YOLO系列论文解析:从v1到PP-YOLOE的演进
需积分: 5 72 浏览量
更新于2024-06-19
收藏 6.22MB PPTX 举报
本文将对YOLO系列的目标检测算法进行深度解读,涵盖从YOLOv1到YOLOv4,以及PP-YOLO、PP-YOLOv2、YOLOR、YOLOX、YOLOv7、YOLOv6和PP-YOLOE等重要改进版本。
YOLO(You Only Look Once)是一种实时目标检测系统,它通过将目标检测问题转化为单一的回归问题,实现了快速而准确的检测。YOLO的核心思想是将输入图像划分为网格,每个网格负责预测出其覆盖区域内的物体边界框和类别概率。这种方法相比R-CNN系列方法(如Selective Search、Fast R-CNN和Faster R-CNN)显著提升了速度,因为R-CNN需要先生成候选区域,再进行分类和定位,而YOLO则直接从全图预测。
YOLOv1于2016年5月发布,其关键创新点包括:
1. 输入图像尺寸调整为448×448像素。
2. 使用单个卷积神经网络(CNN)处理整个图像。
3. 采用非极大值抑制(NMS)去除低置信度的检测结果。
4. 每个网格单元预测B个边界框,每个框包含5个预测值(中心坐标x, y,宽度w,高度h和置信度),以及C个类别的概率。
5. 置信度计算基于边界框与真实框的IoU交并比。
6. 损失函数使用平方和误差,并对边界框的宽和高预测采用平方根,以减小大偏差的影响。
YOLOv2在2016年12月推出,主要改进了以下几点:
1. 更好的基础网络结构,如Darknet-19。
2. 引入了 anchor boxes(预定义的边界框比例和大小)以减少定位错误。
3. 使用Batch Normalization加速收敛和提高准确性。
4. 混合不同尺度的特征层进行预测,提高小目标检测性能。
5. 利用多任务学习,将类别的分类损失与定位损失结合。
6. 使用空间金字塔池化(Spatial Pyramid Pooling)以适应不同尺度的目标。
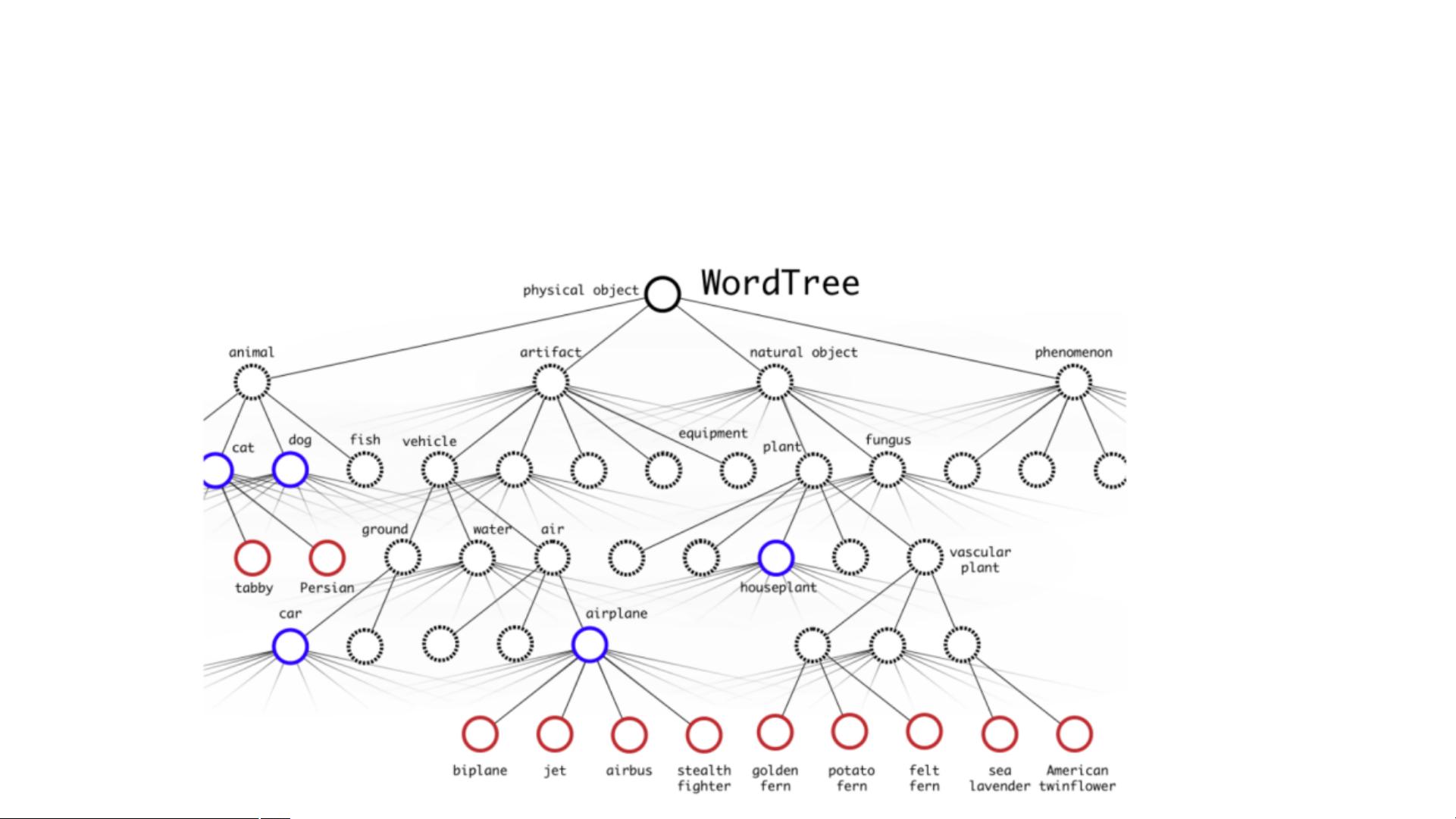
7. 在YOLO9000中,通过WordTree结构同时在多个数据集上训练,提升到可以检测9000多种目标。
YOLOv3于2018年4月发布,引入了以下创新:
1. 使用更深层次的网络Darknet-53。
2. 引入了特征金字塔网络(Feature Pyramid Network,FPN),处理不同尺度的目标。
3. 增加了多尺度预测,每个层级预测不同大小的物体。
4. 添加了对象实例分割(通过预测物体掩模)。
5. 引入了残差块来改善模型的训练和性能。
YOLOv4在2020年4月发布,是YOLO系列中性能最优的版本之一,它融合了多个先进的技术,包括:
1. CSPNet结构,减少内部卷积层的冗余。
2. SPP-Block,增强特征提取能力。
3. Mish激活函数,替代ReLU,提供更好的梯度流。
4. 使用数据增强技术,如CutMix和Mosaic,提高模型泛化能力。
5. 优化的anchor box设计。
6. 对损失函数进行了微调,如GIoU损失,改善边界框的精确度。
后续的YOLOv5、YOLOv6、YOLOR、YOLOX等版本继续优化网络架构、训练策略和损失函数,以提升检测速度和精度。例如,PP-YOLO系列是针对PaddlePaddle框架优化的版本,PP-YOLOE则在PP-YOLO基础上进行了更多改进,如使用更高效的网络结构和训练技巧。
YOLO系列的发展历程反映了目标检测领域对速度和准确性的不断追求,每个新版本都在前人的基础上进行优化,以应对更复杂的场景和更高的性能需求。


2023-06-06 上传
2023-05-13 上传
点击了解资源详情
2021-05-06 上传
2023-08-10 上传
2023-04-24 上传
2023-05-12 上传
2023-07-05 上传

怎么全是重名
- 粉丝: 872
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
