机器翻译与语音识别:统计与深度学习方法详解
版权申诉
PDF格式 | 2.99MB |
更新于2024-06-19
| 168 浏览量 | 举报
本课程名为"Python自然语言处理NLP算法课程 第13课 机器翻译与语音识别技术介绍、IBM Watson系统的认知智慧共54页.pdf",主要涵盖了自然语言处理领域中的高级主题,特别是机器翻译与相关的技术应用。在第13课中,内容详细讲解了以下几个关键知识点:
1. **统计机器翻译**:
- 介绍了机器翻译的发展历程,从基于规则的翻译(如词汇转换、句法分析和语义分析)到基于语料库的统计机器翻译,其中着重讨论了统计机器翻译的方法论,如词汇翻译模型,如词典和语料库驱动的概率计算。
2. **信息检索和问答系统**:
- 包括问答系统的构建,如聊天机器人,以及信息检索的基本原理,如搜索引擎的工作原理和在客服机器人中的应用。
3. **IBM Watson的认知智慧**:
- 提及了IBM Watson,这是一种强大的人工智能系统,展示了其在机器翻译中的认知能力,包括其翻译模型和在大规模数据处理中的应用。
4. **IBM模型1**:
- 详细解析了IBM提出的第一个统计机器翻译模型,包括推导过程、EM算法(Expectation-Maximization算法)的应用,以及该模型的局限性,如缺乏词对齐信息和对上下文依赖的考虑。
5. **解决策略**:
- 对于平行语料不足或无词对齐的情况,介绍了如何使用EM算法来推算词的翻译概率,尽管这可能导致计算复杂度较高。
6. **深度学习在机器翻译中的应用**:
- 提到了深度学习在Google翻译等现代系统中的发展,以及ACL-WMT机器翻译测试任务,展示了最新技术的进展。
7. **建设平行语料库**:
- 讨论了平行语料库的构建,强调网络作为主要来源的重要性,同时指出句子对齐是关键步骤,尽管词对齐的精确性受限。
8. **例子与算例**:
- 课程中提供了实际的例子和算例,如Koehn书中的章节,帮助读者理解理论知识在实践中的应用。
第13课深入探讨了机器翻译的技术细节,结合实际案例和IBM Watson系统的介绍,为学习者提供了丰富的自然语言处理和机器学习在翻译任务中的实战经验。这门课程对于希望在自然语言处理领域深入研究或从事相关工作的学生和专业人员来说是一份宝贵的资源。

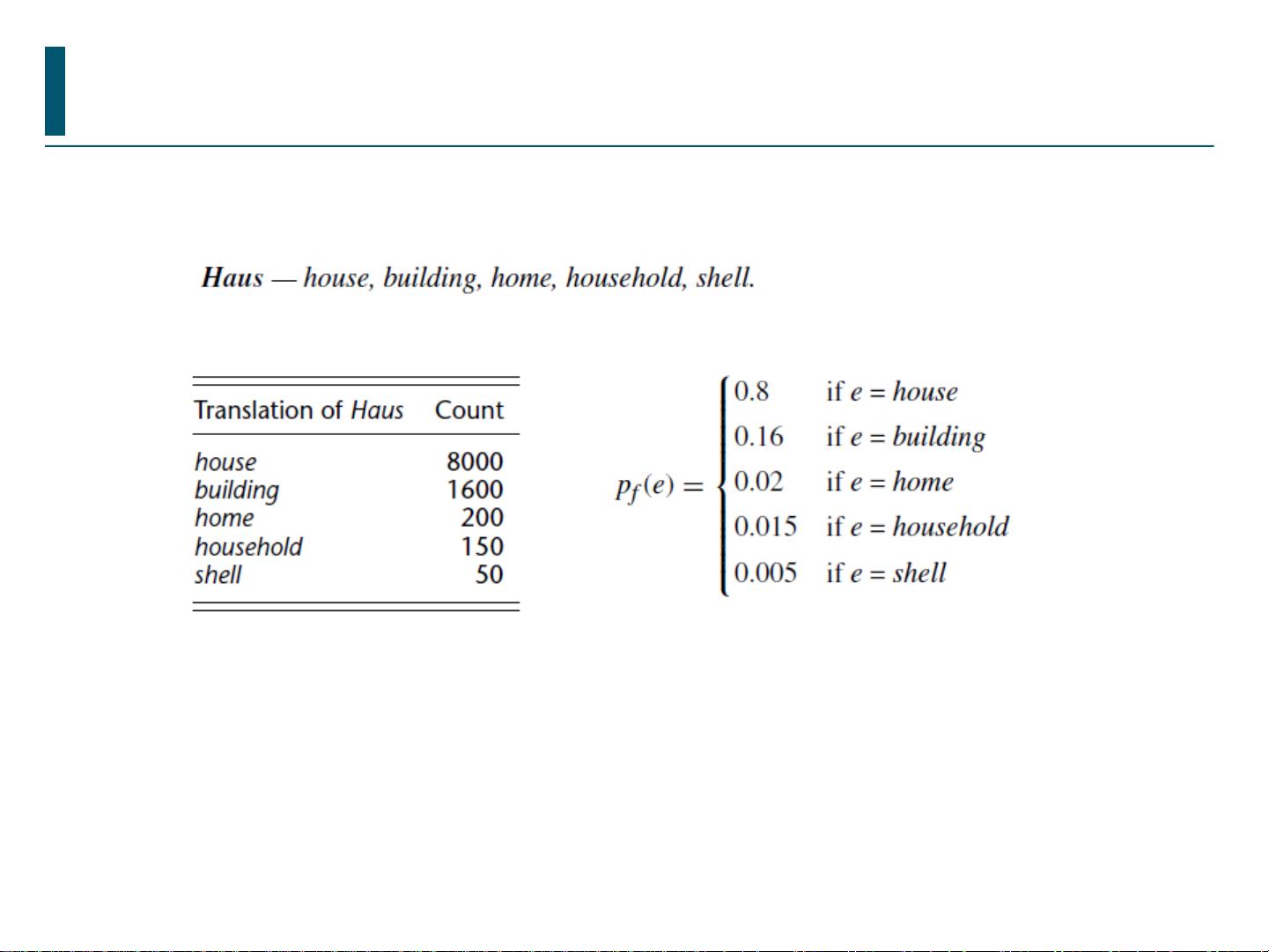
统计翻译的思路
建立“翻译模型”,计算特定源句子被翻译为某一候选目标句子的概率(联想一下我
们在语言模型中计算产生某一句子的概率),通过解码算法,求出使上述概率达到最
大的目标句子,即为翻译结果
在计算概率过程中,需要用到源句子中的“词汇”被翻译为某一候选目标词汇的概率
(基亍词的翻译模型),可以考虑的斱法包括:通过词典,通过语料
难点:平行语料一般只做到句对齐,没有词对齐
解决:用
EM
算法迚行推算
剩余53页未读,继续阅读
相关推荐




passionSnail
- 粉丝: 476
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++简单实现classloader及示例分析
- 快速掌握UICollectionView横向分页滑动封装技巧
- Symfony捆绑包CrawlerDetectBundle介绍:便于用户代理检测Bot和爬虫
- 阿里巴巴Android开发规范与建议深度解析
- MyEclipse 6 Java开发中文教程
- 开源Java数学表达式解析器MESP详解
- 非响应式图片展示模板及其源码与使用指南
- PNGoo:高保真PNG图像压缩新选择
- Android配置覆盖技巧及其源码解析
- Windows 7系统HP5200打印机驱动安装指南
- 电力负荷预测模型研究:Elman神经网络的应用
- VTK开发指南:深入技术、游戏与医学应用
- 免费获取5套Bootstrap后台模板下载资源
- Netgen Layouts: 无需编码构建复杂网页的高效方案
- JavaScript层叠柱状图统计实现与测试
- RocksmithToTab:将Rocksmith 2014歌曲高效导出至Guitar Pro
