2012 NOI 普及组初赛试题解析
需积分: 11 157 浏览量
更新于2024-08-05
收藏 445KB PDF 举报
"这是2012年全国信息学奥赛初赛试题的资料,主要针对普及组,适合C++编程学习者。试卷涵盖计算机基础知识,包括计算机芯片原料、软件功能识别、市场占有率高的电脑硬件厂商、网络分层模型的解释以及计算机科学中的排序算法、早期计算机类型、递归调用问题和CPU寻址能力等知识点。"
1. 计算机芯片制造的主要原料是(A、硅)。硅是集成电路的基础材料,可以从沙子中提炼出来。
2. 主要用于显示网页服务器或文件系统HTML文件内容,并让用户与文件交互的软件是(B、浏览器)。如Chrome、Firefox等,它们能够解析和渲染HTML内容,实现用户与网页的互动。
3. 目前个人电脑的(B、CPU)市场占有率最靠前的厂商包括Intel和AMD。这两个公司是全球知名的中央处理器制造商。
4. 网络分层模型可以用现实生活的例子来比喻,比如(A、中国公司的经理与法国公司的经理交互商业文件)。这个例子形象地展示了不同层次的角色对应网络中的不同协议层,从数据传输到应用交互。
5. 如果不在快速排序中引入随机化,可能会导致(D、排序时间退化为平方级)。快速排序的平均时间复杂度是O(nlogn),但如果序列已经部分排序,未使用随机化可能导致最坏情况,即时间复杂度退化为O(n^2)。
6. 1946年诞生的ENIAC是(A、电子管)计算机。它是世界上第一台通用电子数字计算机,使用了大量的电子管。
7. 在程序运行中,递归调用层数过多会导致(A、系统分配的栈空间溢出)。因为每次函数调用都会占用栈空间,递归过深会导致栈空间耗尽,引发错误。
8. 地址总线为32位,理论上最大可寻址的内存空间为(4GB)。计算方法是2的32次方,即4,294,967,296字节,通常1字节等于8位,所以是4GB的内存。
这些题目涉及了计算机硬件、操作系统、网络基础、算法以及计算机历史等多个方面的知识,对于准备信息学奥赛或者学习C++编程的学生来说,是很好的练习和复习材料。通过解答这些问题,可以深化对计算机科学基本概念的理解。
第9题 以下不属于目前 3G(第三代移动通信技术)标准的是( )。
A、GSM
B、TD-SCDMA
C、CDMA2000
D、WCDMA
第10题 仿生学的问世开辟了独特的科学技术发展道路。人们研究生物体的结构、功能和工作原理,并将这
些原理移植于新兴的工程技术之中。以下关于仿生学的叙述,错误的是( )。
A、由研究蝙蝠,发明雷达
B、由研究蜘蛛网,发明因特网
C、由研究海豚,发明声纳
D、由研究电鱼,发明伏特电池
第11题 如果对于所有规模为 的输入,一个算法均恰好进行( )次运算,我们可以说该算法的时间复杂度
为 。
A、
B、
C、
D、
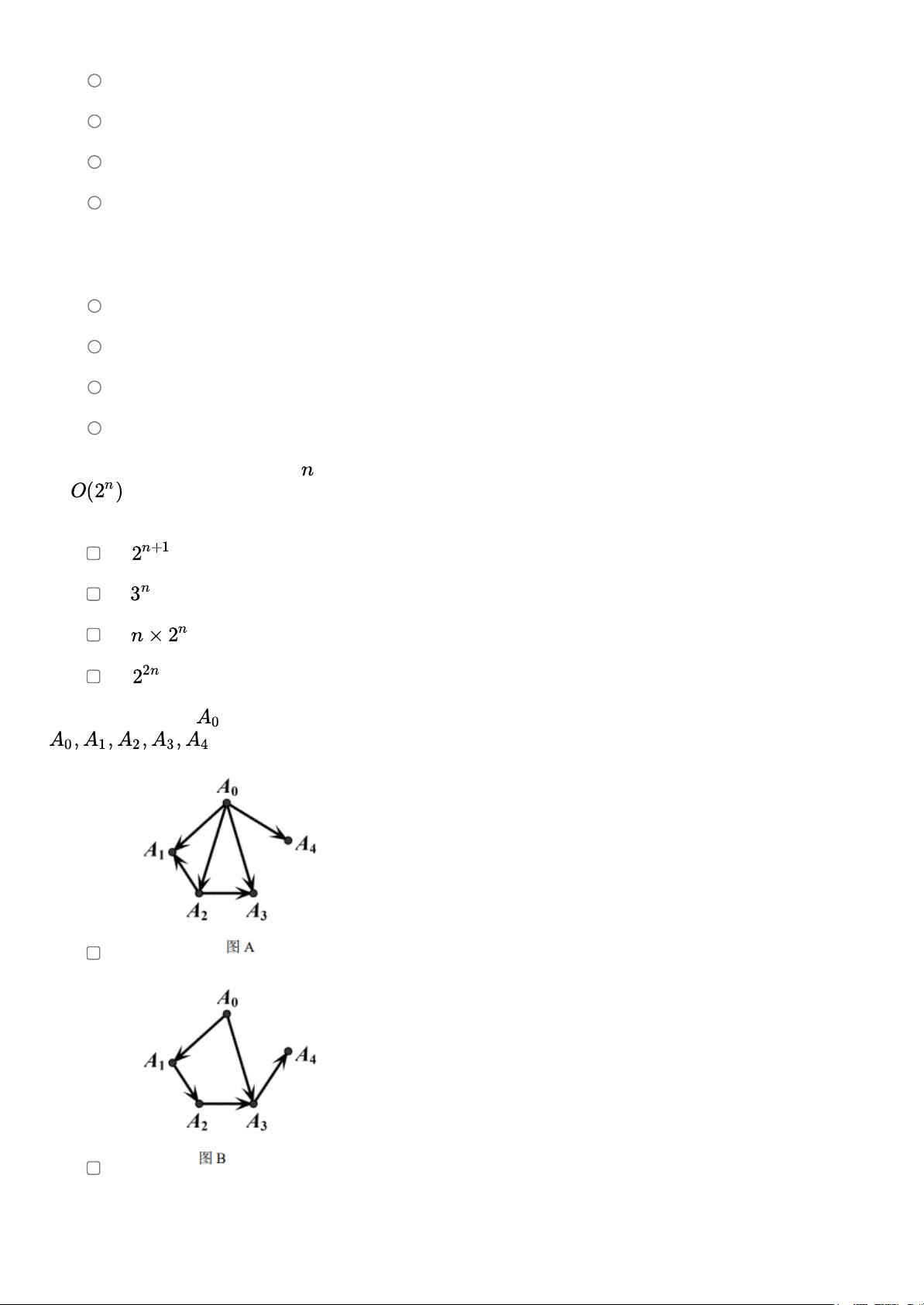
第12题 从顶点 出发,对有向图( )进行广度优先搜索(BFS)时,一种可能的遍历顺序是
。
A、
B、
n
O
( )
2
n
2
n
+1
3
n
n
×
2
n
2
2
n
A
0
, , , ,
A
0
A
1
A
2
A
3
A
4
剩余12页未读,继续阅读
2012-06-22 上传
2021-08-12 上传
2023-04-20 上传
2023-05-15 上传
2021-10-11 上传
2023-06-12 上传
2022-10-24 上传
2022-10-01 上传
2012-10-30 上传

xiongqiam
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
