Inception-V3与YOLO在无人机图像识别中的应用
需积分: 0 16 浏览量
更新于2024-08-04
收藏 1.16MB DOCX 举报
"本文主要探讨了两种卷积神经网络(CNN)模型——Inception-V3和YOLO在图像识别和目标检测中的应用。Inception-V3着重于工程优化,解决了深度网络的优化难题和过拟合问题,而YOLO则是一种高效的目标检测one-stage算法。"
在卷积神经网络领域,Inception-V3是一个重要的里程碑,它针对传统深度CNN的挑战进行了优化。随着网络层数的增加,通常会出现模型表现力下降、优化困难以及过拟合等问题。Inception-V3通过引入分组卷积和不同视野域的并行处理,有效地减少了计算量,同时保持了模型的表达能力。分组卷积允许在同一层的不同卷积核中捕获不同层次的特征,不同组的特征之间不进行交叉计算,降低了复杂性。此外,Inception-V3还利用稀疏矩阵和Dropout机制来控制模型大小和防止过拟合。Dropout机制在全连接层中随机关闭一半的神经元,增强了模型的泛化能力,使网络能更好地应对数据的多样性。
另一款被提及的卷积网络模型是YOLO(You Only Look Once),它是目标检测领域的一-stage算法代表。YOLO将目标检测视为回归问题,直接预测图像中每个像素的边界框坐标、物体置信度和类别概率,从而实现快速检测。YOLO的工作流程包括:首先将图像调整到固定尺寸,如448×448,然后通过CNN获取边界框信息,最后通过非极大值抑制来去除冗余的检测结果。YOLO的主要优点在于其检测速度极快,能够很好地避免背景误检,具有强大的泛化能力,并且支持端到端的优化。
在实际应用中,如《基于卷积神经网络的无人机油气管线巡检监察系统》一文中,这两种模型都被用于处理无人机拍摄的图像。Inception-V3可能用于图像识别,识别油气管线的损坏情况,而YOLO则用于目标检测,快速定位管线及其潜在问题。实验显示,Inception-V3在7万张图像样本(包括6.5万张训练样本和5000张测试样本)上达到了97.9%的识别准确率,证明了其在多样环境下的有效性。同样,YOLO的高效性能也使其成为无人机巡检的理想选择,能够在一次扫描中快速准确地检测出管线的异常情况。
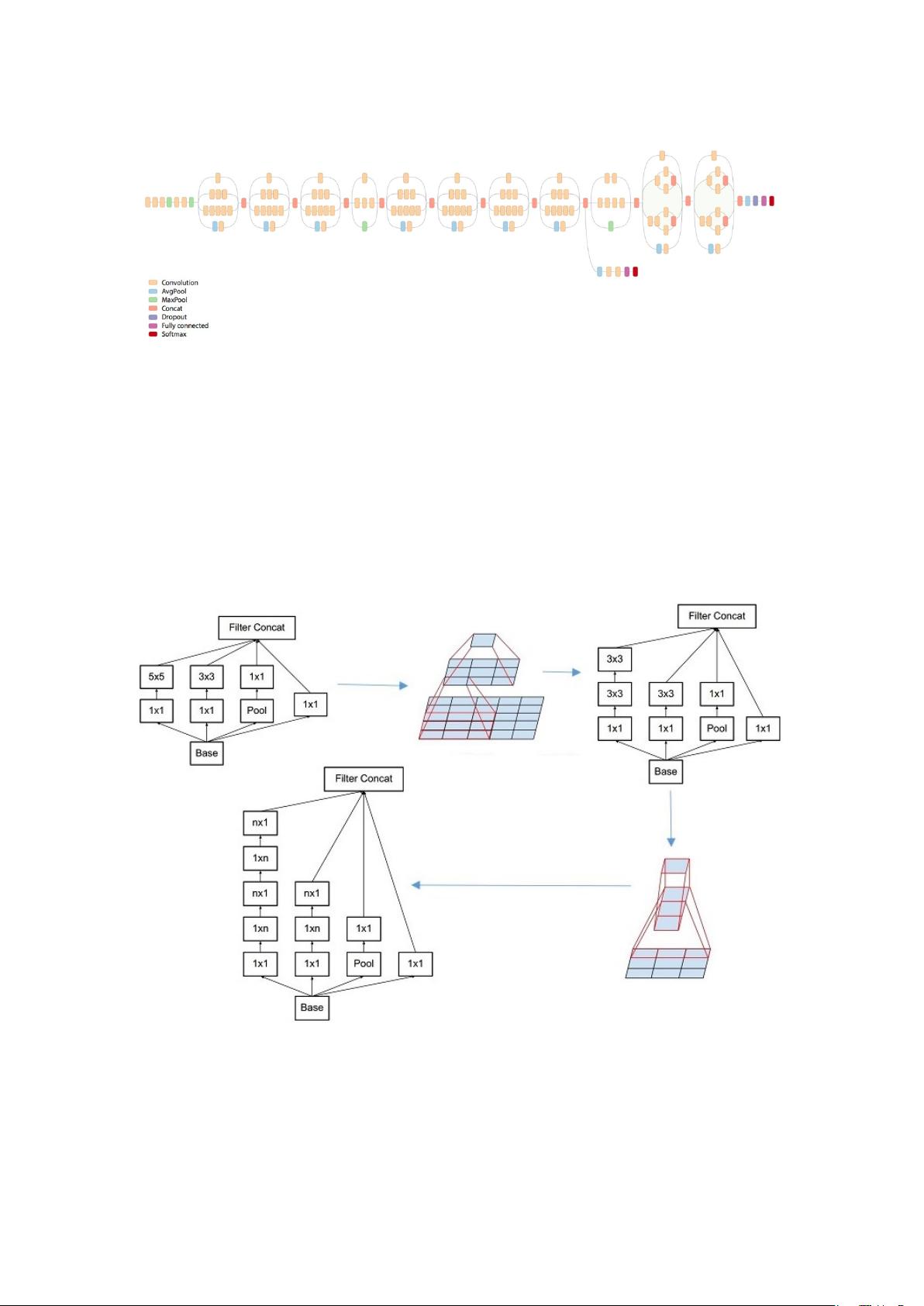
本文提到的卷积神经网络图像识别算法是基于”Inception-V3”网络结构进行设计.
使用分组卷积, 同一层上有多个卷积核,可以看到各种层级的 Feature; 不同组之
间的 Feature 不交叉计算, 减少计算量. 并引入同等视野域替换的方式. 输入图
像经过神经网络运算之后, 使用 softmax 函数计算并输出当前视野域内管道损坏
的概率, 然后上报.
Inception-V3 网络更注重于工程上的优化. 相比于普通的”卷积-深度”神经网络,
改进了: 随网络层数加深, 模型表现能力反而下降
深层网络难以优化
下载后可阅读完整内容,剩余3页未读,立即下载
2022-08-08 上传
217 浏览量
2024-05-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

洪蛋蛋
- 粉丝: 32
- 资源: 334
 我的内容管理
展开
我的内容管理
展开







