
Tachyon::Spark生态系统中的分布式内存文件系统生态系统中的分布式内存文件系统
摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通过更细的分工达到更高的执
行效率。
Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上, Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压
力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专
注计算的本身, 以求通过更细的分工达到更高的执行效率。 本文将先向读者介绍Tachyon在Spark生态系统中的使用, 也将
分享百度在大数据平台上利用Tachyon取得的性能改善的用例,以及在实际使用Tachyon过程中遇到的一些问题和解决方案。
最后我们将介绍一下Tachyon的一些新功能。
Tachyon简介
Spark平台以分布式内存计算的模式达到更高的计算性能,在最近引起了业界的广泛关注,其开源社区也十分活跃。以百度为
例,在百度内部计算平台已经搭建并运行了千台规模的Spark计算集群,百度也通过其BMR的开放云平台对外提供Spark计算
平台服务。然而,分布式内存计算的模式也是一柄双刃剑,在提高性能的同时不得不面对分布式数据存储所产生的问题,具体
问题主要有以下几个:
1. 当两个Spark作业需要共享数据时,必须通过写磁盘操作。比如:作业1要先把生成的数据写入HDFS,然后作业2再从
HDFS把数据读出来。在此,磁盘的读写可能造成性能瓶颈。
2. 由于Spark会利用自身的JVM对数据进行缓存,当Spark程序崩溃时,JVM进程退出,所缓存数据也随之丢失,因此在工
作重启时又需要从HDFS把数据再次读出。
3. 当两个Spark作业需操作相同的数据时,每个作业的JVM都需要缓存一份数据,不但造成资源浪费,也极易引发频繁的
垃圾收集,造成性能的降低。
仔细分析这些问题后,可以确认问题的根源来自于数据存储,由于计算平台尝试自行进行存储管理,以至于Spark不能专注于
计算本身,造成整体执行效率的降低。
Tachyon的提出就是为了解决这些问题:本质上,Tachyon是个分布式的内存文件系统,它在减轻Spark内存压力的同时赋予
了Spark内存快速大量数据读写的能力。Tachyon把存储与数据读写的功能从Spark中分离,使得Spark更专注在计算的本身,
以求通过更细的分工达到更高的执行效率。
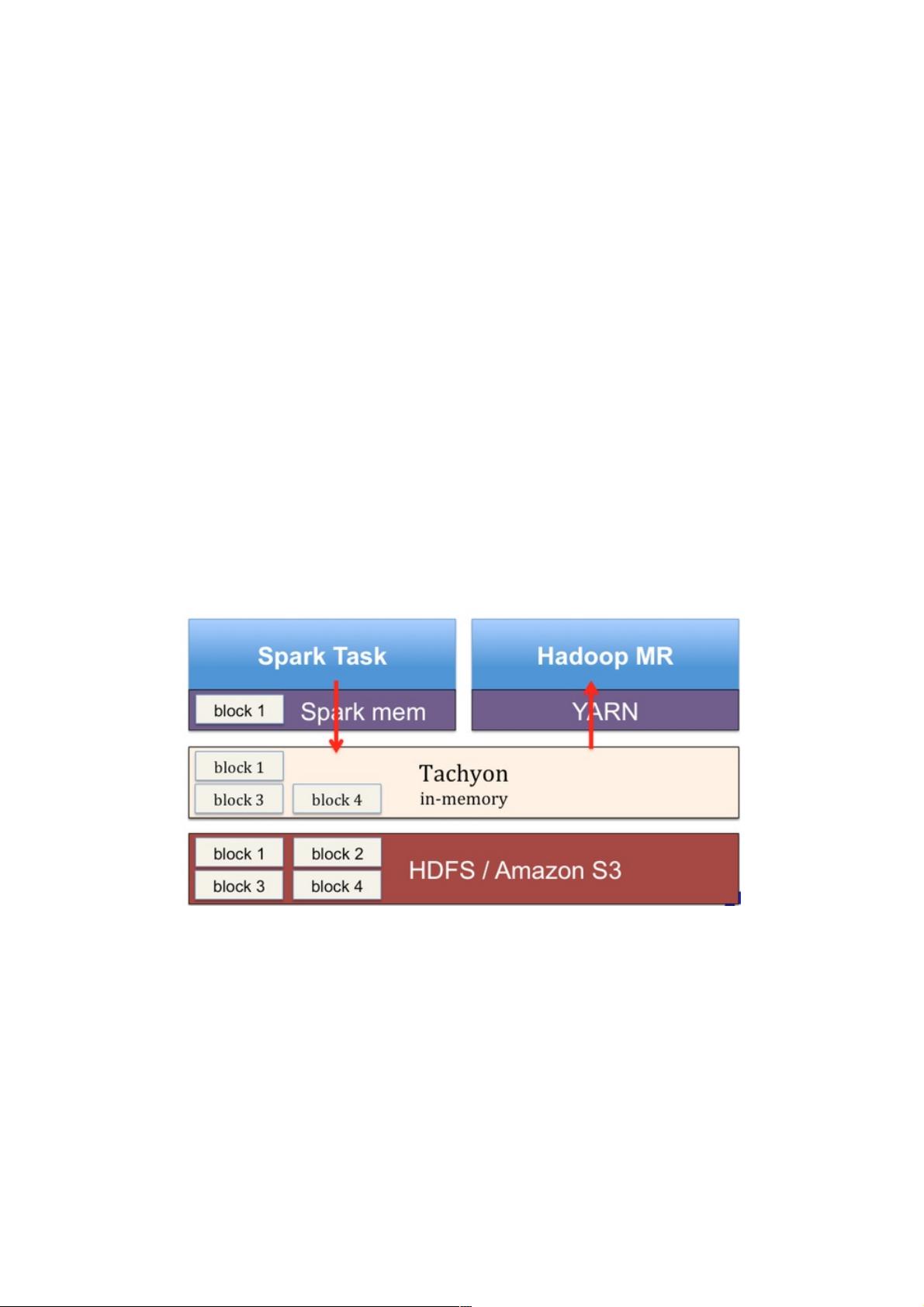
图1: Tachyon的部署
图1显示了Tachyon的部署结构。Tachyon被部署在计算平台(Spark,MR)之下以及存储平台(HDFS, S3)之上,通过全
局地隔离计算平台与存储平台, Tachyon可以有效地解决上文列举的几个问题,:
1. 当两个Spark作业需要共享数据时,无需再通过写磁盘,而是借助Tachyon进行内存读写,从而提高计算效率。
2. 在使用Tachyon对数据进行缓存后,即便在Spark程序崩溃JVM进程退出后,所缓存数据也不会丢失。这样,Spark工作
重启时可以直接从Tachyon内存读取数据了。
3. 当两个Spark作业需要操作相同的数据时,它们可以直接从Tachyon获取,并不需要各自缓存一份数据,从而降低JVM内
存压力,减少垃圾收集发生的频率。
Tachyon系统架构
在上一章我们介绍了Tachyon的设计,本章我们来简单看看Tachyon的系统架构以及实现。 图2显示了Tachyon在Spark平台的
部署:总的来说,Tachyon有三个主要的部件:Master, Client,与Worker。在每个Spark Worker节点上,都部署了一个
Tachyon Worker,Spark Worker通过Tachyon Client访问Tachyon进行数据读写。所有的Tachyon Worker都被Tachyon
Master所管理,Tachyon Master通过Tachyon Worker定时发出的心跳来判断Worker是否已经崩溃以及每个Worker剩余的内存
空间量。
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38558660
- 粉丝: 2
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


