时间序列自监督学习综述:生成、对比与对抗方法详解
需积分: 0 199 浏览量
更新于2024-08-03
收藏 935KB PDF 举报
时间序列自监督学习综述是一篇详细介绍2023年8月15日发布的文章,主要关注于AI领域的Kaggle竞赛资料,特别是针对人工智能算法的深入介绍和技术细节。自监督学习(SSL)作为一种新兴的机器学习策略,其核心在于通过无标签数据自我监督来提升模型性能,特别是在处理时间序列数据时展现出强大潜力。文章将时间序列SSL方法分为三类:基于生成的、基于对比的和基于对抗的,每类又细分为多个子类。
基于生成的方法涉及编码器-解码器结构,通过学习从原始输入(时间序列)生成重构版本来训练模型,例如预测未来的数据点或填充缺失值。这种方法的目标是减小原始数据和重构数据之间的误差。
基于对比的方法利用数据增强或上下文抽样创造正样本和负样本,通过最大化正样本之间的互信息(MI)来强化模型对数据关系的理解。这种策略常采用InfoNCE损失函数,如SimCLR和BYOL等方法在时间序列分析中应用广泛。
基于对抗的方法则结合生成器和判别器,生成器生成假样本,判别器负责区分真伪,如生成式对抗网络(GANs)在时间序列中可能用于异常检测或序列生成任务。
文章还概述了时间序列预测、分类、异常检测和聚类等任务中常用的数据集,为研究人员提供了实验验证的参考框架。通过这篇文章,读者可以深入了解如何在实际竞赛中运用自监督学习来优化时间序列分析,同时节省大量的标注数据需求。
总结来说,这篇综述旨在为人工智能从业者提供一个清晰的时间序列自监督学习指南,帮助他们在Kaggle竞赛或其他实际项目中更有效地利用这种强大的学习策略。
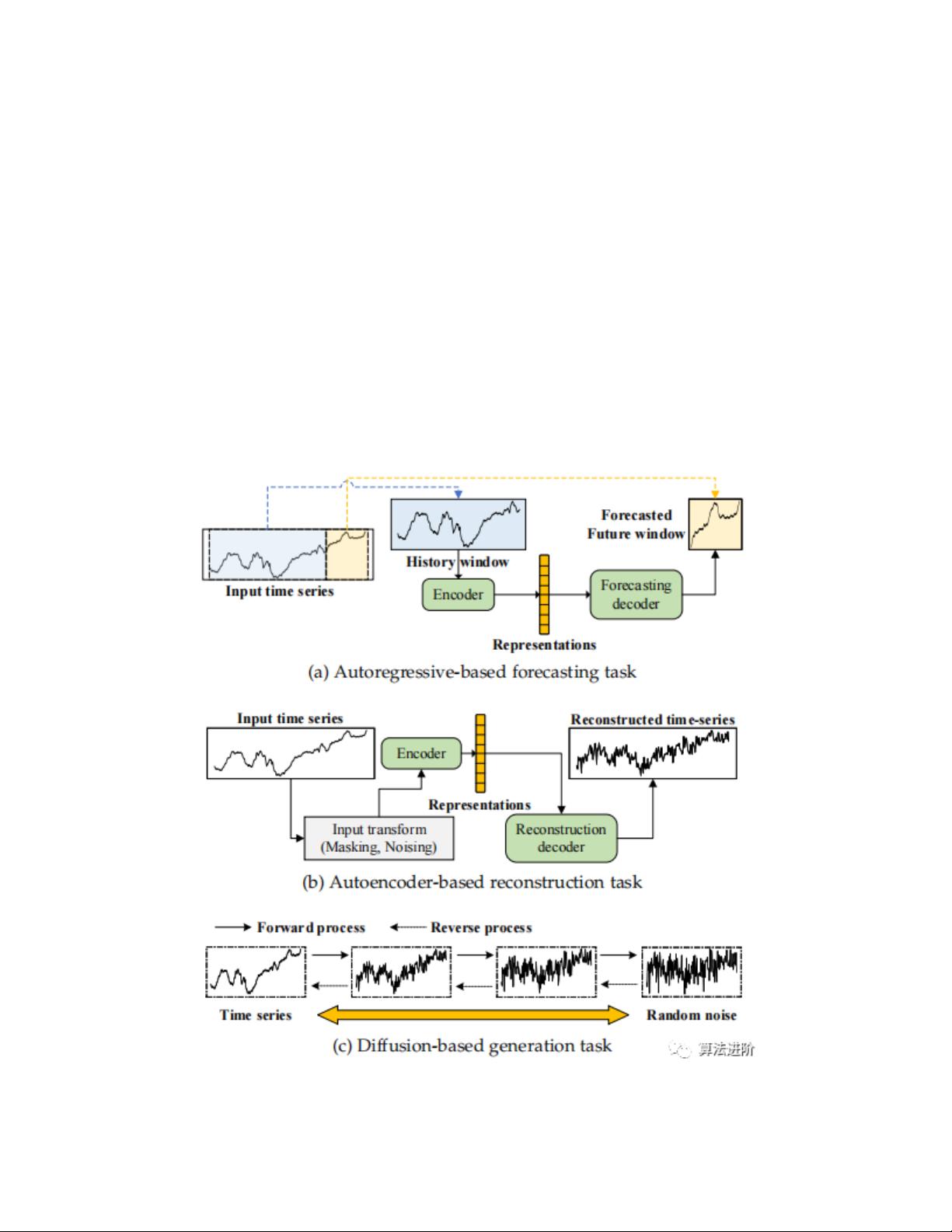
1 基于生成的方法
在这个类别中,预文本任务是基于给定数据的视图生成预期数据。在时间序列
建模的背景下,常用的预文本任务包括使用过去的序列来预测未来的时间窗口
或特定的时间戳,使用编码器和解码器来重构输入,以及预测掩码时间序列的
不可见部分。
本节从基于自回归的预测、基于自编码器的重构和基于扩散模型的生成3个角
度整理了现有的时间序列建模中的自监督表示学习方法(图3)。需要注意的
是,基于自编码器的重构任务也被视为一种无监督框架。在SSL的背景下,我
们主要将重构任务用作预文本任务,最终目标是通过自编码器模型获得表示。
图3:基于生成的时间序列SSL的三个类别。
剩余12页未读,继续阅读
2020-01-02 上传
2021-09-27 上传
2021-09-01 上传
2021-08-31 上传
2021-09-01 上传
2019-09-21 上传
2021-09-01 上传


白话机器学习
- 粉丝: 1w+
- 资源: 7672
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
