电信套餐个性化推荐:CCF大数据竞赛经验分享
需积分: 42 3 浏览量
更新于2024-09-07
2
收藏 1.06MB PDF 举报
"这篇资源是关于作者参加2018年CCF大数据竞赛的心得体会,特别是关于面向电信行业存量用户的智能套餐个性化匹配模型的竞赛。该竞赛由联通研究院主办,旨在利用数据挖掘技术解决电信套餐个性化推荐的问题,以应对信息过载和用户无目的搜索的挑战。"
在此次CCF大数据竞赛中,问题的核心在于如何根据用户的消费行为和业务特征,建立一个个性化的电信套餐推荐模型。随着互联网技术的发展,电信运营商推出大量套餐以满足用户的多样化需求。然而,面对众多选择,用户往往难以找到最适合自己的套餐。因此,构建这样一个模型不仅可以提高用户的满意度,还能促进电信运营商的业务增长。
竞赛的主要任务是利用用户属性(如个人信息、画像信息)、终端属性和业务属性等,通过多分类方法匹配并推荐最合适的套餐。为了确保模型的泛化能力和稳定性,比赛设置了AB榜,两套不同的测试数据用于防止过拟合,评估模型的泛化性能。
在解决问题的过程中,主要分为四个阶段:
1. 数据处理:首先,进行数据分析,通过matplotlib、numpy和pandas等工具对原始数据进行预处理和可视化,目的是了解数据的分布情况,发现潜在的异常值、缺失值或相关性,为后续的特征工程和模型选择奠定基础。
2. 模型搭建:选择合适的算法模型,如Xgb_model_1和lgb_model文件夹所示,可能包括XGBoost和LightGBM等梯度提升树模型,这些模型在处理分类问题上表现出色,尤其适合处理大量特征和类别问题。
3. 模型训练:利用训练数据对模型进行训练,调整超参数,如学习率、树的数量、叶子节点大小等,以优化模型性能。
4. 优化结果:通过交叉验证和AB榜的测试数据不断迭代优化模型,比较不同模型在验证集和测试集上的表现,最终选取最优模型进行部署。
作者通过这次竞赛的经验分享了数据科学竞赛的通用流程,并强调了数据理解、模型选择和泛化能力的重要性。这对于其他参与类似竞赛或者从事相关工作的人来说,具有很好的参考价值。
题目:面向电信行业存量用户的智能套餐个性化匹配模型(2018 CCF-大数据竞赛(联
通研究院举办) )
网址:https://www.datafountain.cn/competitions/311/details
赛题背景:
电信产业作为国家基础产业之一,覆盖广、用户多,在支撑国家建设和发展方面尤为重要。
随着互联网技术的快速发展和普及,用户消耗的流量也成井喷态势,近年来,电信运营商推
出大量的电信套餐用以满足用户的差异化需求,面对种类繁多的套餐,如何选择最合适的一
款对于运营商和用户来说都至关重要,尤其是在电信市场增速放缓,存量用户争夺愈发激烈
的大背景下。针对电信套餐的个性化推荐问题,通过数据挖掘技术构建了基于用户消费行为
的电信套餐个性化推荐模型,根据用户业务行为画像结果,分析出用户消费习惯及偏好,匹
配用户最合适的套餐,提升用户感知,带动用户需求,从而达到用户价值提升的目标。
套餐的个性化推荐,能够在信息过载的环境中帮助用户发现合适套餐,也能将合适套餐信息
推送给用户。解决的问题有两个:信息过载问题和用户无目的搜索问题。各种套餐满足了用
户有明确目的时的主动查找需求,而个性化推荐能够在用户没有明确目的的时候帮助他们发
现感兴趣的新内容。
赛题的任务(目的):
此题利用已有的用户属性(如个人基本信息、用户画像信息等)、终端属性(如终端品牌等)、业
务属性、消费习惯及偏好匹配用户最合适的套餐,对用户进行推送,完成后续个性化服务,
是一个多分类任务。
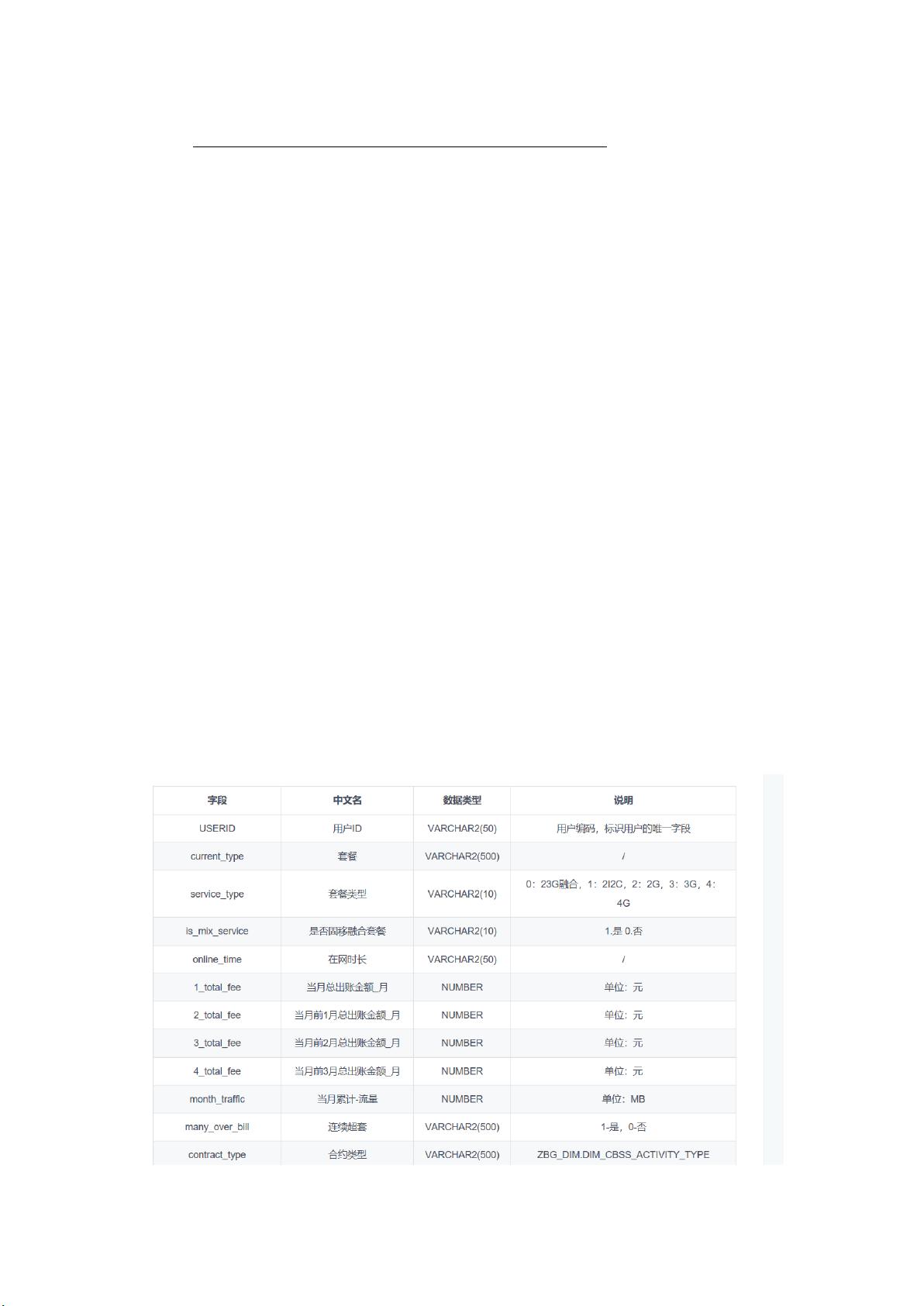
数据集各个属性说明如下图所示:
下载后可阅读完整内容,剩余6页未读,立即下载
271 浏览量
2024-11-08 上传
2024-01-16 上传
2024-10-28 上传
286 浏览量
2024-10-29 上传
2024-10-29 上传
211 浏览量
2024-10-29 上传

Peter清风
- 粉丝: 85
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- InstaSwapper:instagram用户名交换器
- chienlove.github.io
- PHPWind论坛 冰蓝
- JAVA源码java拼图游戏源码JAVA源码java拼图游戏源码
- AndroidNotes
- 处理器调度 操作系统 设计一个按优先数调度算法实现处理器调度的程序。
- AndroidRoomStarter:一个简单的会议室数据库启动器
- Avaneesh_153087_PP_Phase3
- matSklearn:用于 scikit-learn 的 MATLAB 包装器-matlab开发
- kitchenator:创建并检查您的每周菜单!
- 韩国公司模板
- 宽屏首页列表翻页教程网(带手机) v3.86
- 数据工厂
- QT虚拟键盘例子.rar
- ProgBases_DialogPr:编程基础中的考试分配
- Tetris-game-engine:基于俄罗斯方块游戏引擎的程序。 多个掉落物体+玩家控制的物体
