Apriori与FP-Growth算法深度解析:效率对比与规则生成
需积分: 0 28 浏览量
更新于2024-08-05
收藏 672KB PDF 举报
数据科学领域中,数据挖掘算法是关键的技术手段,其中Apriori与FP-Growth算法是两种常用的关联规则学习算法。本文将深入探讨这两种算法的流程、效率以及它们的应用。
1. Apriori算法与FP-Growth算法流程
- Apriori算法:
a. 基本概念包括支持度和置信度,支持度衡量一个项集在所有交易中出现的频率,置信度则表示在一项事件发生时另一项事件发生的概率。
b. 算法流程分为两个主要步骤:首先通过迭代找出所有频繁项集,即满足最低支持度的项集;其次,基于频繁项集构建规则,通过递归方式挖掘更高阶的频繁项集,直至无法发现新的。
c. 逻辑和流程图直观展示了算法的工作原理,从频繁1-项集开始,逐步扩展到频繁k-项集。
- FP-Growth算法:
a. 该算法从数据库开始,统计属性出现频率并排序,删除低频属性。
b. 对每个数据记录进行处理,插入FP-tree,构建条件模式库,然后挖掘频繁项集。
c. 流程图展示了算法的具体操作步骤,它仅需遍历两次数据,相比Apriori具有更高的效率。
2. 算法效率对比
- Apriori算法:通过多次扫描数据库查找频繁项集,效率较低,特别是数据量较大时,性能开销明显。
- FP-Growth算法:尽管初始数据集较小时两者效率差距不大,但当数据规模增大时,FP-Growth凭借其在构造FP-tree时减少数据扫描的特性,显示出明显的效率优势。
3. FP-Growth算法与关联规则
- FP-Growth算法本身生成的是频繁项集,而非关联规则。若要得到关联规则,需要进一步处理生成的频繁项集,通过设置置信度阈值筛选出强关联规则。
总结来说,Apriori算法虽然经典但效率相对较低,而FP-Growth算法则通过优化数据结构和扫描策略,提高计算效率,尤其在大数据场景下更具优势。理解这两种算法的区别和适用性,有助于在实际的数据挖掘项目中做出更合理的选择。在实际应用中,可能会根据具体需求和数据特点,结合Apriori和FP-Growth的优点,进行混合使用或选择最适合的算法。
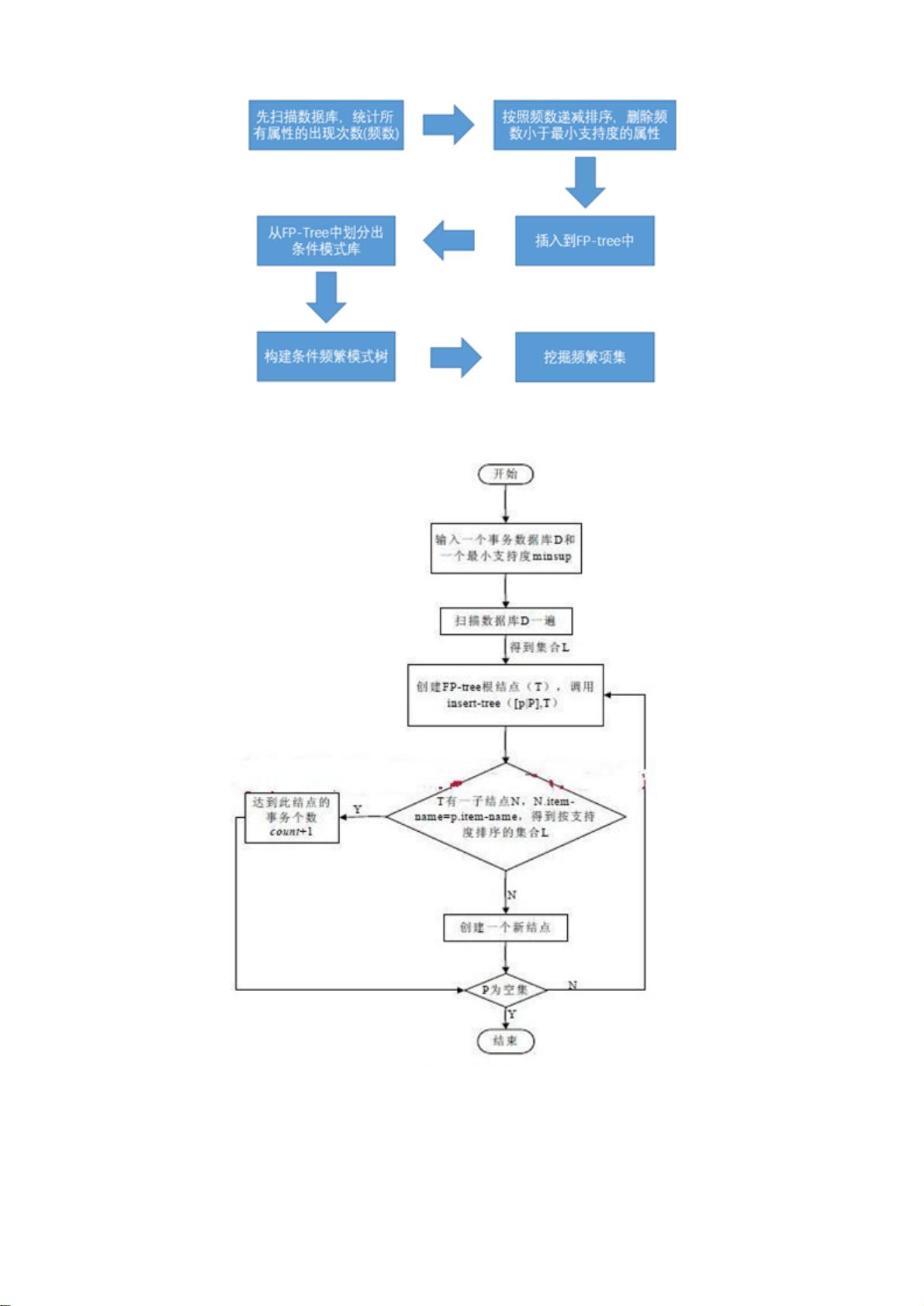
1.3.3 算法流程图
2. Apriori与FP-Growth算法效率对比
2.1. Apriori 算法实现
代码详见附录1
2.2. FP-Growth算法实现
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2021-07-14 上传
2022-08-03 上传
2022-08-03 上传
2022-06-29 上传
2021-07-14 上传

杜拉拉到杜拉拉
- 粉丝: 26
- 资源: 325
 我的内容管理
展开
我的内容管理
展开







最新资源
- freemarker中文手册
- 关于公平的竞赛评卷系统的研究
- NS2实例,Tcl语法
- ArcDGis9.2 系列产品介绍及开发
- 基于工作流的信息管理系统研究
- php常用算法(doc)
- 展望系统辨识(Perspectives on System Identification, by Ljung, 2008)
- 2009年信息系统项目管理师考试大纲
- 网管手册:三十五例网络故障排除方法
- 中望CAD2008标准教程
- ajax实战中文版.pdf
- C++ Templates 全览.pdf
- 串口通信编程大全.pdf
- 史上最全电脑键盘每个键的作用
- JavaScript.DOM编程
- Microsoft Visio详尽教程.pdf
