李宏毅笔记:序列标注(ST4)详解:HMM与CRF在命名实体识别中的应用
196 浏览量
更新于2024-08-28
收藏 1.09MB PDF 举报
在本篇学习笔记中,我们将探讨Sequence Labeling,一种在自然语言处理(NLP)中常见的任务,它涉及到对输入序列(如句子)中的每个元素分配一个预定义的标签或类别。Sequence Labeling的主要应用包括命名实体识别(如识别人名、地名和组织名),例如在句子"Harry Potter is a student of Hogwarts and lived on Privet Drive"中,这个任务就是确定哪些词属于哪一类实体。
核心概念包括:
1. **定义**:虽然最初假设输入和输出序列长度相等(设为L),但实际情况下可能更复杂。RNN(循环神经网络)可以处理这类任务,但它并不是唯一的方法,结构化学习方法(如隐马尔可夫模型HMM和条件随机场CRF)也有所应用。
2. **隐马尔可夫模型(HMM)**:HMM是一种统计模型,通过观察序列数据来预测下一个状态。分为两步,第一步是建模状态转移概率(HMM – Step 1)和观测概率(HMM – Step 2)。HMM的数学表达涉及概率链规则和前向-后向算法(Viterbi Algorithm),用于估计参数和找出最可能的标签路径。
3. **条件随机场(CRF)**:CRF是一种无向图模型,通过特征向量(Feature Vector)捕捉单词之间的依赖关系。训练时采用似然最大化准则(CRF – Training Criterion),并使用Viterbi算法进行推断。与HMM相比,CRF通常能更好地处理复杂的结构化输出。
4. **性能比较**:Structured Perceptron和Structured SVM(支持向量机)是两种常见的结构化学习算法,它们在Sequence Labeling任务中的性能会有所不同,需要根据具体场景进行选择和优化。
5. **中文命名实体抽取挑战**:对于中文文本,由于字符和词语的多音字问题,例如“楊公再興之神”和“馮氏埋香之塚”,命名实体识别更加复杂,需要考虑上下文信息和更细致的特征工程。
通过这个学习笔记,读者可以深入理解Sequence Labeling的基础原理、常见算法(如HMM和CRF)及其在实际任务中的应用,以及如何处理不同语言的特点,为NLP实践提供有力工具。
番外番外.李宏毅学习笔记李宏毅学习笔记.ST4.Sequence Labeling
文章目录文章目录Sequence LabelingDefinitionExample Task: POS taggingHidden Markov Model (HMM)HMM – Step 1HMM – Step 2HMM的数学表达HMM– Estimating the probabilitiesHMM – Viterbi
AlgorithmHMM – SummaryConditional Random Field (CRF)P(x,y) for CRFFeature VectorCRF – Training CriterionCRF – InferenceCRF v.s. HMMCRF – SummaryStructured Perceptron/SVMStructured
PerceptronStructured SVMPerformance of Different Approaches总结
公式输入请参考:在线Latex公式
课程PPT
Sequence Labeling
Definition
来看看定义(这里的定义其实并不严格,先暂时假定输入和输出的Sequence的长度都是相等的,为LLL,实际上有很多种情况,其实在前面的课程有讲过):
RNN can handle this task, but there are other methods based on structured learning(two steps, three problems).
典型应用:
•Name entity recognition
• Identifying names of people, places, organizations, etc.
from a sentence
• Harry Potter is a student of Hogwarts and lived on Privet Drive.
识别结果:
people: Harry Potter
organizations: Hogwarts
places: Privet Drive
not a name entity: 其他部分
但是对于中文的抽取很麻烦,例如下面两句要抽取人名:
楊公再興之神(出自金庸《笑傲江湖》)
馮氏埋香之塚(出自金庸《射雕英雄传》)
下面来看例子
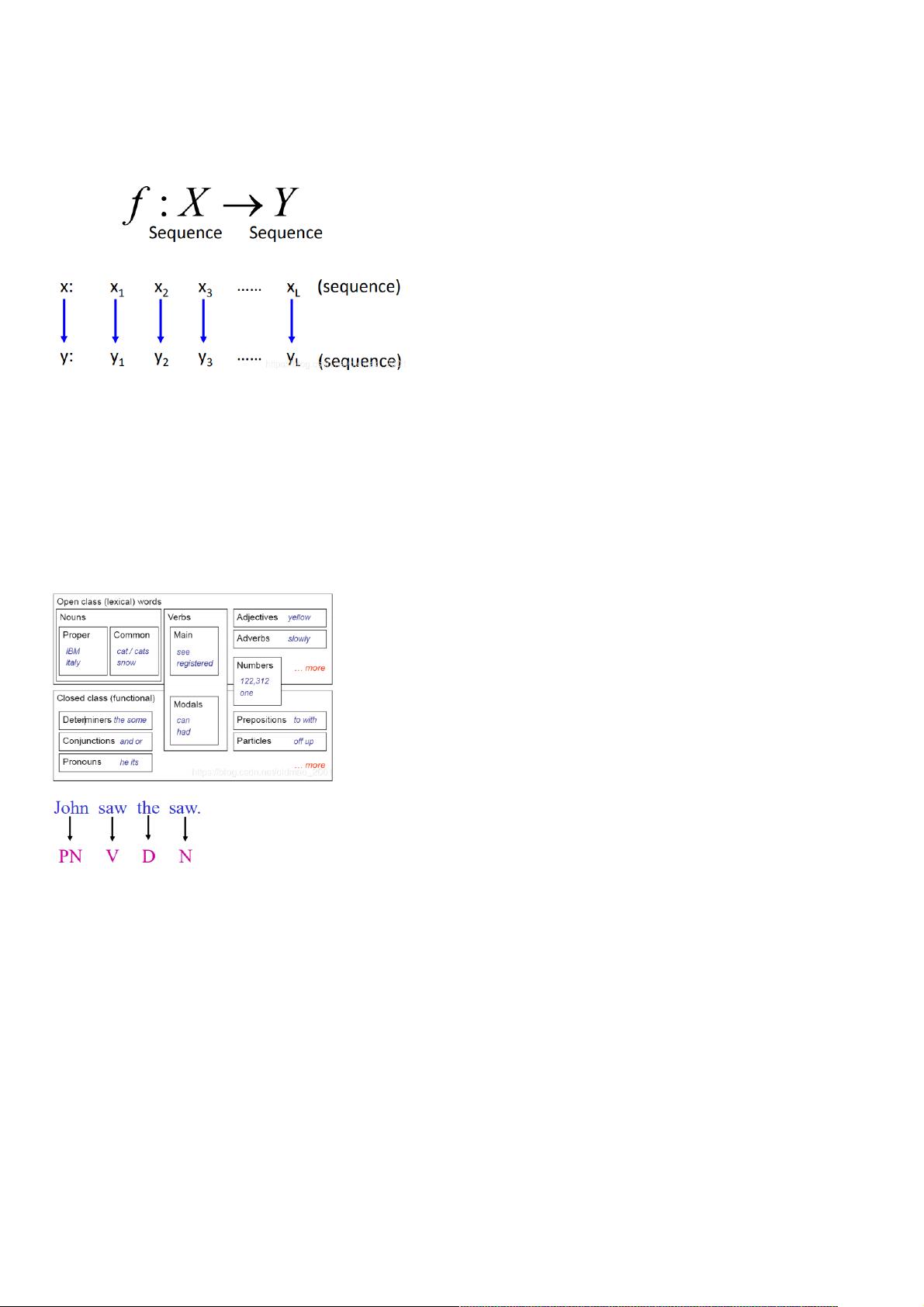
Example Task: POS tagging
Annotate each word in a sentence with a part-of-speech.输入一个句子,输出每个词的类型,例如名词,动词什么的。
Useful for subsequent syntactic parsing and word sense disambiguation, etc.
下面是一个小例子,看到都是saw,有不一样的词性。
这个看起来很简单的东西,明显是不可以直接把词和词性保存下来,然后直接做简单的查询就行了。
“saw” is more likely to be a verb V rather than a noun N,为什么会知道第二个saw是名词呢?因为它在the后面
the second “saw” is a noun N because a noun N is more likely to follow a determiner.
也就是说词性和词序有很大关系。下面就将考虑词序的structed learning的技术依次介绍。
Hidden Markov Model (HMM)
先来看看人是如何构造一个句子:
Step 1
• Generate a POS sequence
• Based on the grammar
Step 2
• Generate a sentence based on the POS sequence
• Based on a dictionary
这实际上和HMM假设是一样的。
HMM – Step 1
根据脑中的语法建立一个POS的sequence:
下载后可阅读完整内容,剩余7页未读,立即下载
2021-05-16 上传
122 浏览量
218 浏览量
2023-08-05 上传
2021-08-15 上传

weixin_38672731
- 粉丝: 5
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
