单机模拟Hadoop伪分布式运行全攻略
"基于单机的Hadoop伪分布式运行模拟实现及分析,通过单机模拟Hadoop的分布式环境,理解Hadoop的运行机制,包括NameNode、DataNode、JobTracker、TaskTracker和SecondaryNameNode的角色,以及WordCount示例的执行流程。资料包括安装cygwin的步骤和相关包的选择,特别强调了openssh包的安装,以支持SSH通信。"
在Hadoop生态系统中,分布式计算是核心特性,但在开发和测试环境中,我们往往需要在单机上模拟分布式环境,这就是所谓的“伪分布式”模式。这种模式允许开发者在本地计算机上运行Hadoop,同时模拟多节点环境,以便理解和调试Hadoop的工作原理。
**Hadoop的组件角色**
- **NameNode**:HDFS的主节点,管理文件系统的命名空间和文件块映射信息,确保数据的一致性。
- **DataNode**:HDFS的从节点,存储实际的数据块,执行数据读写操作。
- **SecondaryNameNode**:不是NameNode的热备份,而是用来定期合并NameNode的edit logs,防止NameNode的日志文件过大导致重启时间过长。
- **JobTracker**:MapReduce的主节点,负责任务调度和集群资源管理。
- **TaskTracker**:MapReduce的从节点,接收JobTracker的指令,执行Map任务和Reduce任务,通常每个TaskTracker与DataNode共存,以便数据本地化减少网络传输。
**模拟过程**
1. **环境准备**:为了在Windows系统上运行Hadoop,可能需要安装类似cygwin的环境,因为它提供了类Unix的命令行工具和开源软件的编译环境。
2. **安装配置**:安装过程中,需要确保选择并安装了`openssh`包,因为Hadoop的启动和管理依赖SSH通信,用于各个组件之间的安全连接。
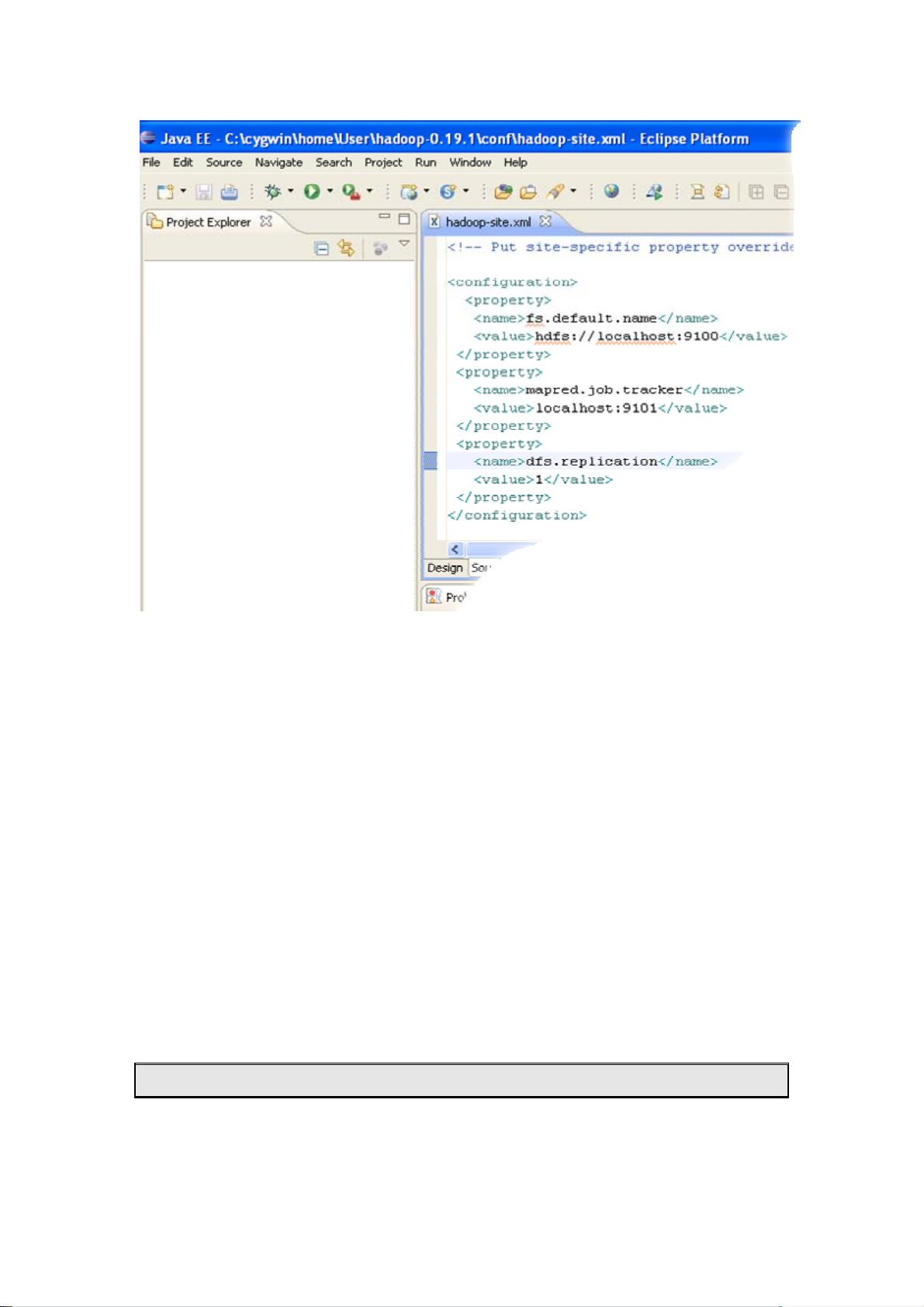
3. **配置Hadoop**:修改Hadoop的配置文件如`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`,设置相关参数,指定本地路径作为HDFS和MapReduce的存储位置,并启用伪分布式模式。
4. **启动Hadoop**:通过执行启动脚本来启动NameNode、DataNode、JobTracker和TaskTracker等服务,模拟分布式环境。
5. **运行示例**:以WordCount为例,这个简单的程序用于统计文本文件中各个词的出现次数,可以验证Hadoop环境是否配置正确。提交WordCount作业到Hadoop,观察Map和Reduce任务的执行过程。
通过这个过程,我们可以深入理解Hadoop的分布式架构,包括数据的存储和计算流程,以及MapReduce的工作模型。同时,这对于学习Hadoop的运维和优化也是非常有价值的,因为可以直接观察到每个组件的行为,便于调试和性能分析。
在配置结束后,用 ssh localhost 测试
Hadoop 下载并安装
Hadoop 配置
首先进行 Hadoop 配置:
1、conf/hadoop-env.sh 文件中最基本需要指定 JAVA_HOME,例如我的如下:
打开它你可以看到:
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
将第二行的注释符号去掉,同时指定在你的机器上 JAVA_HOME 的值,如下为我修
改的内容:
# The java implementation to use. Required.

剩余62页未读,继续阅读
577 浏览量
2048 浏览量
242 浏览量
点击了解资源详情
2014-04-18 上传
232 浏览量
255 浏览量

航向正北
- 粉丝: 3
- 资源: 38
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于卷积神经网络的4种猫咪预测模型
- 中交进出库明细表excel模版下载
- 使用Arduino监控ECG和呼吸-项目开发
- ya-school-shri-2018-1:“发现错误”-接口开发学院的入门作业
- DailyGrain
- 镍矿开采:一种用于收集镍矿开采场所相关数据的模型。 工作正在进行中
- 女士闺房3D模型设计
- 工程管理人员个人总结
- HTML-CSS-[removed]实行多元化的保护措施
- 128x64 LCD上的模拟,数字时钟和温度计-项目开发
- Smolyak各向异性网格:解决高维问题-matlab开发
- terraform-workshop
- 日记账管理系统excel模版下载
- 酒店走廊3D模型
- Arduino 101-英特尔居里图案匹配连衣裙-项目开发
- Ecom
