深度学习驱动的文本分类技术现状与趋势
需积分: 0 93 浏览量
更新于2024-08-05
收藏 1.06MB PDF 举报
"基于深度学习的文本分类研究进展_杜思佳1"
本文重点探讨了基于深度学习的文本分类技术的最新研究和发展。文本分类是自然语言处理领域的一个核心问题,广泛应用于舆情分析、新闻分类等多个场景。近年来,随着人工神经网络技术的进步,深度学习在文本分类中的应用取得了显著成果。
在深度学习的框架下,文本分类首先需要将非结构化的文本数据转换为可供模型处理的数值化表示。词向量技术是这一过程的关键,它能够捕捉词汇之间的语义关系,如Word2Vec、GloVe和FastText等模型通过不同的方法生成词向量,为文本分类提供有效的特征表示。Word2Vec利用上下文窗口预测单词,GloVe则通过全局统计信息来捕获词汇共现矩阵的对数概率,而FastText则通过对单词进行分词来捕获更丰富的子词信息。
深度学习模型在文本分类中的应用主要包括循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)以及卷积神经网络(CNN)。RNN系列模型因其能够处理序列数据的特性,在处理文本这类时间序列数据时表现出色,但存在梯度消失或爆炸的问题。LSTM和GRU通过引入门控机制来缓解这些问题,增强了模型在长期依赖信息处理上的能力。CNN则在图像识别领域取得成功后,被引入到文本分类中,通过滤波器提取局部特征,尤其在固定长度的文本片段上效果良好。
此外,预训练模型如BERT、RoBERTa、ALBERT等Transformer架构的模型,通过自监督学习在大规模无标注文本上学习通用语言表示,极大地提升了文本分类的性能。这些模型不仅在分类任务上表现出色,而且可以进行微调以适应特定任务,进一步提高准确率。
尽管深度学习在文本分类上取得了显著进步,但依然存在一些挑战和未来发展方向。例如,模型的解释性较差,难以理解内部决策过程;计算资源需求大,对于实时和大规模应用有一定限制;过拟合问题仍然存在,需要优化正则化策略;以及对于长文本的处理效率和效果仍有待提升。
深度学习的引入极大地推动了文本分类技术的发展,通过不断的研究和创新,未来有望解决现有问题,实现更加高效、准确且可解释的文本分类模型。研究者们将继续探索新的表示学习方法、优化模型架构以及改进训练策略,以应对日益复杂的文本处理需求。
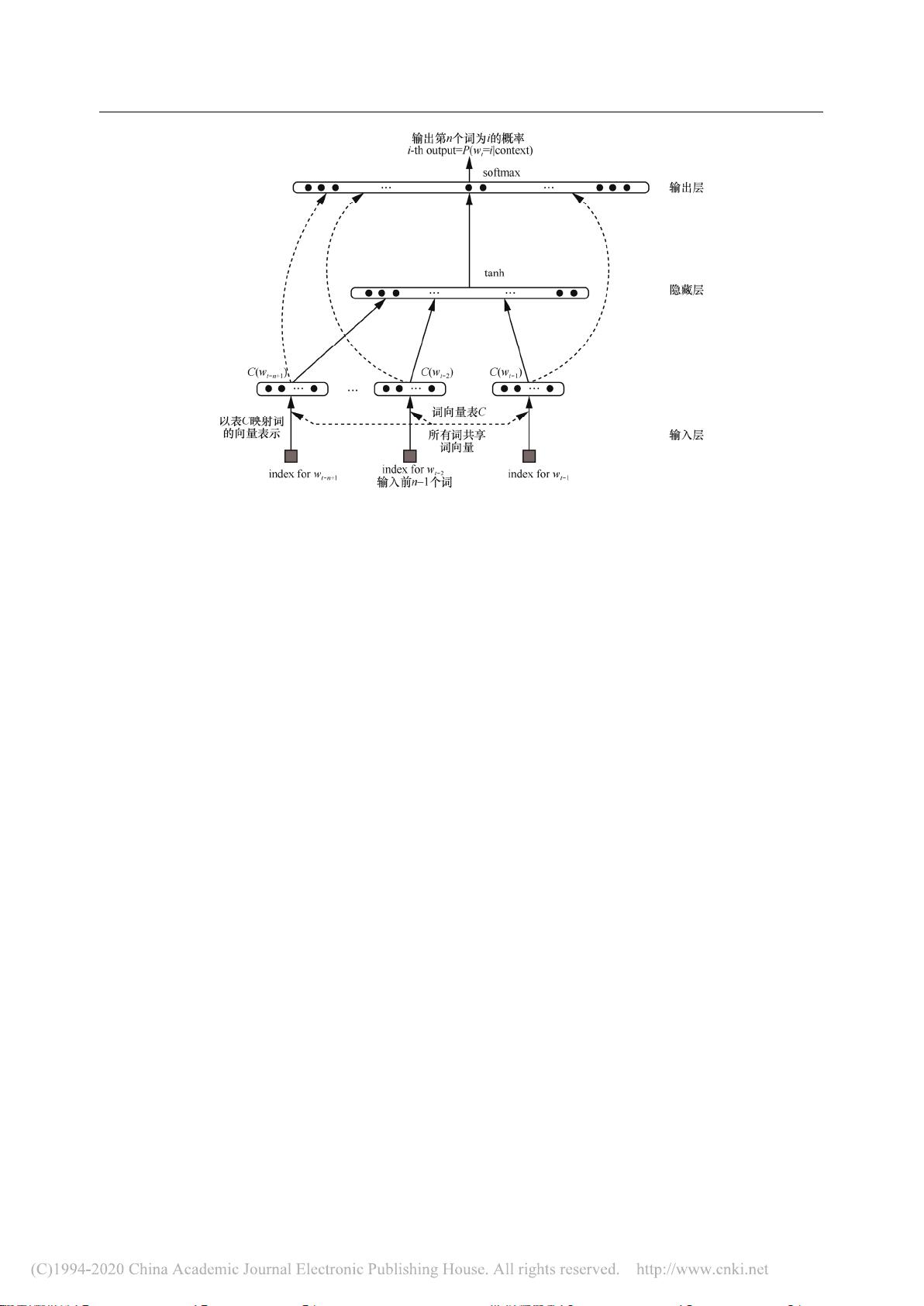
第 4 期 杜思佳等:基于深度学习的文本分类研究进展 ·3·
主要思想依旧依托于 n-gram 语言模型。针对词向
量的训练,研究人员还进行了更多的探索。但是,
其主要思想大同小异,大多从
Bengio 等提出的
NNLM 出发,以上下文预测为主要思想,在神经
网络模型的选择和具体实现、语言模型的训练速
度等方面进行创新和改进。
自然语言处理领域最为常用的词向量训练
方法是
2013 年 Google Mikolov 提出的 Word2vec
及其发布的相应工具包
[10]
。Word2vec 有两种可
供选择的语言模型(
CBOW 和 Skip-gram),并
且提供了两种有效提高训练速度的优化方法:层
次
softmax ( hierarchical softmax )和负采样
(
negative sampling)技术。Word2vec 在之前研究
者的基础上,简化模型,取其精华,得到现有模
型,其在百万数量级的词表和语料中均能进行高
效的训练,且获取的词向量能够较为精确地衡量
词与词之间的相似性。
CBOW 的主要思想是以
一个词的上下文作为输入,预测当前词出现的概
率;而
Skip-gram 相反,它以这个词作为输入,
预测其上下文。两种方法均可自定义上下文的窗
口大小。层次
softmax 是以哈夫曼树代替神经网
络从隐藏层到
softmax 层的映射,这样可以有效
提高模型训练速度。负采样技术在词向量训练中
引入了负例,而其优化目标为最大化正样本的似
然,同时最小化负样本的似然。另一个常用的词嵌
入工具是由斯坦福
NLP 团队发布的 Glove
[12]
,它是
一个基于全局词频统计的词表征工具。
Glove 模型
融合了传统机器学习的全局词文本矩阵分解方法
和以
Word2vec 为代表的局部文本框捕捉方法,在
有效利用词的全局统计信息的同时,有效捕捉其上
下文信息。
Facebook 发布的工具——Fast Text 中也
有词向量训练的部分,其基本模型与
Word2vec 一
致,不同之处在于,
FastText 的词向量训练在输
入层位置提供了字符级别的 n
-gram,如单词为
where,n=3 时,其 n-gram 为<wh,whe,her,ere,re>,
单词将由单词本身及其 n
-gram 代表。由于英文单
词具有前后缀等语言形态上的相似性,这种方法
可以建立词与词之间的联系
[13]
。
前面所介绍的词向量模型,包括被广泛使用
的
Word2vec、Glove 等,其生成的词向量均存在
一个问题:在利用这些词向量对词语进行编码的
时候,一个词只对应一个词向量,即无法解决词
的多义性问题。为解决这个问题,
ELMo 提供了
一种解决方案
[14]
,实验结果表明,ELMo 在分类
任务、阅读理解等
6 个 NLP 任务中性能有不同幅
度的提升,最高的提升达到
24.9%。ELMo 是一
种新型深度语境化词表征,其主要思想是:事先
训练好一个完整的语言模型,然后在实际使用时
图 1 NNLM网络结构
Figure 1 NNLM network structure
剩余12页未读,继续阅读
2021-10-04 上传
2012-06-15 上传
2012-09-13 上传
2009-12-28 上传
2024-07-04 上传
2021-04-29 上传
2023-10-12 上传

忧伤的石一
- 粉丝: 31
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
