利用Spark进行分布式计算以获取商业洞察
版权申诉
"藏经阁-Distributed Computing with Spark.pdf"
这篇文档是关于在企业环境中使用Apache Spark进行分布式计算的讨论,由Stephan Kessler在2016年Spark Summit Europe上发表。Stephan Kessler是SAP HANA Vora团队的一员,专注于将SAP引擎集成到Apache Spark中。演讲的核心关注点是企业如何克服数据利用率低、技能差距大以及如何从Hadoop中获取价值的挑战。
企业数据利用现状:
文档指出,大多数企业在其业务智能(BI)和分析中平均只使用了60%到73%的数据。这表明存在大量的未被挖掘的数据潜力。同时,技能缺口是57%受访者面临的重大采纳障碍,而49%的受访者在决定如何从Hadoop中获取价值方面感到困惑。这些数据引自Forrester Wave™: Big Data Hadoop Distributions, Q1 2016报告和Gartner的"Survey Analysis: Hadoop Adoption Drivers and Challenges"报告。
当前系统景观:
企业通常拥有包括SAP HANA平台和其他应用程序在内的系统架构。然而,存在以下几个问题:
1. 从商业应用的角度看,需要一种标准化的方式来访问大数据环境,并期望有与传统SQL类似的表达能力。
2. 从大数据/数据科学的角度,需要接入专门的引擎来靠近数据进行分析,并且希望实现这些引擎与现有系统的集成。
Apache Spark的角色:
Spark作为一个分布式计算框架,能够提供快速、通用和可扩展的数据处理能力。它可以作为解决上述挑战的一个工具,特别是在数据科学领域,Spark支持多种语言,如Python、Java和Scala,可以提供高性能的数据处理和分析。此外,Spark SQL提供了与SQL兼容的接口,使得业务用户能够以他们熟悉的方式查询大数据。
SAP HANA Vora的引入:
SAP HANA Vora是SAP为了解决上述问题而开发的一个产品,它旨在将Spark的功能与HANA的内存计算能力相结合,提供对Hadoop和其他大数据源的快速分析。Vora允许企业在不牺牲性能的情况下,对Hadoop中的数据进行更复杂的分析,同时提供了与现有SAP应用程序的集成。
总结:
"藏经阁-Distributed Computing with Spark"讨论了企业如何通过Apache Spark和SAP HANA Vora这样的工具克服大数据利用的挑战。Spark的分布式计算能力与HANA Vora的集成,为企业提供了一种更有效利用其数据并进行深度分析的方法,以获取更有价值的商业洞察。同时,这也强调了提升员工技能和优化数据分析流程的重要性。
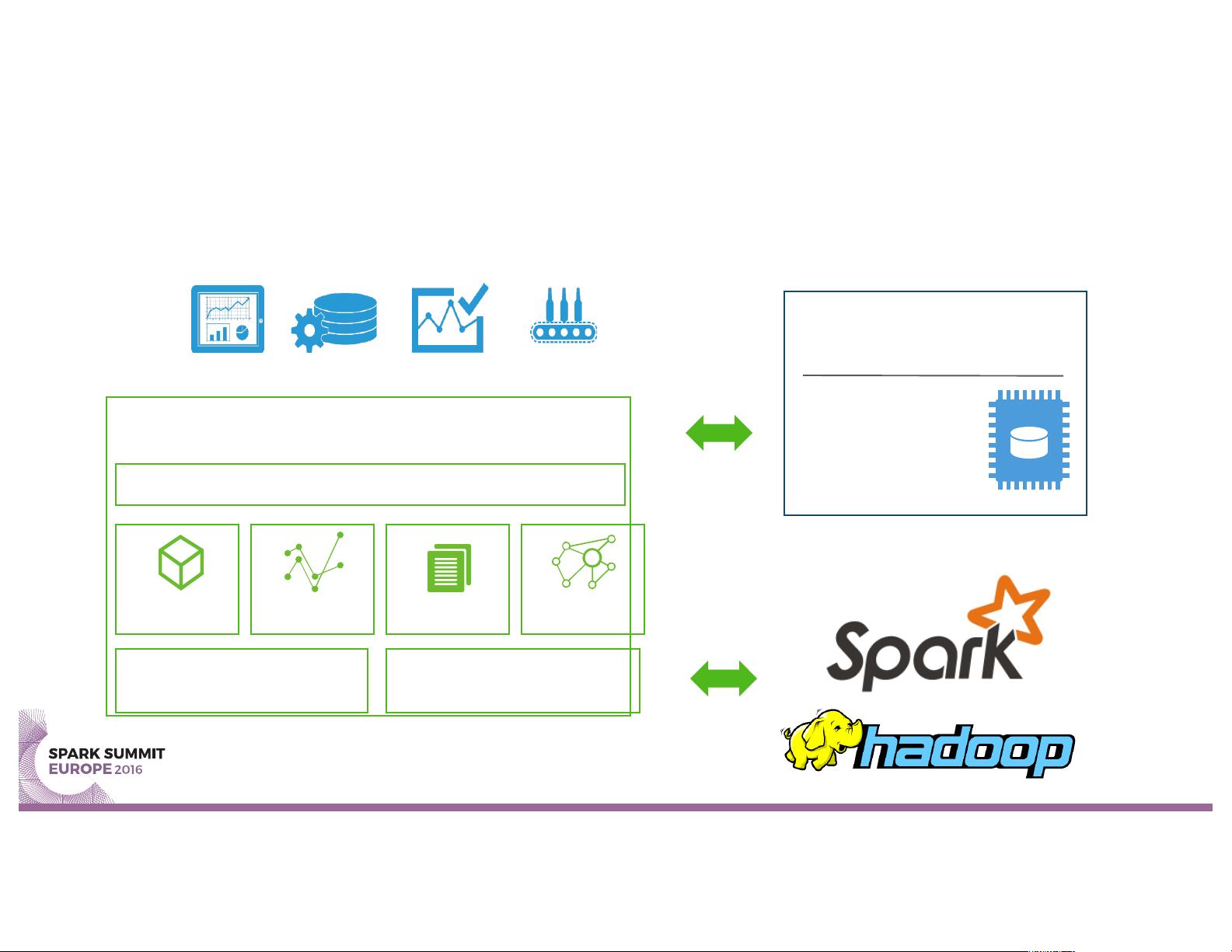
SAP Hana Vora – 10k ft POV
Data Science, Predictive, Business Intelligence, Visualization Apps
SAP HANA Vora
Data Modeler
OLAP
Time Series Graph
Doc Store
Disk-to-Memory
Accelerator
Distributed Transaction Log
ERP Systems
SAP HANA
Platform
剩余33页未读,继续阅读
2018-06-19 上传
2009-03-19 上传
2008-04-26 上传
2024-10-30 上传
2024-10-30 上传
2023-06-03 上传
2023-03-16 上传
2023-06-15 上传
2023-06-03 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
