数据挖掘:分类与预测技术详解
版权申诉
128 浏览量
更新于2024-07-03
收藏 541KB PDF 举报
"第四章 分类与预测.pdf"
在数据分析领域,分类与预测是两种核心的技术,它们在数据挖掘、人工智能和机器学习中扮演着至关重要的角色。分类主要是针对离散型数据,目的是预测数据对象所属的类别,例如在银行风险管理中,通过构建分类模型来判断贷款申请的安全性。另一方面,预测则关注连续变量,如通过分析客户的收入和职业来预测其可能的消费支出,这通常涉及线性和非线性回归模型。
分类方法,如决策树归纳,是一种直观且易于理解的建模技术。决策树通过一系列规则将数据分割成不同的类别,每个内部节点代表一个特征,而叶子节点则代表一个类别。贝叶斯分类方法基于贝叶斯定理,考虑了各个特征之间的条件概率,常用于文本分类等领域。贝叶斯信念网络(BBN)则是一种图形模型,用于表示变量间的条件概率关系。
无监督学习与监督学习是分类学习的两种主要类型。监督学习,如决策树构建,依赖于带有标签的训练数据,即已知结果的数据,通过学习建立模型。而无监督学习则没有预先给定的类别信息,需要自行发现数据的内在结构或聚类。
除了决策树,还有其他分类学习方法,如K-最近邻(K-NN)算法,它根据最近邻的类别来决定新样本的类别。基于示例的学习通过存储和匹配训练样本来做出预测。遗传算法则借鉴生物进化原理,通过选择、交叉和突变操作优化模型。
预测方法主要包括线性回归和非线性回归模型。线性回归用于建立因变量与一个或多个自变量之间的线性关系,非线性回归则适用于更复杂的关系。为了应对大规模数据,这些方法通常需要具备外存处理能力和可扩展性。
在数据分类过程中,首先需要通过训练数据集建立模型,这个过程包括特征分析和模式识别。模型建立后,可以用于未知数据的预测,从而支持商业决策、科研等领域的应用。分类与预测是数据科学中的关键工具,它们能从海量数据中提取有价值的信息,为企业和研究提供有力的决策支持。
数据挖掘第四章 分类与预测
9
!
!
9
9
-!+9.-+.
=−−==
接着需要计算每个属性的(信息)熵。假设先从属性“
”开始,根据属
性“
”每个取值在
类别和
类别中的分布,就可以计算出每个分布所对
应的信息。
对于
::<=
;
=
= 97-+.
=
对于
::
−=
;
=
= -+.
=
对于
::>=
;
=
= 97-+.
=
然后利用公式(
)就可以计算出若根据属性“
”对样本集合进行划分,
所获得对一个数据对象进行分类而需要的信息熵为:
69-+.
!
-+.
-+.
!
-.
=++=
5
5
5
5
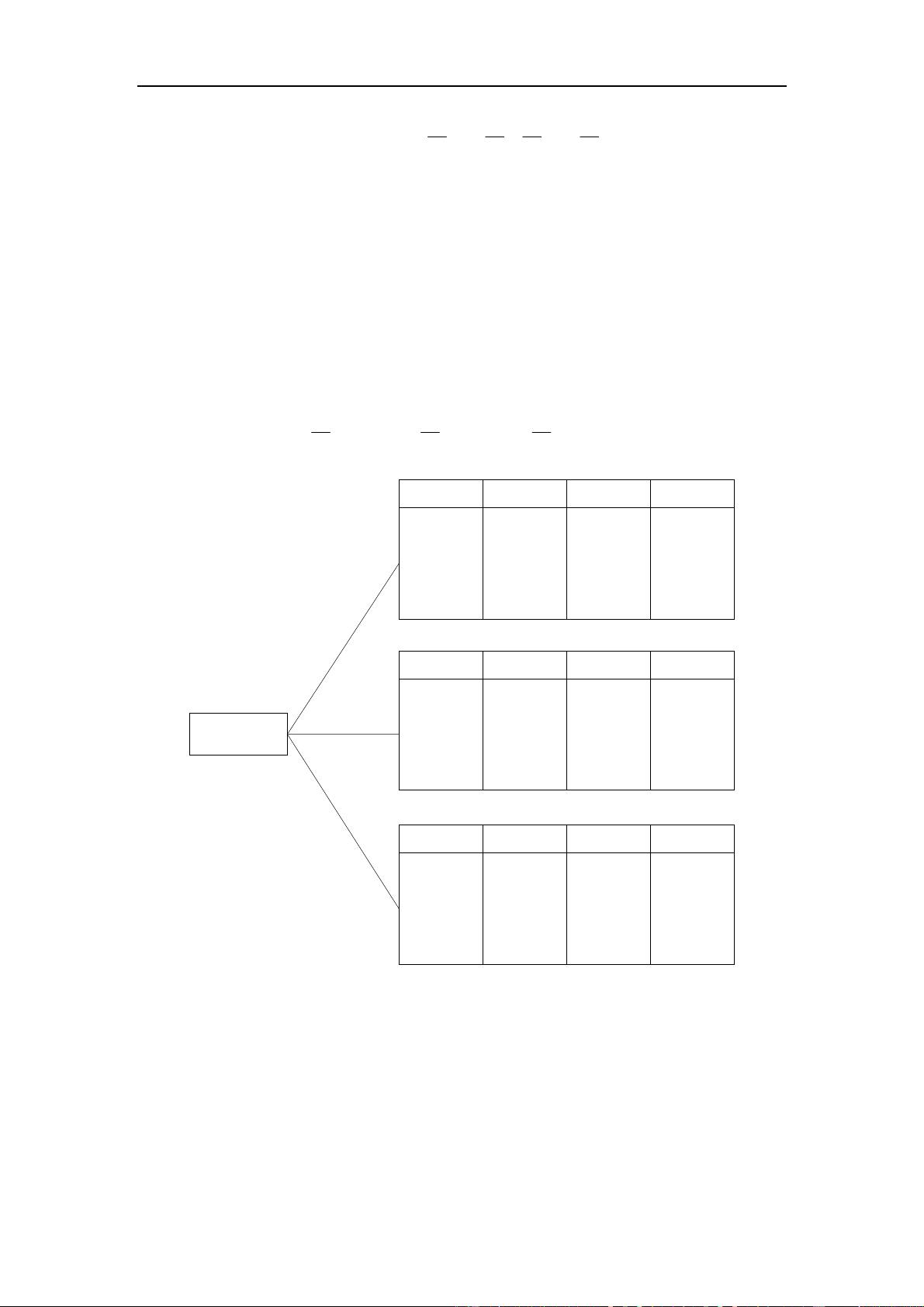
图-
选择属性“
”产生相应分支的示意描述
由此获得利用属性“
”对样本集合进行划分所获得的信息增益为:

剩余47页未读,继续阅读
2022-07-12 上传
2021-10-11 上传
2021-04-28 上传
2023-11-13 上传
2024-03-17 上传
2022-11-02 上传
2021-10-06 上传
2024-04-08 上传
2023-08-07 上传

智慧安全方案
- 粉丝: 3806
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
