支持向量机SVM详解:从入门到精通
"SVM原理入门式介绍"
支持向量机(SVM)是一种监督学习算法,主要用于分类和回归分析。它的核心思想是找到一个最优的决策边界,使得两类样本点被最大程度地分离,同时保持边界尽可能远离最近的样本点,这些最近的样本点被称为支持向量。
1. SVM的基本概念
- 支持向量:在SVM中,最靠近分类边界的样本点被称为支持向量。它们对于构建分类超平面至关重要,因为它们定义了最大间隔。
- 分类超平面:在二维空间中表现为直线,在高维空间中表现为超平面,用来划分不同类别的数据点。
- 最大间隔:SVM的目标是找到一个最大化间隔(margin)的超平面,间隔是分类超平面与最近的支持向量之间的距离。
2. 核函数
- SVM的非线性处理能力来源于核函数。通过核函数,我们可以将原本在低维空间中的非线性可分问题转换到高维空间,使其变得线性可分。常见的核函数有线性核、多项式核、高斯核(RBF)等。
3. 维数灾难与SVM
- 高维数据通常会导致"维数灾难",使得许多算法性能下降。然而,SVM通过核函数巧妙地处理了这个问题,即使在非常高维的空间中,也能有效地找到分类超平面。
4. VC维理论
- VC维(Vapnik-Chervonenkis维度)是衡量模型复杂度的一个指标。它表示模型能完美拟合的数据集的最大规模。VC维越高,模型的复杂度越大,过拟合的风险也越高。
5. 结构风险最小化
- 结构风险最小化是SVM优化的目标,它综合考虑了经验风险(训练集上的误差)和置信风险(泛化误差)。通过控制模型复杂度,SVM试图找到一个在训练集上表现良好且泛化能力强的模型。
6. C参数与软间隔
- 在实际应用中,可能存在一些样本点不能严格满足最大间隔原则,这时引入了C参数,允许一定数量的误分类(即软间隔)。C值越大,对误分类的容忍度越小,模型越趋向于追求最大间隔;C值越小,模型倾向于包容更多的误分类,提高泛化能力。
7. 多分类与一对多策略
- 对于多分类问题,SVM通常采用一对多(one-vs-one 或 one-vs-rest)策略,即构建多个二分类器,每个分类器负责区分一类与其他类。
SVM以其强大的泛化能力和对小样本、非线性、高维数据的良好处理能力,在文本分类、图像识别、生物信息学等领域有着广泛应用。理解并掌握SVM的基本原理和操作方法,对于解决实际问题具有重要的价值。
SVM(Support Vector Machine)
by pbImage 2012-05-08
SVM 在解决小样本,非线性和高维模式识别问题中很好利用,并能够推广应用到函数拟合
等其他机器学习问题中。
小样本,并不是指提供的样本数量绝对的小,只是相对于其他分类器而言,更小;
非线性,指 SVM 可以利用核函数和惩罚因子将非线性分类转换为线性分类问题解决;
高维,主要是指样本数据维数很高,其他算法无法解决,而 SVM 也能够产生很好的分类
器。
SVM 建立在统计学习理论的 VC 维理论和结构风险最小理论上。
1. VC 维
函数类的一种度量,简单理解为问题的复杂度,VC 维越高,问题越复杂。
2. 结构风险最小理论
风险,最简单的理解就是误差,即我们的假设与真实之间的差距。机器学习的目的就是要
找一个对问题最真实的模型逼近,这个逼近就称为假设,因此就必然存在误差,也就是提
出假设的风险。风险越小,表示出我们提出的假设就越接近真实的情况。
风险又可以分为经验风险和置信风险。
经验风险,即使用分类器在已知的样本数据上分类结果与真实的情况之间存在的误差。
置信风险,即我们对分类器在未知实际情况分类的结果信任度。
风险存在这两种的主要原因是,一个分类器可能在已知的样本上,能够很好的找到一个合
适函数,使得分类正确率能达到 100%(完全分类正确),但对于未知的实际情况却一塌糊
涂,这样,我们所求得的分类器基本上没法使用。因此,要使假设越逼近真实情况,就不
仅要经验风险小,更要使置信风险小。经验风险跟提供的已知样本数量相关,而置信风险
不仅跟样本数量有关,还与 VC 维相关,VC 维越大,分类器推广的能力就越差,置信风险
就会变大。
3. 线性分类器
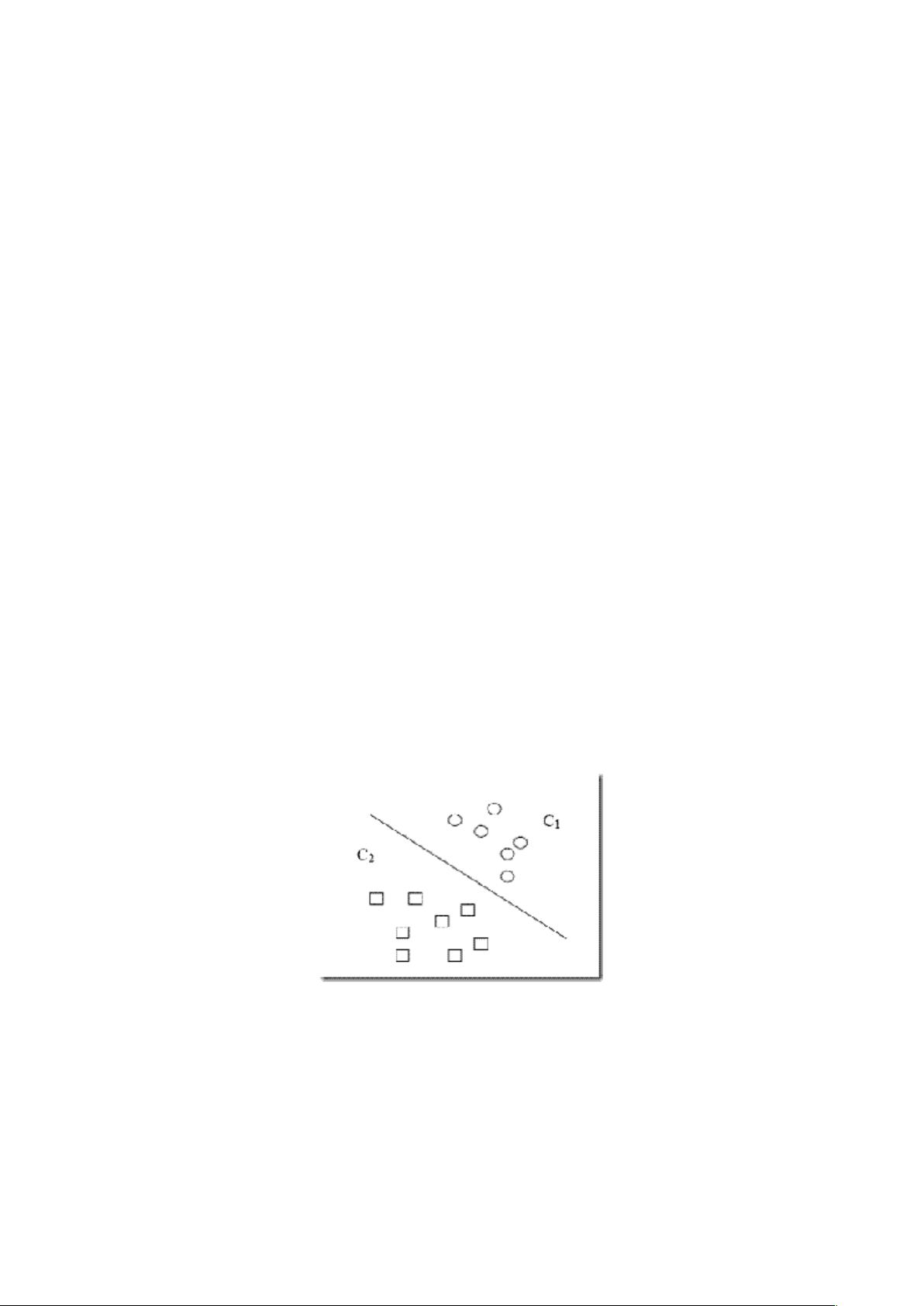
图 1 两类分类问题
C1 和 C2 是两个不同的类(我们提前设定 C1 为正类,C2 为负类)。在二维的空间中,要将 C1 和 C2 两个
不同的类分开,就需要找到如图中这样的直线,使得 C1 类完全在直线上方,C2 类完全在直线下方。
在二维空间中,这样的直线(分类判别函数)当然就可以表示成
g(x)=wx+b
当 g(x)>0 C1 类;
当 g(x)<0 C2 类;
下载后可阅读完整内容,剩余7页未读,立即下载
104 浏览量
155 浏览量
2023-04-26 上传
2023-06-12 上传
2023-07-28 上传
2023-07-29 上传
2023-05-10 上传
2023-10-22 上传
2023-07-09 上传

WTK-CV
- 粉丝: 47
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入理解23种设计模式
- 制作与调试:声控开关电路详解
- 腾讯2008年软件开发笔试题解析
- WebService开发指南:从入门到精通
- 栈数据结构实现的密码设置算法
- 提升逻辑与英语能力:揭秘IBM笔试核心词汇及题型
- SOPC技术探索:理论与实践
- 计算图中节点介数中心性的函数
- 电子元器件详解:电阻、电容、电感与传感器
- MIT经典:统计自然语言处理基础
- CMD命令大全详解与实用指南
- 数据结构复习重点:逻辑结构与存储结构
- ACM算法必读书籍推荐:权威指南与实战解析
- Ubuntu命令行与终端:从Shell到rxvt-unicode
- 深入理解VC_MFC编程:窗口、类、消息处理与绘图
- AT89S52单片机实现的温湿度智能检测与控制系统
