实体关系联合抽取方法研究综述:大数据时代下的挑战和突破
版权申诉
147 浏览量
更新于2024-03-02
1
收藏 1MB DOCX 举报
随着大数据时代的到来,人们日常生活中会产生海量的数据,包括新闻报道、博客、论坛、研究文献以及社交媒体评论等。在这些数据中,有价值的信息往往隐藏在大量的文本中。信息抽取(information extraction, IE)的目的就是从这些数据中快速高效地提取有用的信息。实体关系联合抽取作为信息抽取的核心任务,在近年来受到学术界和工业界的广泛关注。实体关系联合抽取通过对文本信息进行建模,自动识别实体、实体类型以及实体之间的关系类型,为知识图谱构建、智能问答和语义搜索等下游任务提供了基础支持。
传统的流水线方法将实体关系联合抽取分解为命名实体识别和关系抽取两个独立的子任务。在传统的流水线方法中,首先执行命名实体识别任务,然后根据命名实体识别的结果来完成关系抽取任务。这两个子任务使用的模型是相互独立的,它们可以在不同的训练集上进行训练。然而,传统的流水线方法通常会引发一些问题,包括误差传播和子任务间缺乏交互。例如,命名实体识别子任务产生的误差无法在关系抽取子任务中得到纠正,从而影响了关系抽取的结果质量。此外,流水线方法忽略了命名实体识别和关系抽取之间的交互作用,缺乏整体抽取任务的全局优化。
为了解决传统流水线方法存在的问题,近年来,研究者提出了一系列新的有监督实体关系联合抽取方法。这些方法旨在通过整合实体识别和关系抽取两个子任务,实现更为准确和高效的信息提取。其中,一些方法采用端到端的神经网络模型,将实体关系联合抽取任务作为一个整体进行建模和训练。这种端到端的方法能够在训练过程中同时优化实体识别和关系抽取,减少误差传播,并提高抽取的准确性。另外,一些方法引入了注意力机制和迭代模型,在实体关系联合抽取中增加了对实体上下文信息和关系上下文信息的建模,从而提高了抽取任务的性能。
总体来看,有监督实体关系联合抽取方法在近年来取得了巨大的进展,为信息抽取领域带来了新的机遇和挑战。未来,随着深度学习和自然语言处理技术的不断发展,我们可以预期实体关系联合抽取方法将进一步提升其抽取准确性和效率,为实现智能文本分析和知识发现提供更强有力的支持。

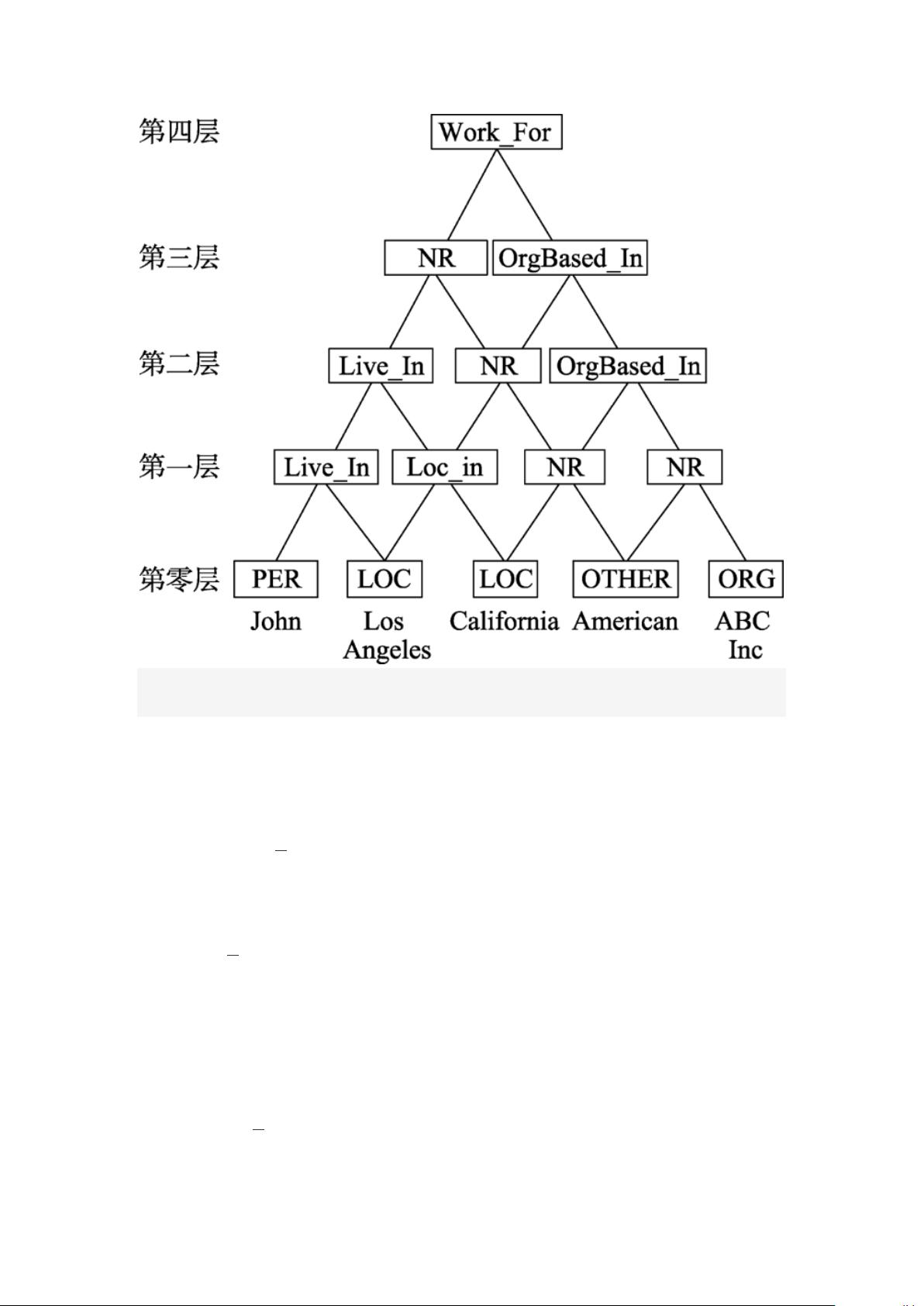
2.2 卡片 金 字 塔 解析
整数线 性规划方法根据多个独立局部分类 器 的结果计算全局最优解以实
现联合抽取,但局部分类器之间没有交互。卡片金字塔解析方法则用图结构编
码句子中实体信息和关系类型信息,局部分类器彼此交互,提升了联合抽取的性
能。
Kate 等
[33]
将联合抽取转换成图节点标注的问题,图的结构类似金字塔,因此
称为卡片金字塔模型,如图 2 所示。这种类似树的图结构在最高层有一个根节
点,中间层是内部节点,底层是叶子节点,句子中的实体对应叶子节点,叶子节点
标注为实体类型。图的层数和叶子节点数相等,从图的底层到顶层,每次减少一
个节点。除去最底层节点,每一层的节点表示与节点相关的最左和最右两个叶
子节点之间可能存在的关系。文献[33]的两个局部分类器为实体识别分类器和
关系抽取分类器,都采用支持向量机(support vector machines,SVM)
[34]
进行
训练,根据局部分类器的结果构造卡片金字塔图。文献[33]采用动态规划和集束
搜索的方法设计解析算法,该方法主要由实体生成和关系生成两部分组成,根据
卡片金字塔的结构特点,分别产生叶子节点的实体信息和非叶子节点的关系信
息。最终图的节点都被标注,实现了联合抽取。
图 2
剩余37页未读,继续阅读
107 浏览量
2022-06-26 上传
2022-06-24 上传
2021-11-18 上传
2022-11-11 上传
2024-06-06 上传

罗伯特之技术屋
- 粉丝: 4506
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







