




Transformer中cube分区实现与优化
需积分: 24 53 浏览量
更新于2024-09-14
收藏 380KB PDF 举报
"cognos transformer cube 分区"
在IBM Cognos Transformer中, Cube Group(也称为Cube分区)是一种优化大数据分析性能的技术。当处理的数据量非常大时,通过分区可以有效地管理和加快数据的访问速度。以下是实现Cube Group的具体步骤和相关知识点:
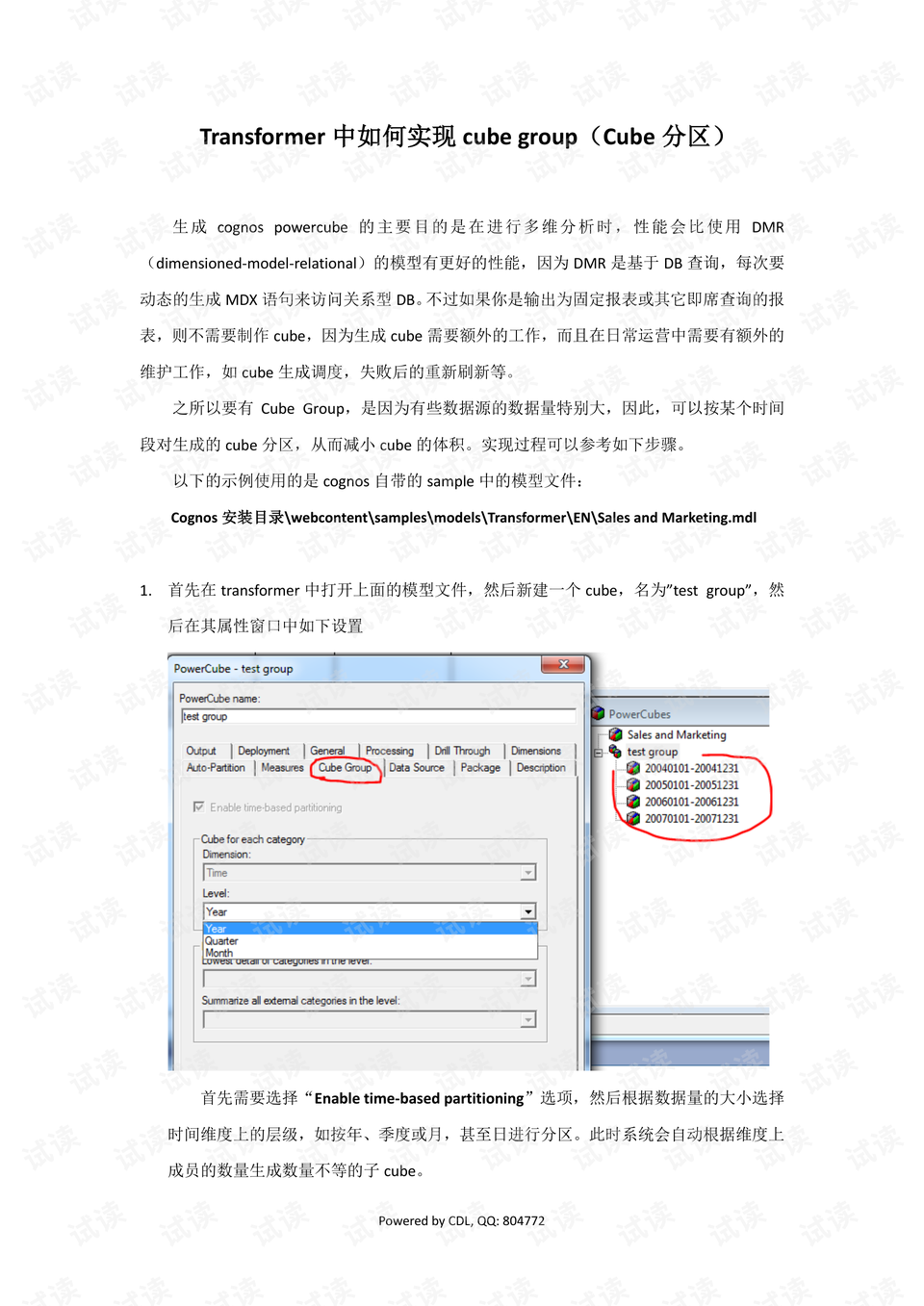
1. **启用时间基础分区**:
当你需要根据时间维度对大量数据进行分区时,可以在创建Cube时选择“Enable time-based partitioning”选项。这样,你可以按照年、季度、月甚至日划分数据,每个分区对应一个特定的时间段。这有助于减少单个Cube的大小,提高查询效率,特别是对于那些时间敏感的分析需求。
2. **选择分区维度**:
如果不使用时间为基础的分区,你可以基于其他维度进行分区,例如地理位置、产品类别等。这将根据所选维度的成员数量创建相应的子Cube。选择合适的分区维度是优化性能的关键,因为它直接影响到数据的加载速度和内存占用。
3. **创建Cube**:
在Transformer中,新建Cube并为其设置属性后,可以通过右键单击主Cube并选择“Create Selected PowerCube”来生成Cube。这是一个后台进程,如果无误,系统将提示Cube创建成功,并在指定目录下生成相关文件。
4. **文件结构**:
生成的Cube文件通常包括主Cube文件(例如,".mdc"扩展名)和元数据文件(例如,".vcd"扩展名)。此外,子目录下会包含根据所选分区策略生成的各个子Cube文件。每个子Cube代表一个特定时间区间或其他维度的分区。
5. **维护与调度**:
创建Cube后,需要定期维护和刷新,特别是在数据更新时。这通常通过调度任务来实现,以确保Cube始终包含最新的数据。如果刷新过程中出现错误,可能需要手动干预并重新执行刷新操作。
6. **性能优势**:
使用Cube Group的主要优势在于提升性能。由于数据被分割成更小的部分,查询时只需处理相关分区,减少了数据读取时间和内存消耗。这对于大型数据分析项目尤其有益,能够提供更快的响应时间和更好的用户体验。
7. **设计考虑**:
在设计Cube Group时,需要权衡分区粒度与性能之间的关系。过于细粒度的分区可能导致更多的Cube文件,增加存储需求;而过于粗粒度的分区则可能无法充分利用分区的优势。因此,理解业务需求和数据模式对于确定最佳分区策略至关重要。
8. **适应性调整**:
随着数据的增长或业务需求的变化,可能需要调整Cube Group的配置。这可能涉及修改现有的分区策略,或者添加新的分区维度,以保持系统的高效运行。
9. **工具支持**:
Cognos Transformer提供了直观的界面,使得用户可以方便地创建、管理和优化Cube Group,无需深入理解底层的多维数据模型或MDX语言。
通过以上步骤和知识点,你可以更好地理解和应用Cognos Transformer中的Cube Group功能,从而有效地管理和优化大规模数据集的分析性能。
下载后可阅读完整内容,剩余5页未读,立即下载
查看更多
275 浏览量
291 浏览量
451 浏览量
275 浏览量
116 浏览量
126 浏览量
199 浏览量
215 浏览量
145 浏览量

margiex2
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android framebuffer截图工具:支持各种屏幕和颜色深度
- 重构VBA提高Excel工作效率与性能分析
- C#开发新浪微博客户端基于OAuth2.0授权机制
- E路文章系统PHP版v1.0功能介绍与下载
- JAVA实现LUCENE与MYSQL索引构建及搜索教程
- IPFS Wormhole:实现无需接收的安全文件传输
- Centos7环境Oracle11.2.0.1安装RPM文件及命令指南
- AD7656模数转换器代码实例解析
- 自定义URL触发本地程序:实现类似QQ聊天效果
- 数据结构动态演示软件,自学更易理解
- STM32F439单片机串口通信编程实例
- 开源游戏引擎Pangaea:强大功能与世界构建器
- ASP实现动态无限级目录树的源码解析
- 深入解析.NET Framework 4与应用程序兼容性
- 《深入浅出JavaScript》源码剖析与错误勘误
- Git风格指南:统一代码管理的最佳实践






















