数据流缓存技术:分布式系统的挑战与解决方案
27 浏览量
更新于2024-07-15
1
收藏 1.3MB PDF 举报
"本文主要探讨了分布式数据流计算系统中的数据缓存技术,分析了数据流编程模型的优势以及在分布式环境下的挑战,特别是在数据生产和消费速度不匹配时可能导致的问题。通过对多个典型分布式数据流系统和消息队列系统的分析,文章评估了当前消息队列对数据流缓存的支持程度,并对数据缓存技术进行了深入阐述,最后对未来数据流缓存系统的需求和发展趋势进行了展望。"
分布式数据流计算系统的数据缓存技术是解决系统效率和性能的关键。数据流编程模型,因其高度并行计算能力、流水线处理机制以及对函数式编程的支持,成为众多计算系统首选的模型。然而,在分布式和异构数据流环境中,由于不同算子之间数据生成与处理速率的差异,可能导致数据积压或运算资源浪费。
缓存技术在这样的背景下显得尤为重要。它能有效缓解数据传输的延迟,保证数据的高效流动,防止数据源过载和数据处理节点的闲置。通过设计和实现数据流缓存系统,可以动态存储和调度数据,使得整个系统能够以更优的方式运行。
文章选取了几个具有代表性的分布式数据流系统,如Apache Flink、Apache Spark等,这些系统都面临数据缓存的挑战,并且分析了它们如何通过内置的缓存机制来优化数据处理。同时,也讨论了分布式消息队列系统(如Kafka)在数据流缓存中的角色,这些消息队列系统通常用于在分布式组件间传递和暂存数据,提高了数据传输的可靠性和效率。
当前的消息队列系统在支持数据流缓存方面已有一定的成熟度,但仍然存在优化空间。例如,提高缓存策略的智能化,根据数据特性动态调整缓存大小,以及提供更细粒度的缓存控制,都是未来研究的重点。
此外,随着大数据和实时分析需求的增长,未来的数据流缓存系统需要具备更强的扩展性、更低的延迟以及更高的容错能力。研究方向可能包括:更有效的数据压缩技术以减少存储需求,利用机器学习预测数据访问模式以优化缓存策略,以及开发适应云环境的弹性缓存解决方案。
本文全面概述了数据流缓存技术的现状,指出了存在的问题,并对未来发展提出了指导性建议,为构建更加高效、智能的分布式数据流计算系统提供了理论依据和技术参考。
BIG DATA RESEARCH 大数据
104
式或异构的环境下,算子也可以在不同的
机器或容器内执行。只要数据到达,算子
即 可 开 始 处 理 ,从 而 使 得 各 个 算 子 形 成 流
水线的结构,数据则在流水线中被并行处
理,这种处理方式在处理具有复杂依赖关
系的程序逻辑时有天然的优势。
在 数 据 流 图 中 ,用 节 点 和 边 描 述 程 序 逻
辑 。 其 中 ,节 点 表 示 操 作 , 即 数 据 流 的 逻 辑
计 算 单 元 ,有 向 边 表 示 数 据 依 赖 关 系 。数
据流计算模型的核心思想是用数据控制计
算 。当 一 个 操 作 所 需 的 数 据 全 部 准 备 完 毕 之
后,便可以启动运算。当只有部分数据到达
时,则需要等待。当一个操作执行完成并将结
果传递给下一个操作后,无论下一个操作是
否能正常执行,这个操作都可以立刻对新数
据进行计算。如此,整个程序便可以以流水
线的方 式并行执行。
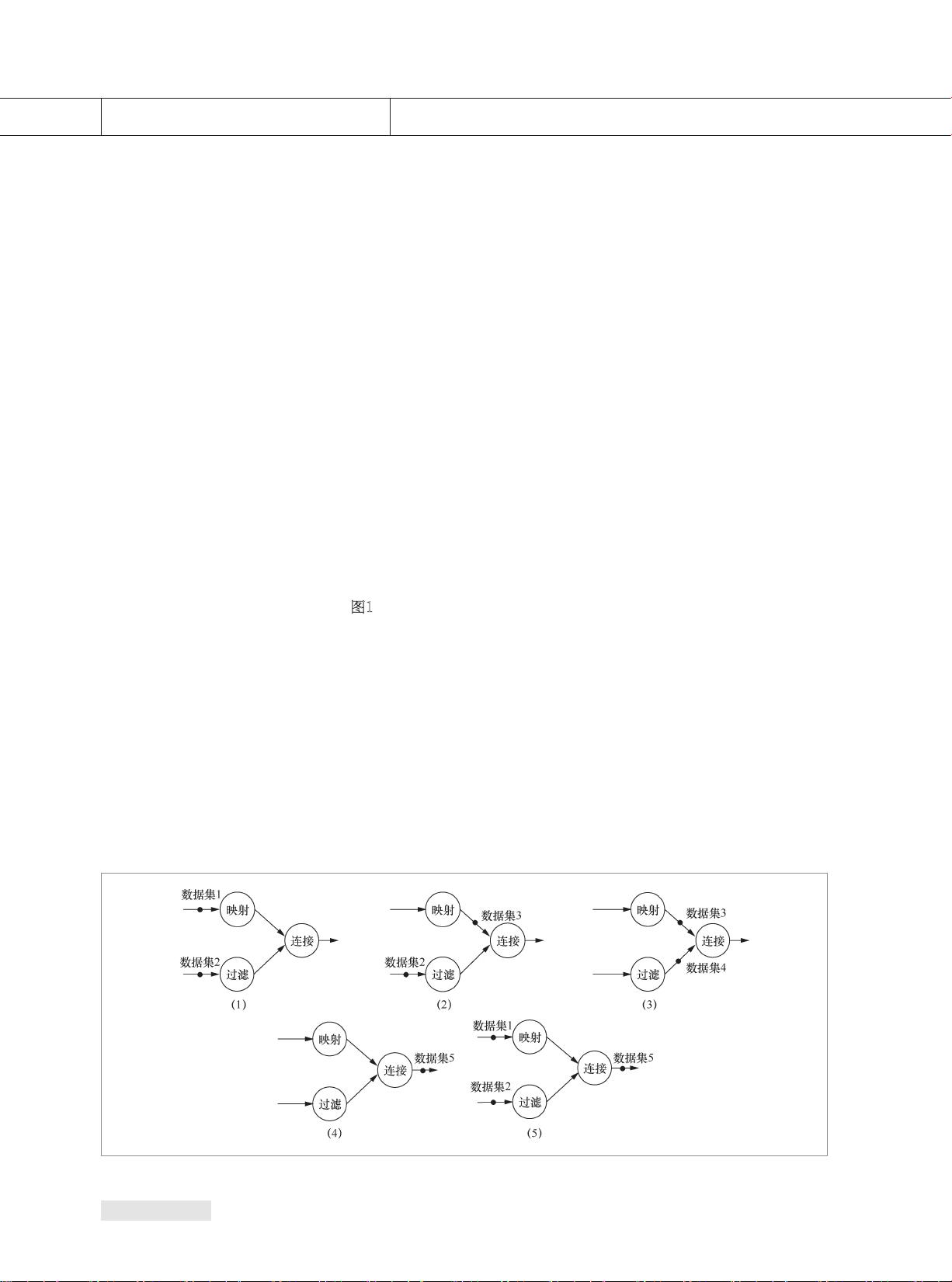
图1显示了在数据流系
统Spark中分别对2组数据进行映射(map)
和 过 滤(f i l t e r)之 后 再 进 行 连 接( j o i n)的
执行过程,弹性分布式数据集(RDD)表
示Spark中的基本数据集。首先,数据集1
(RDD1)和数据集2(RDD2)准备完毕,并
被输入计算节点中,分别执行映射和过滤
操作,这两步没有相互依赖的关系,也没有
执行先后之分。然后,当连接算子的2个操
作数都准备完毕后,即数据集3(RDD3)和
数据集4(RDD4)已经计算得出时,执行连
接 操 作 。最 后 ,计 算 出 结 果 ,数 据 向 下 一 个
计算单元传输。在连接操作进行的同时,如
果有新的映射或过滤操作数到达,映射操
作或过滤操作可以同时执行。如此,数据流
图中多个计算节点便可以以流水线的方式
并行执行。当一个程序有多个这样的计算
过 程 时 ,它 们 之 间 也 可 以 以 流 水 线 的 方 式 并
行执 行。
传统的计算机采用控制流作为计算机
的 核 心 ,即 冯 · 诺 伊 曼 体 系 结 构 ,它 通 过 一
个中央处理器执行计算任务,用程序计数
器根据程序控制逻辑控制指令依次执行。
数据流的体系结构不同于传统的冯·诺伊
曼体系结构,它以数据为驱动,数据在程
序运行过程中起主导作用,这对于计算机
发展来说是一个突破。针对数据流计算机
的具体设计方案有很多,学术界和工业界
也相继成功研制出一些专用机。以全新的
体系结构设计出的数据流计算机不再需要
CPU
[26]
,而是把功能分散到各个部件中,
取消了程序计数器,以数据是否到达异步
控 制 每 一 条 指 令 的 执 行 ,这 样 更 容 易 实 现
数据的并行。但这种新型的体系结构仅适
图 1 数据流模型示例
2020027-4
剩余15页未读,继续阅读
2021-09-14 上传
2021-08-08 上传
2021-08-08 上传
428 浏览量
262 浏览量
255 浏览量
156 浏览量
187 浏览量
2023-06-11 上传

weixin_38699551
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
