深度学习驱动的预训练模型在NLP任务中的进展
版权申诉
“面向自然语言处理任务的预训练模型综述.pdf”
自然语言处理(NLP)是计算机科学领域的一个重要分支,它涉及机器理解和生成人类语言。近年来,随着深度学习技术的飞速发展,NLP任务的性能得到了显著提升。预训练模型在这一过程中起到了关键作用,它们通过在大量未标注的文本数据上进行训练,学习到通用的语言表示,从而在各种下游任务中表现出色。
预训练模型的发展经历了从词级到文档级的演变。早期的预训练模型如Word2Vec和GloVe主要关注词级别的表示,它们学习词汇的分布式表示,但无法捕获上下文信息。随着技术的进步,BERT(Bidirectional Encoder Representations from Transformers)等模型引入了上下文敏感的表示,实现了从句子或段落级别理解语言,这极大地提高了模型的性能。
预训练模型的工作流程分为两个主要阶段:预训练和微调。在预训练阶段,模型在大规模无监督数据集(如维基百科、公共互联网文本等)上执行特定任务,如预测单词缺失部分(Masked Language Modeling, MLM)或句子顺序预测。在微调阶段,预训练好的模型被应用于具体的下游任务,如问答、情感分析、机器翻译等,通过少量有标签的数据进行进一步的训练。
目前,许多具有代表性的预训练模型已经涌现,如BERT、GPT(Generative Pre-trained Transformer)、RoBERTa(Robustly Optimized BERT Pretraining Approach)、ALBERT(A Lite BERT)、XLM(Cross-Lingual Language Model Pretraining)等。这些模型在结构、训练目标和效率上各有特点,如BERT采用Transformer架构,GPT则采用自回归方式,而ALBERT通过参数共享和因子分解实现了更轻量级的模型。
尽管预训练模型取得了显著成就,但依然面临一些挑战。例如,模型通常庞大且计算密集,导致训练和推理成本高昂;预训练与微调之间的知识转移并不总是最优的;以及对长文本的理解和处理能力有限。未来的研究方向可能包括模型的高效化、跨语言通用性增强、增强模型的解释性和适应性,以及探索更有效的预训练任务和损失函数。
预训练模型已经成为自然语言处理领域的核心技术,它们通过深度学习和无监督学习,极大地推动了NLP任务的性能提升。随着研究的深入,预训练模型有望在更多实际应用中发挥更大的作用,并持续推动人工智能领域的进步。
第 41 卷
计算机应用
型预测的标签数量。
虽然 Word2Vec 在预测中心词时能够考虑到上下文环境,
但是这种上下文信息仅仅是局部的,很难结合文本的全局特
征。针对这个问题,不同于基于神经网络架构的模型,GloVe
(Global Vectors for word representation)
[3]
采用基于矩阵的统计
建模方法,首先遍历整个语料库得到共现矩阵以表示词与词
之间的相关性;然后在对共现矩阵进行降维重构时,只考虑共
现次数非零的元素,同时在任务设计上对矩阵中的行和列加
入了偏移项,并通过设计加权函数遏制低频共现词产生的噪
声影响。相较于 Word2Vec,该方法的速度更快,并且由于结
合了全局文本特征,产生的词向量表示能够包含更多的语义
信息,如表 1 所示,GloVe 在单词类比、命名实体识别、单词相
似性判断等任务上与三种在共现矩阵降维上采取不同策略的
SVD 方法,以及 Word2Vec 中的两种方法相比有明显的提升。
词级表示的方法在大规模语料库上进行预训练得到词向
量,从而提升了模型在下游任务的表现;但这种预训练过程往
往可以看作是一种对语料进行的预处理,仅能获得词与词之
间的浅层关系。同时,这种方式得到的词向量始终是固定不
变的,无法根据不同的下游任务进行灵活改变,也不能处理遇
到新词和一词多义情况,缺乏针对性。可以看出,词级表示方
法包含的语义信息十分有限。
1. 2 文档级表示
文档级语义表示超越了词级范畴,通过输入整个句子或
文档序列,在语言模型上进行预训练,根据不同语境动态地提
取文本序列的句法规则和语义特征。
假设一个语料库中的文本表示为
(t
1
,t
2
,…,t
N
)
,用词级表
示方法可以得到文本序列中每个
t
i
对应的向量
e
t
i
,而文档级
表示方法就是将每个
e
t
i
与输入的整个序列通过函数
f
相关联
求得
h
t
i
,即:
h
t
i
= f (e
t
1
,e
t
2
,…,e
t
N
)
文档级表示方法不仅利用了词级表示生成的词向量,还
将预训练技术运用于更复杂的语言模型,获取更高级的语义
表示,如 ELMo、GPT、BERT 等都采用了这种思想。采用文档
级表示方法的预训练模型,在文本分类、问答系统、摘要生成
等众多 NLP 任务上取得了突破性效果,如今这种方法也成为
了研究预训练技术的一种主流趋势。
从文档级表示内容的范围上看,还可以将其大致划分为
局部文本信息和全局文本信息。
1. 2. 1 局部文本信息
一般是通过捕获局部上下文信息生成词向量表示,典型
的预训练技术主要采用语言模型的方法。在提取语言特征
时,大多基于以下技术:卷积神经网络(Convolutional Neural
Network,CNN)、循环神经网络、长短期记忆网络等。
CNN 能够结合文本序列位置信息,通过池化层获取最有
用的文本且训练速度较快,但其获取信息能力的大小取决于
卷积核窗口长度,因此捕获能力有限,只适用于局部文本
[15]
,
不能很好地解决长期依赖问题,而且池化操作不利于序列位
置信息的传递。RNN 根据时间序列逐词处理文本信息,通过
隐藏节点来传递前文短期记忆,其结构简单、符合语言习惯,
天然适合 NLP 任务,但该结构在训练长序列文本时很容易出
现梯度消失或梯度爆炸现象,优化较为困难。除此之外,RNN
在计算过程中,当前节点的计算必须依赖于前一个时间序列
的隐藏节点,不便于并行计算,导致效率低下。LSTM 和 GRU
(Gated Recurrent Unit)
[16]
则通过引入门控机制缓解了梯度消
失和长期依赖问题,但其本质上还是基于 RNN 的序列结构,
很多问题并不能得到彻底解决。
为捕获上下文信息,很多模型采用双向 RNN
[17]
或双向
LSTM 结构,最终合并正向和反向结果。如 ELMo 就是使用两
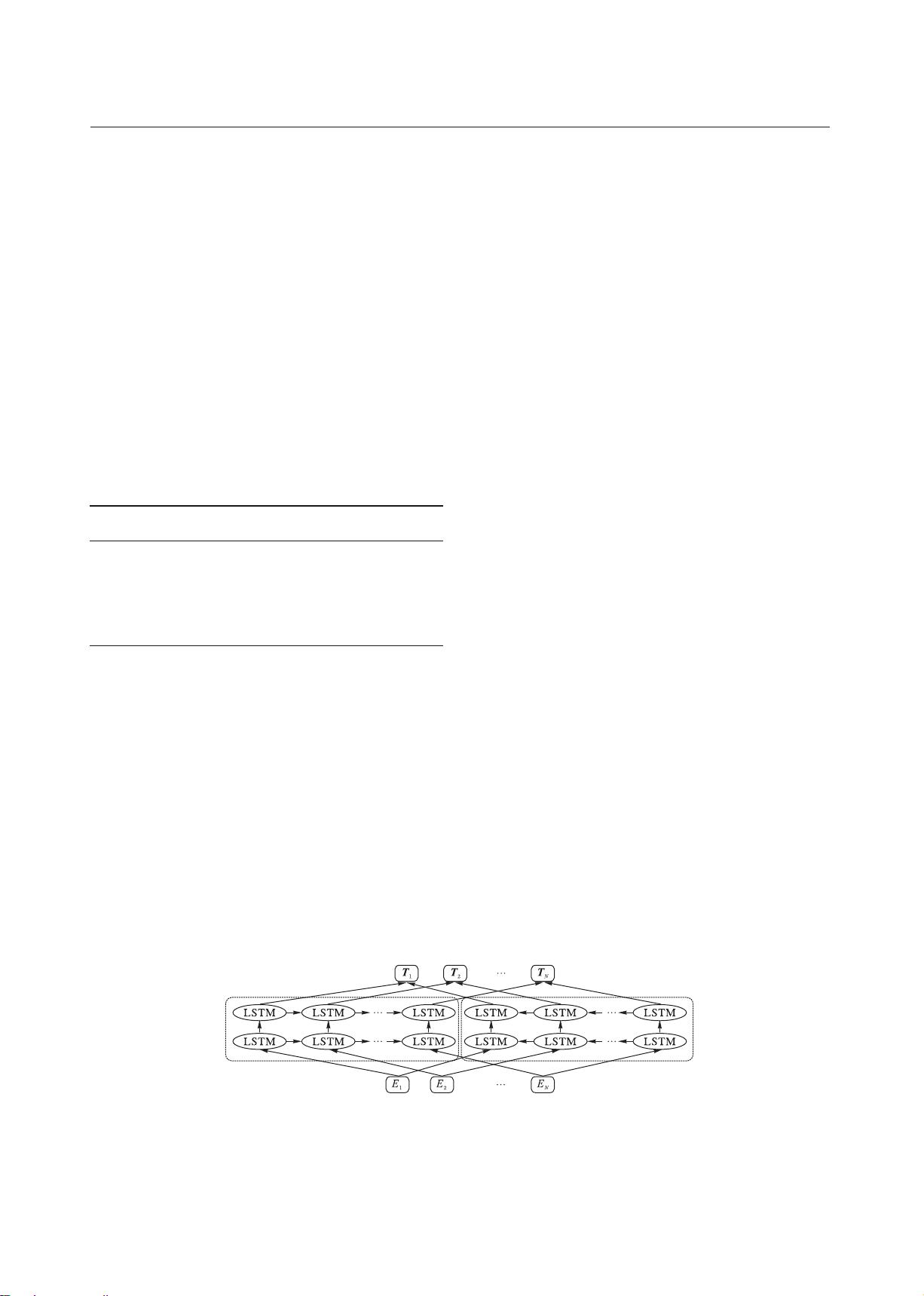
层双向 LSTM 用于编码上下文以捕获句法和语义特征,其结
构如图 2 所示,左侧双层 LSTM 表示前向编码器,按照从左至
右的顺序输入上文预测下文;右侧双层 LSTM 代表逆向编码
器,由右至左输入下文预测上文,以此获取上下文特征。预训
练阶段,ELMo 利用语言模型获得词向量表示;在下游任务中,
根据不同的上下文语境调整先前获得的词向量,以提高其准
确性和适应能力。通过将预训练技术运用于语言模型,有效
地应对了同一词语在不同上下文场景中的一词多义问题。
ELMo 能够获得不同语义场景下的词向量表示,在问答系
统、文本蕴涵和情感分析等 6 个 NLP 任务上有出色的表现;同
时这种先在大规模未标记语料库上进行无监督预训练,再对
下游任务进行特征提取的两段式方法也为后续的相关研究打
开了思路。
由于 ELMo 采用 LSTM 架构,仍然存在计算效率低下等问
表 1 GloVe 与其他模型在不同任务上的
实验结果对比 单位:%
Tab. 1 Experimental results comparison of
GloVe and other models on different tasks unit:%
模型
SVD
SVD-S
SVD-L
SG
CBOW
GloVe
注:300d/6B 表示训练在标记数量为 6B 的语料库上进行,
且向量维度为 300;50d 表示向量维度为 50。
单词类比
300d/6B
7. 3
42. 1
60. 1
69. 1
65. 7
71. 7
命名实体
识别 50d
85. 7
85. 5
84. 8
—
88. 2
88. 3
单词相似度
300d/6B
35. 3
56. 5
65. 7
62. 8
57. 2
65. 8
图 2 ELMo 模型结构
Fig. 2 Structure of ELMo model
1238
剩余10页未读,继续阅读
2020-12-26 上传
2020-03-19 上传
2021-08-18 上传
2023-05-18 上传
2020-03-24 上传
2021-09-26 上传
2021-07-10 上传
2023-06-24 上传

智鹿空间
- 粉丝: 8
- 资源: 518
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
