Kafka开发详解:大数据云计算教程中的关键环节
版权申诉
49 浏览量
更新于2024-07-07
收藏 321KB PPTX 举报
"该资源为一个关于大数据与云计算的教程课件,涵盖了多个主题,包括Hadoop、MapReduce、YARN、Hive、HBase、Pig、Zookeeper、Sqoop、Flume、Kafka、Strom以及Spark等。特别强调了Kafka的开发,讲述了如何搭建Kafka开发环境,如何创建Kafka项目,并涉及到Kafka的生产者和消费者线程的构建,以及数据持久化的原理和重要性。"
在大数据领域,Kafka是一种分布式流处理平台,广泛用于实时数据处理和消息传递。本课件中的Kafka开发部分主要涉及以下几个知识点:
1. **Kafka环境搭建**:讲解如何配置和创建Kafka项目,包括将`KAFKA_HOME/lib`下的库文件添加到项目的类路径,以便于开发。
2. **生产者与消费者实现**:介绍了如何构建生产者线程来发送消息,以及构建消费者线程来消费这些消息。这对于理解Kafka的核心工作流程至关重要。
3. **Kafka属性**:讨论了Kafka中常见的属性设置,这有助于定制Kafka的行为以适应特定的应用场景。
4. **数据持久化**:Kafka的一大特点是其高效的数据持久化机制。课件解释了如何利用文件系统实现快速的数据读写,尽管传统观念认为硬盘较慢,但通过操作系统级别的优化,如预读和延迟写入,可以达到接近内存的速度。同时,文件系统允许数据在系统重启后无需重新加载,提高了系统的可用性。
5. **内存与性能**:对比了内存缓存和文件系统缓存的优缺点,特别是对于大规模数据时,内存压力可能导致频繁的垃圾回收,影响性能。Kafka选择直接将数据写入文件系统日志,避免了这些问题,同时简化了数据一致性管理。
6. **消息系统中的数据持久化**:课件可能会提到其他消息系统的数据持久化机制,并对比Kafka的独特之处,例如,很多系统在内存中缓存数据后再刷入硬盘,而Kafka直接写入日志,提供了更好的性能和可靠性。
通过学习这些内容,开发者将能深入理解Kafka的工作原理,以及如何在实际项目中有效地使用Kafka进行大数据处理和消息传递。同时,课程还覆盖了大数据生态系统中的其他关键组件,为全面掌握大数据技术栈提供了坚实的基础。
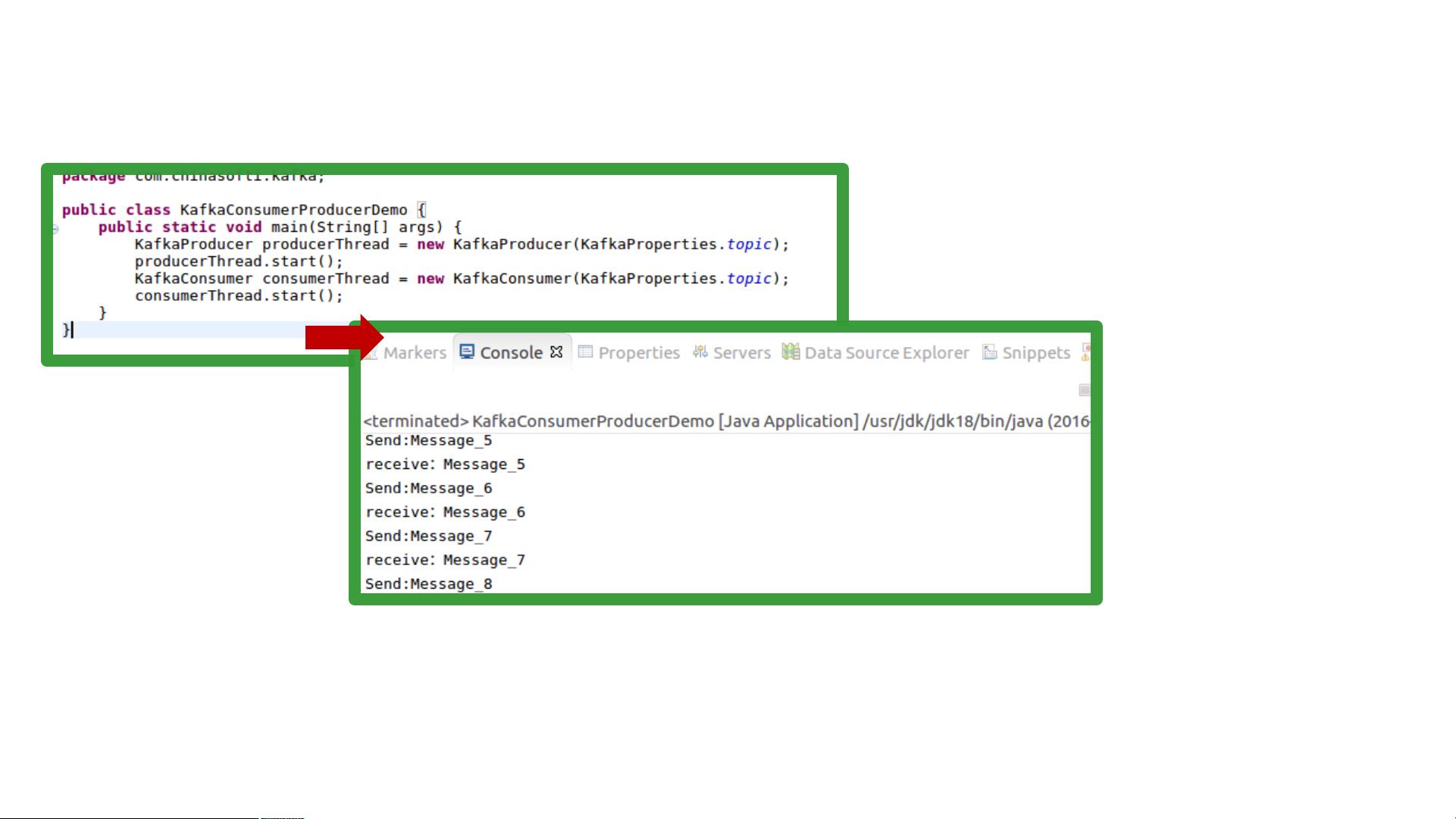
测试代码是否能够正常执行
• 创建测试代码测试功能是否正常:
执行结果
剩余33页未读,继续阅读
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传

passionSnail
- 粉丝: 467
- 资源: 7836
 我的内容管理
展开
我的内容管理
展开







最新资源
- VxWorks操作系统板级支持包的设计与实现
- Vx Works环境下串口驱动程序设计
- Vx Works环境下IP-CATV网关驱动程序的设计与实现
- Linux与VxWorks的板级支持包开发的比较与分析
- 基于公共机房安排管理系统
- ISaGRAF在SUPMAX500组态软件中的应用
- Ipv6高级套接口的研究和实现
- HTTP在嵌入式系统中的应用及扩展
- Oracle9i数据库管理实务讲座.pdf
- PL/SQL程序設計pdf格式
- CDN网络路由技术CDN网络路由技术
- 1700mm精轧机组液压AGC程序包变量监控
- 4种实时操作系统实时性的分析对比
- DOM文档对象模型(微软最近教程)
- c与c++嵌入式系统编程.pdf
- oracle傻瓜手册
