快手公司Apache Flink优化实战与大数据系统演进
28 浏览量
更新于2024-08-28
收藏 448KB PDF 举报
"快手基于Apache Flink的优化实践"
本文将探讨快手如何利用Apache Flink进行优化,涉及流式计算的背景、发展历程以及关键问题。首先,我们来看一下大数据系统的发展历程。
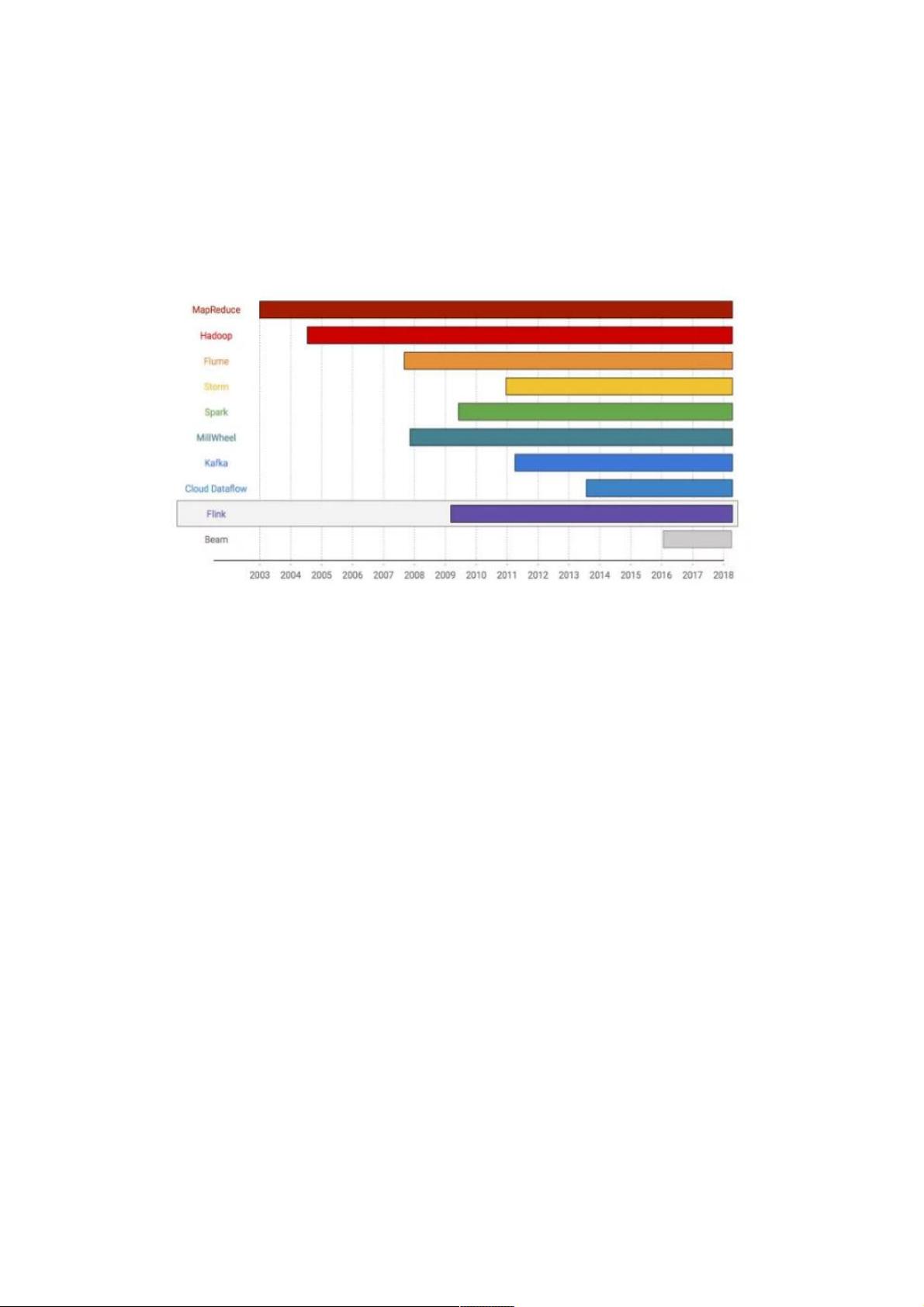
从2003年的Google MapReduce开始,它通过Map和Reduce操作定义了大数据处理的基本范式,并引入了容错机制。Hadoop随后出现,成为开源社区的明星项目,进一步推动了大数据处理的普及。然而,MapReduce在处理连续数据流时效率较低,于是出现了Flume,它通过管道连接多个作业以提高效率。
2011年,Twitter开源了Storm,它的实时处理能力和低延迟特性使其在实时计算领域崭露头角。尽管如此,Storm缺乏系统级别的故障恢复,无法确保数据一致性。为了解决这一问题,lamda架构应运而生,结合流处理的实时性和批处理的准确性,但其复杂性最终导致了维护困难。
SparkStreaming的出现弥补了这一缺陷,它基于批处理的minibatch模型实现了流式计算,提供了数据一致性保证。Google的流式计算研究如MillWheel、CloudDataflow和Beam则为流式计算带来了新的理念,特别是数据处理模型的灵活性和可恢复性。
Kafka虽然不是流式计算引擎,但它作为实时消息队列,对流式计算有着深远影响。Kafka的分区和日志机制使得数据持久化和故障恢复变得可能,同时,它对表和流的融合探索为流处理提供了新的思路。
Apache Flink在这些基础上进行了优化,借鉴了Google的流式计算思想,强调了事件时间窗口和状态管理,这使得Flink在实时计算领域表现出色。快手在实践中,很可能针对Flink的并行处理能力、状态一致性以及容错机制进行了优化,以适应其大规模的数据处理需求。
流式计算的关键问题包括:事件时间处理、数据一致性、容错机制、延迟优化以及资源管理。Flink通过其强大的状态管理能力,例如使用Changelog来记录状态变化,确保了在处理无界数据流时的数据准确性和一致性。此外,Flink的Exactly-once语义保证了在发生故障时,计算结果仍然正确。
快手可能还对Flink的并行度、调度策略以及与Kafka等数据源的集成进行了定制优化,以提高数据处理速度和整体系统的稳定性。通过这些优化,快手能够在保证实时性的同时,确保大数据处理的高效和可靠。
快手基于Apache Flink的优化实践不仅展示了流式计算在实时数据处理中的优势,也揭示了在实际应用中如何克服挑战,提升系统性能。这些经验对于其他需要处理大规模实时数据的企业具有很高的参考价值。
快手基于快手基于ApacheFlink的优化实践的优化实践
一、流式计算的介绍
流式计算主要针对 unbounded data(无界数据流)进行实时的计算,将计算结果快速的输出或者修正。
这部分将分为三个小节来介绍。第一,介绍大数据系统发展史,包括初始的批处理到现在比较成熟的流计算;第二,为大家简
单对比下批处理和流处理的区别;第三,介绍流式计算里面的关键问题,这是每个优秀的流式计算引擎所必须面临的问题。
1、大数据系统发展史
上图是 2003 年到 2018 年大数据系统的发展史,看看是怎么一步步走到流式计算的。
2003 年,Google 的 MapReduce 横空出世,通过经典的 Map&Reduce 定义和系统容错等保障来方便处理各种大数据。很快
就到了 Hadoop,被认为是开源版的 MapReduce, 带动了整个apache开源社区的繁荣。再往后是谷歌的 Flume,通过算子连
接等 pipeline 的方式解决了多个 MapReduce 作业连接处理低效的问题。
流式系统的开始以 Storm 来介绍。Storm 在2011年出现, 具备延时短、性能高等特性, 在当时颇受喜爱。但是 Storm 没有
提供系统级别的 failover 机制,无法保障数据一致性。那时的流式计算引擎是不精确的,lamda 架构组装了流处理的实时性和
批处理的准确性,曾经风靡一时,后来因为难以维护也逐渐没落。
接下来出现的是 Spark Streaming,可以说是第一个生产级别的流式计算引擎。Spark Streaming 早期的实现基于成熟的批处
理,通过 mini batch 来实现流计算,在 failover 时能够保障数据的一致性。
Google 在流式计算方面有很多探索,包括 MillWheel、Cloud Dataflow、Beam,提出了很多流式计算的理念,对其他的流式
计算引擎影响很大。
再来看 Kafka。Kafka 并非流式计算引擎,但是对流式计算影响特别大。Kafka 基于log 机制、通过 partition 来保存实时数
据,同时也能存储很长时间的历史数据。流式计算引擎可以无缝地与kafka进行对接,一旦出现 Failover,可以利用 Kafka 进
行数据回溯,保证数据不丢失。另外,Kafka 对 table 和 stream 的探索特别多,对流式计算影响巨大。
Flink 的出现也比较久,一直到 2016 年左右才火起来的。Flink 借鉴了很多 Google 的流式计算概念,使得它在市场上特别具
有竞争力。后面我会详细介绍 Flink 的一些特点。
2、批处理与流计算的区别
批处理和流计算有什么样的区别,这是很多同学有疑问的地方。我们知道 MapReduce 是一个批处理引擎,Flink 是一个流处
理引擎。我们从四个方面来进行一下对比:
1)使用场景
MapReduce 是大批量文件处理,这些文件都是 bounded data,也就是说你知道这个文件什么时候会结束。相比而言,Flink
处理的是实时的 unbounded data,数据源源不断,可能永远都不会结束,这就给数据完备性和 failover 带来了很大的挑战。
下载后可阅读完整内容,剩余9页未读,立即下载
2022-03-04 上传
2021-03-05 上传
2021-06-04 上传
2022-11-09 上传
2022-04-29 上传
2021-01-26 上传
2020-09-23 上传
2021-09-26 上传
2024-01-02 上传
2024-11-08 上传

weixin_38678255
- 粉丝: 5
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
