Python BS4模块中find与find_all的使用解析
版权申诉
"这篇教程介绍了Python中如何使用`find`和`find_all`方法进行网页爬虫和文本查找。文章分为两个部分,首先讲解了在字符串(str)中使用`find`的方法,然后深入到BeautifulSoup模块中应用这两个方法进行HTML解析。
在字符串中,`find`方法用于查找指定子字符串在原字符串中的位置。如案例1所示,`a.find('0')`返回'0'在字符串'a'中的索引,即0。同样,案例2中`a.find('5')`返回5的索引,即5。如果找不到目标子字符串,`find`会返回-1。
在BeautifulSoup模块中,`find`和`find_all`则用于在HTML文档结构中查找元素。`find`方法用于查找第一个匹配指定条件的元素,例如`bs.find(class_='one')`将返回HTML中第一个class为'one'的元素。这个元素将作为一个新的对象,你可以进一步对它使用`find`或`find_all`。如果要查找所有匹配的元素,`find_all`方法则会返回一个包含所有匹配元素的列表。
以查找class为'navbar-branding'的元素为例,假设`bs.find(class_='one')`的结果赋值给了变量`one`,那么`one.find(class="navbar-branding")`会找到`one`内部第一个class为'navbar-branding'的元素,并返回该元素的内容或属性。
`find`和`find_all`是Python中BeautifulSoup库进行网页解析和数据提取的关键工具,它们允许开发者根据HTML标签、属性等条件精确地定位和提取所需信息。对于网页爬虫来说,熟练掌握这两个方法对于高效抓取和处理网页数据至关重要。在实际操作中,还需要结合其他方法和技巧,如处理CSS选择器、解析属性、处理嵌套结构等,以实现更复杂的网页抓取任务。"
python 如何使用如何使用find和和find_all爬虫、找文本的实现爬虫、找文本的实现
这篇文章我们来讲讲如何在python使用bs4模块返回值中正确使用find和find_all来取值。
我们先来看看find函数在两种场景使用: 一、 find在字符串(str)时可以查找使用。
在字符串(str)是怎么来使用find函数,find函数就是找到找到的意思。
我们来看看下面案例
#---------案例1-----------
a='0123456789'#因为我们电脑中的字节都是从0开始算第一个位置
b=a.find('0')#这行代码的意思就是我要查找a中0的位置
print(b)
>>0
#这里就是打印出来的内容
应为0在a中的第0个位置
在来试试第二个案例
#---------案例2-----------
a='0123456789'
b=a.find('5')#我要查找a中5的位置
print(b)
>>5
其中你要查找的内容不在a中,则会返回 -1 。在str中的使用方法说到这里。
二、二、 find在在bs4模块返回值中怎么使用模块返回值中怎么使用
我们在课堂上学过,bs4返回的值是 <class 'bs4.BeautifulSoup'>
假设我把把bs4返回的值赋值给 bs
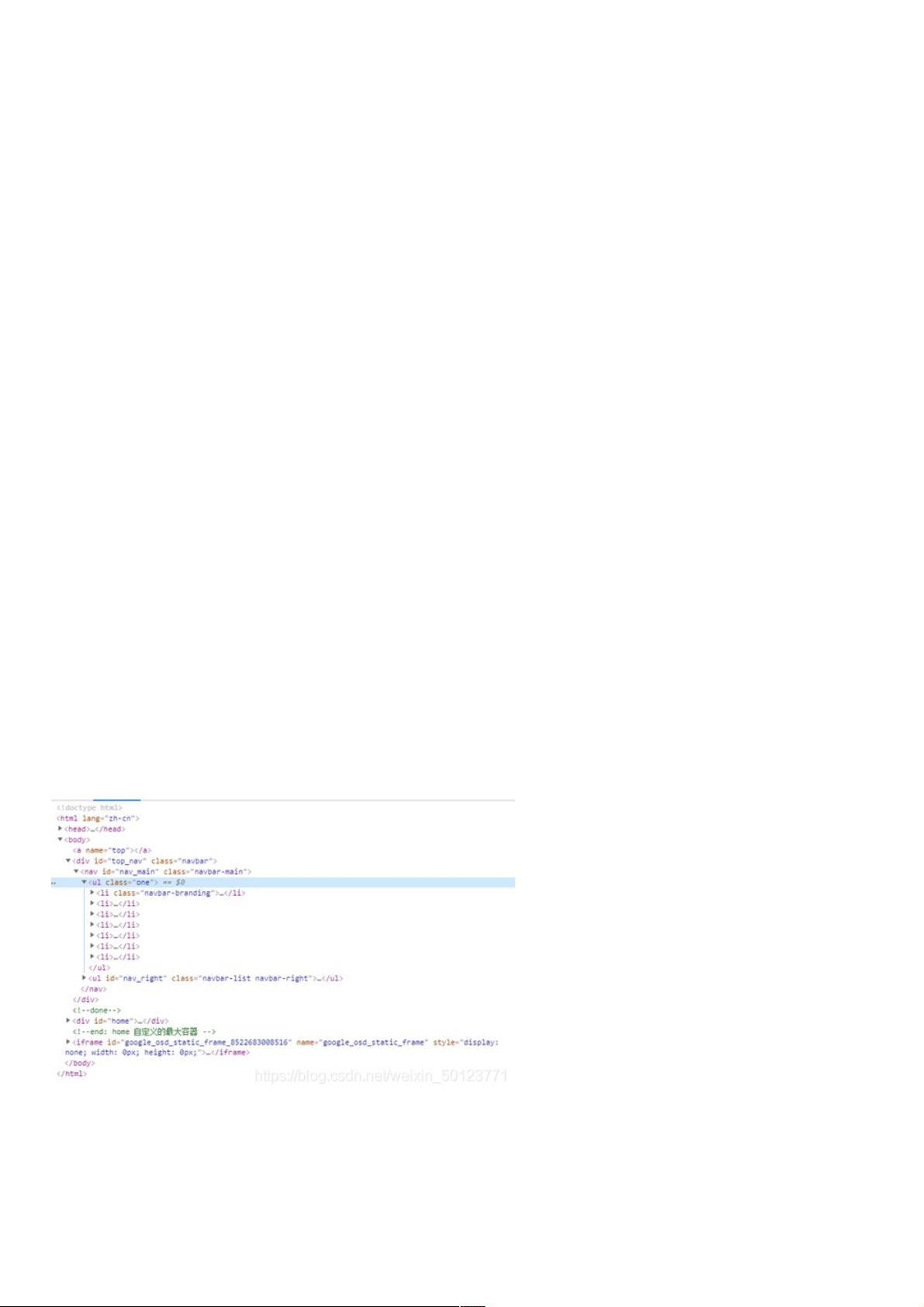
这时我们就要用 bs.find(class_=‘one’)
这个代码就是在bs值中从上往下找,找到第一个类等于one的值。
如果下图
从上到下找是不是我标出来蓝色区域是我要找的类,对的我们把他赋值给one,我们把他打印出来
print('one')
这时候系统就会返回这样一个值给我们,如下图
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-11 上传
2021-10-04 上传
2021-10-04 上传
2021-10-25 上传
2021-09-30 上传
2022-09-19 上传

weixin_38744375
- 粉丝: 372
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
