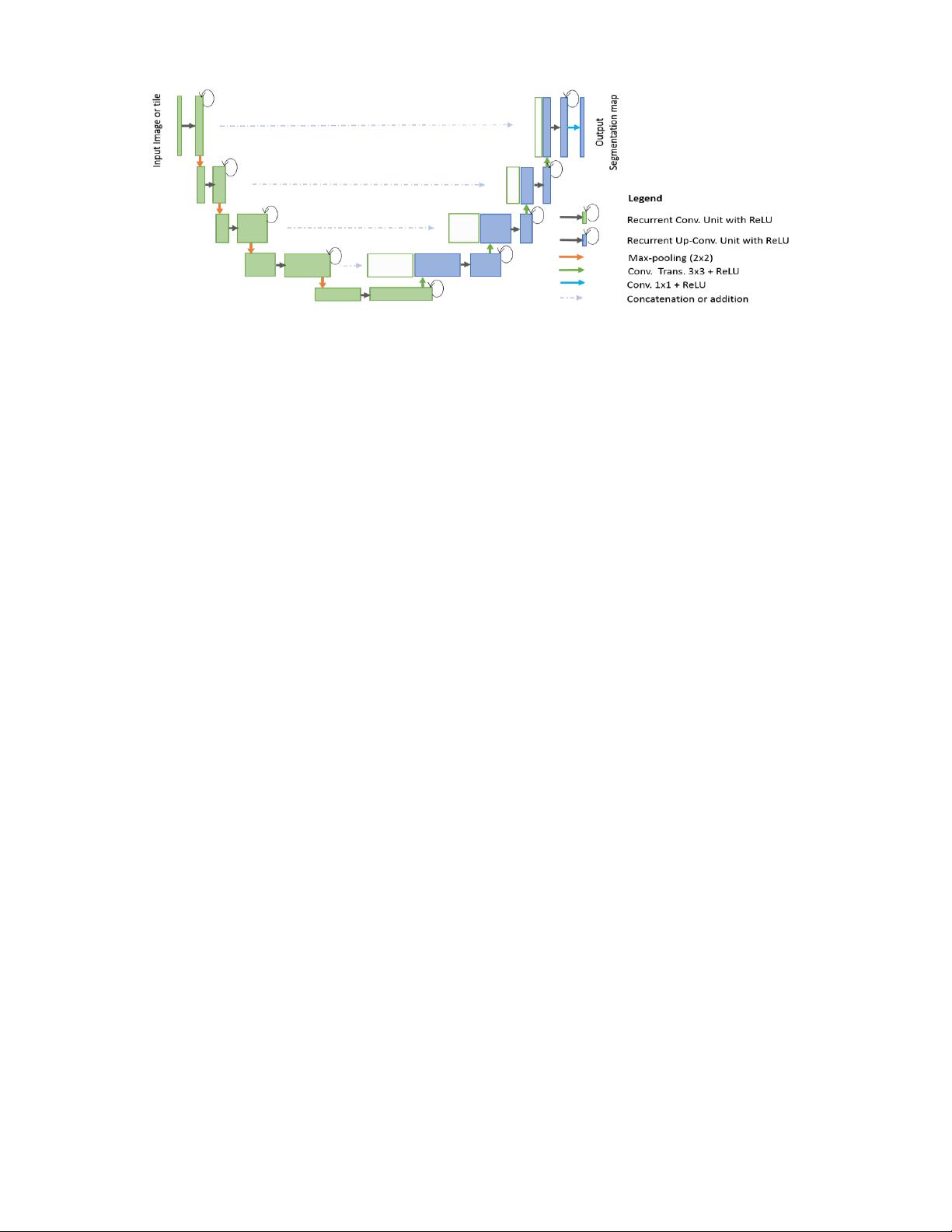
Fig. 3. RU-Net architecture with convolutional encoding and decoding units using recurrent convolutional layers (RCL) based U-Net architecture. The residual
units are used with RCL for R2U-Net architecture.
剩余11页未读,继续阅读
2023-03-24 上传
2022-03-31 上传
2021-09-26 上传
2021-05-11 上传
2019-08-11 上传
2021-05-15 上传
2021-03-30 上传

IRUIRUI__
- 粉丝: 574
- 资源: 55
 我的内容管理
展开
我的内容管理
展开







最新资源
- MiAD-MATALB集成放大器设计工具:MiAD使用晶体管的s参数评估放大器的稳定性和增益分布。-matlab开发
- software-engineering-project-the-commodore-exchange:GitHub Classroom创建的software-engineering-project-the-commodore-exchange
- 多用户在线网络通讯录B/S结构
- MongoDB-连接-Python
- 行业文档-设计装置-一种胶辊的脱模工艺.zip
- ansible-cacti-server:在类似Debian的系统中(服务器端)设置仙人掌的角色
- Trevor-Warthman.github.io:我的个人网页
- test_app
- github-slideshow:由机器人提供动力的培训资料库
- Band-camp-clone
- 行业文档-设计装置-化学教学实验用铁架台.zip
- hidemaruEditor_faq:Hidemaru编辑器常见问题集
- 观察组的总体均值和标准差:计算观察组的总体均值和标准差-matlab开发
- CovidAC
- HelpLindsay:可以帮助我完成各种任务的脚本集合
- lab01-alu-grupo14:GitHub Classroom创建的lab01-alu-grupo14
